







第六章 信息论
第七节:随机过程——预测未来的数学迷宫
1. 引言
在人工智能的世界里,许多算法和模型的核心都依赖于随机过程的数学原理。无论是时间序列预测、自然语言处理中的生成模型,还是强化学习中的状态转移,随机过程都扮演着至关重要的角色。随机过程不仅帮助我们理解数据的随机性,还提供了如何通过历史数据预测未来的理论框架。
在这一节中,我们将探索随机过程的基础理论,并通过几个实际的AI应用案例,演示如何将这些理论转化为可操作的模型。我们将使用Python代码实现这些案例,以便更好地理解如何将数学原理应用于实际问题。
2. 随机过程的基本概念
随机过程(Stochastic Process)是描述一系列随机变量随时间或空间变化的数学模型。其基本定义是,给定一个时间索引集合T(通常是时间),随机过程是一个从时间集T到某个状态空间(通常是实数空间)的一族随机变量的集合。
形式上,随机过程 X(t) 可以表示为:
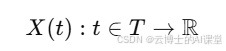
其中,t 是时间或空间的索引,X(t) 是在时刻 t 上的随机变量。
在AI应用中,最常见的随机过程类型包括:
- 马尔可夫过程:当前状态仅依赖于前一个状态,与过去的其他状态无关。
- 高斯过程:所有状态变量的联合分布是多维正态分布,广泛应用于机器学习中的回归任务。
- 泊松过程:用于建模事件在某一时间段内的发生频率,尤其适合描述稀疏事件的发生。
3. 随机过程在AI中的应用
3.1 时间序列预测:股市价格预测
股市价格变化是一个典型的随机过程,投资者试图预测未来价格趋势以获得收益。我们将采用马尔可夫过程建模股市价格的变化。
3.1.1 数学背景
马尔可夫过程的核心思想是,当前的状态(股市价格)只与上一个状态(前一天的股市价格)有关。通过这个假设,我们可以使用一个状态转移矩阵来描述股市价格的变化。
3.1.2 Python实现
import numpy as np
import matplotlib.pyplot as plt
# 模拟股市价格变化的马尔可夫链
states = ['上涨', '下跌', '持平']
transition_matrix = np.array([
[0.6, 0.3, 0.1], # 当前上涨的概率
[0.2, 0.7, 0.1], # 当前下跌的概率
[0.3, 0.4, 0.3] # 当前持平的概率
])
# 初始状态:上涨
current_state = 0
n_steps = 100
history = [current_state]
# 进行n_steps的模拟
for _ in range(n_steps):
current_state = np.random.choice([0, 1, 2], p=transition_matrix[current_state])
history.append(current_state)
# 显示模拟结果
history = np.array(history)
plt.plot(history, label='股市状态')
plt.title("股市价格的马尔可夫过程模拟")
plt.xlabel("时间")
plt.ylabel("状态")
plt.show()
通过这个简单的模拟,我们可以预测未来股市的状态变化。然而,实际的股市预测涉及更多复杂的因素,并且可能无法完全遵循马尔可夫过程的假设。
3.2 高斯过程回归:房价预测
高斯过程(Gaussian Process, GP)是一种强大的非参数贝叶斯模型,广泛应用于回归问题,尤其是在数据稀疏的情况下。
3.2.1 数学背景
高斯过程回归假设数据是从一个高斯过程生成的。给定输入X={x1,x2,…,xn},目标值Y={y1,y2,…,yn},我们可以通过构造一个协方差矩阵来描述这些数据的关系。
3.2.2 Python实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF, ConstantKernel as C
# 创建一个简单的房价数据集
X_train = np.array([[1], [2], [3], [4], [5], [6]])
y_train = np.array([100, 150, 200, 250, 300, 350])
# 定义核函数:RBF核
kernel = C(1.0, (1e-4, 1e1)) * RBF(1.0, (1e-4, 1e1))
# 创建高斯过程回归模型
gp = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=10)
# 拟合数据
gp.fit(X_train, y_train)
# 生成预测数据
X_test = np.linspace(0, 7, 1000).reshape(-1, 1)
y_pred, sigma = gp.predict(X_test, return_std=True)
# 绘制结果
plt.plot(X_train, y_train, 'or')
plt.plot(X_test, y_pred, '-', color='blue')
plt.fill_between(X_test.flatten(), y_pred - 1.96*sigma, y_pred + 1.96*sigma, alpha=0.2, color='blue')
plt.title("高斯过程回归 - 房价预测")
plt.xlabel("房屋面积")
plt.ylabel("房价")
plt.show()
该代码使用高斯过程回归模型拟合房价预测,展示了如何通过不确定性量化预测的可信度。
3.3 强化学习:马尔可夫决策过程
强化学习中的许多算法依赖于马尔可夫决策过程(MDP),它是一个在时间步长中转移的随机过程,其中每个状态都伴随着一个决策和一个奖励。
3.3.1 数学背景
在马尔可夫决策过程中,智能体在每个时间步骤都根据当前状态 sts_t 选择一个动作 ata_t,然后根据环境的状态转移函数和奖励函数进行更新。
3.3.2 Python实现(Q-learning)
import numpy as np
import random
# 环境设定
n_states = 5
n_actions = 2
Q = np.zeros((n_states, n_actions)) # 初始化Q值
# 假设的状态转移和奖励函数
transition_matrix = [
[1, 2], # 从状态0可以转到状态1或状态2
[2, 3], # 从状态1可以转到状态2或状态3
[3, 4], # 从状态2可以转到状态3或状态4
[4, 0], # 从状态3可以转到状态4或状态0
[0, 1] # 从状态4可以转到状态0或状态1
]
reward_matrix = [-1, -1, -1, -1, 0] # 奖励函数,最终状态是0
# Q-learning参数
learning_rate = 0.1
discount_factor = 0.9
episodes = 1000
# Q-learning算法
for _ in range(episodes):
state = random.randint(0, n_states-1) # 随机选择初始状态
while state != 4: # 直到达到最终状态
action = np.argmax(Q[state]) if random.random() > 0.1 else random.randint(0, n_actions-1) # 贪心策略
next_state = transition_matrix[state][action]
reward = reward_matrix[next_state]
Q[state, action] = Q[state, action] + learning_rate * (reward + discount_factor * np.max(Q[next_state]) - Q[state, action])
state = next_state
# 输出Q值矩阵
print("Q值矩阵:")
print(Q)
这个简化的Q-learning例子展示了如何通过随机过程来建模强化学习中的决策过程。通过训练,智能体学会了在不同状态下选择最佳动作。
3.4 排队理论:客户服务系统
排队理论是一类随机过程,广泛应用于电信、网络通信、交通流量等领域。在人工智能中,尤其是在服务优化、流量预测等问题中有广泛应用。
3.4.1 数学背景
排队系统通常使用泊松过程来建模客户到达时间和服务时间。最常见的模型是M/M/1队列,其中“M”表示泊松到达和指数服务时间。
3.4.2 Python实现(M/M/1 排队系统模拟)
import numpy as np
import matplotlib.pyplot as plt
# 模拟M/M/1排队系统
def mm1_queue(arrival_rate, service_rate, max_time=1000):
queue = [] # 用来记录队列中的客户
server_busy_until = 0 # 服务器空闲时刻
waiting_times = [] # 客户等待的时间
current_time = 0 # 当前时间
while current_time < max_time:
# 客户到达时间,使用泊松分布生成
inter_arrival_time = np.random.exponential(1 / arrival_rate)
next_arrival_time = current_time + inter_arrival_time
# 服务时间,使用指数分布生成
service_time = np.random.exponential(1 / service_rate)
if next_arrival_time <= server_busy_until:
# 如果客户到达时服务器忙碌,客户需要等待
waiting_time = server_busy_until - next_arrival_time
queue.append((next_arrival_time, waiting_time))
waiting_times.append(waiting_time)
server_busy_until += service_time # 更新服务器空闲时刻
else:
# 如果客户到达时服务器空闲,不需要等待
queue.append((next_arrival_time, 0))
waiting_times.append(0)
server_busy_until = next_arrival_time + service_time # 更新服务器空闲时刻
current_time = next_arrival_time
return waiting_times
# 设置到达率和服务率
arrival_rate = 0.5 # 客户到达率(每单位时间)
service_rate = 1.0 # 服务器服务率(每单位时间)
# 运行模拟
waiting_times = mm1_queue(arrival_rate, service_rate)
# 绘制结果
plt.hist(waiting_times, bins=30, alpha=0.7, color='blue', edgecolor='black')
plt.title("M/M/1 排队系统 - 客户等待时间分布")
plt.xlabel("等待时间")
plt.ylabel("客户数量")
plt.show()
# 输出等待时间的基本统计信息
print(f"平均等待时间:{np.mean(waiting_times):.2f}")
print(f"最大等待时间:{np.max(waiting_times):.2f}")
在这个模拟中,我们利用泊松分布模拟客户的到达时间,指数分布模拟服务时间。通过这种方式,我们可以评估不同系统参数下(到达率和服务率)客户的等待时间分布,并进行优化分析。这个模型在网络流量、客服中心排队优化等实际问题中有广泛的应用。
3.5 异常检测:基于随机过程的时间序列分析
在很多实际应用中,我们需要监测和检测异常事件的发生,比如网络入侵检测、设备故障预测等。通过将数据建模为一个随机过程,我们可以检测到哪些时刻的数据偏离了预期的行为模式。
3.5.1 数学背景
时间序列数据可以建模为一个随机过程,通常采用自回归(AR)模型、移动平均(MA)模型或者ARMA模型来捕捉数据中的依赖关系。通过计算预测误差,我们可以识别异常点。
3.5.2 Python实现(基于AR模型的异常检测)
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.ar_model import AutoReg
# 生成一个简单的时间序列数据
np.random.seed(42)
n_points = 100
data = np.random.randn(n_points) * 0.5 # 正常的数据波动
data[50] += 5 # 人为引入一个异常点
# 拟合自回归模型(AR)
model = AutoReg(data, lags=5)
model_fitted = model.fit()
# 预测并计算残差
predictions = model_fitted.predict(start=5, end=n_points-1)
residuals = data[5:] - predictions
# 判断是否有异常点(例如,残差大于某个阈值)
threshold = 2 # 设定一个阈值
anomalies = np.where(np.abs(residuals) > threshold)[0]
# 绘制数据及异常点
plt.plot(data, label="原始数据")
plt.plot(range(5, n_points), predictions, label="AR模型预测", linestyle="--")
plt.scatter(anomalies + 5, data[anomalies + 5], color='red', label='异常点')
plt.title("基于AR模型的异常检测")
plt.legend()
plt.show()
在这个案例中,我们通过自回归模型(AR)对时间序列数据进行建模,并通过计算模型预测值与实际值之间的残差来识别异常点。当残差超出设定的阈值时,我们认为该点为异常。这个方法广泛应用于金融市场的风险管理、传感器数据的异常检测等领域。
4. 小结
随机过程为人工智能的多个领域提供了强大的理论支持。在这一节中,我们展示了几个与随机过程相关的实际应用案例,包括股市预测、房价回归、强化学习、排队理论和异常检测等。每个案例不仅介绍了相应的数学模型和理论背景,还通过Python代码进行了实现。这些例子展示了如何在实际应用中利用随机过程的理论来解决问题,提升预测准确性和系统效率。
随机过程为我们提供了分析和处理随机性的不确定性的重要工具,而随着AI技术的进一步发展,理解和掌握随机过程的数学基础将变得越来越重要。通过不断深入研究这些理论和模型,AI领域的研究者和工程师能够更好地应对复杂问题,优化系统性能,并推动AI技术的实际应用。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









