









算法介绍
KNN分类算法应该是最容易理解的机器学习算法了。它是惰性学习法的一种,它并不从训练数据集中得到一个分类模型,而是简单的存储这些训练数据,当一个待分类数据X到来时,它计算X和训练数据集中所有数据的距离,然后选择离X最近的k个数据,这k个数据称为X的k最近邻,并把这k个数据中出现次数最多的类别赋给X。
KNN分类算法有两个比较关键的地方需要注意:
(1)两个数据之间距离的计算公式。相似性计算是大多数分类算法的核心,但是对KNN来说,几乎是它的全部,直接影响到分类的准确性。具体可参考《数据挖掘概念与技术》第三版2.4节。
(2)k值选择。对于一个数据对象,选择不同的k值时,可能会被分到不同的类别,如下图:
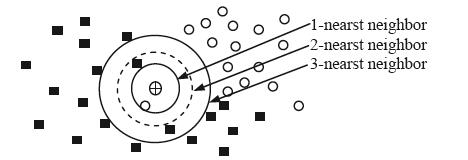
图中实心行块表示正例,空心圆圈表示负例。如果k=1,待分类对象被分为负例;如果k=2,无法对待分类对象进行分类;如果k=3,待分类对象被分为正例。可以通过在训练集上选择不同的k值对测试集进行分类,最终选择错误率最小时的k值。
算法优势
KNN算法非常适合并行计算。在Hadoop上,我们可以轻松设计出时间复杂度为O(1)的mapreduce实现。
参考资料:
《Web数据挖掘》第2版,Bing Liu 著, 俞勇 译
《数据挖掘概念与技术》第3版,Jiawei Han,Micheline Kamber,Jian Pei 著,范明,孟小峰 译

















 1199
1199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









