




前言:损失函数是机器学习里最基础也是最为关键的一个要素,通过对损失函数的定义、优化,就可以衍生到我们现在常用的LR等算法中
本文是根据个人自己看的《统计学方法》《斯坦福机器学习课程》及日常工作对其进行的一些总结。因为才疏学浅,如有不对之处,请发邮件指点liedward@qq.com。非常感谢帮忙指正错误。
关键词:损失函数的作用,机器学习.
损失函数的作用:衡量模型模型预测的好坏。
正文:
首先我们假设要预测一个公司某商品的销售量:
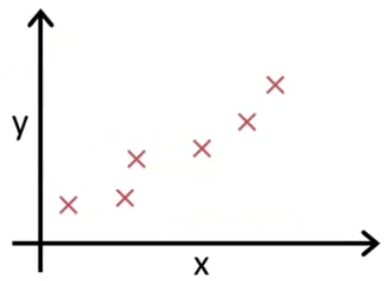
X:门店数 Y:销量
我们会发现销量随着门店数上升而上升。于是我们就想要知道大概门店和销量的关系是怎么样的呢?
我们根据图上的点描述出一条直线:
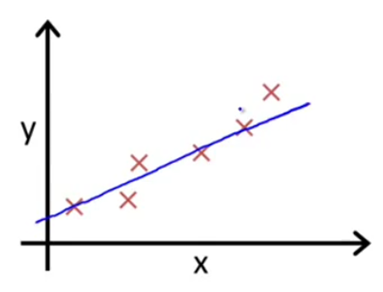
似乎这个直线差不多能说明门店数X和Y得关系了:我们假设直线的方程为Y=a0+a1X(a为常数系数)。假设a0=10 a1=3 那么Y=10+3X(公式1)
| X |
公式Y |
实际Y |
差值 |
| 1 |
13 |
1 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 824
824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









