







第七章 数值计算与优化
第6节 经典重现:牛顿法在现代优化中的应用
牛顿法(Newton's Method)是求解非线性方程和优化问题中非常经典且强大的数值计算方法。其核心思想是通过二阶导数信息(即海森矩阵)来加速收敛,尤其在目标函数的梯度接近零时,相较于简单的梯度下降,牛顿法具有更快的收敛速度。然而,牛顿法也有其局限性,比如计算海森矩阵需要较高的计算成本,因此在某些大型问题中不适用。因此,在现代优化中,牛顿法被广泛应用于高效问题求解、精确拟合以及在更复杂的优化算法中(如拟牛顿法)得到变种和改进。
在本节中,我们将通过三个实际案例来详细探讨牛顿法在现代AI应用中的实际作用和技巧。
案例 1: 单变量函数的优化
案例描述
我们首先从最简单的单变量函数优化开始,考虑以下二次函数:
f(x) = x^2 - 4x + 4
这是一个简单的凸函数,我们的目标是找到该函数的最小值。
案例分析

算法步骤

Python代码实现
import numpy as np
import matplotlib.pyplot as plt
# 定义函数及其梯度和二阶导数
def f(x):
return x**2 - 4*x + 4
def grad_f(x):
return 2*x - 4
def hess_f(x):
return 2
# 牛顿法
def newton_method(f, grad_f, hess_f, x0, tol=1e-6, max_iter=100):
x = x0
history = [x] # 存储迭代过程中的解
for i in range(max_iter):
grad = grad_f(x)
hess = hess_f(x)
# 牛顿法更新公式
x_new = x - grad / hess
history.append(x_new)
if abs(x_new - x) < tol:
break
x = x_new
return x, np.array(history)
# 初始猜测
x0 = 0.0
# 使用牛顿法优化
optimal_x, history = newton_method(f, grad_f, hess_f, x0)
# 打印结果
print(f"Optimal x: {optimal_x}")
# 绘制迭代过程
x_vals = np.linspace(-2, 6, 400)
y_vals = f(x_vals)
plt.plot(x_vals, y_vals, label="f(x) = x^2 - 4x + 4")
plt.scatter(history, f(history), color='red', label="Iterations", zorder=5)
plt.legend()
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title('Newton Method Optimization')
plt.grid(True)
plt.show()
代码详解
- 函数定义:我们定义了目标函数 f(x) = x^2 - 4x + 4 及其一阶导数(梯度)和二阶导数(海森矩阵)。
- 牛顿法实现:
newton_method函数根据牛顿法公式迭代计算,直到达到收敛条件或达到最大迭代次数。每一步都会记录当前解,便于绘图展示。 - 结果:通过图形展示了牛顿法的迭代过程,并快速收敛到最优解 x=2。
案例 2: 多变量函数的最优化
案例描述
现在,我们转向一个更复杂的优化问题:多变量函数的最优化问题。假设我们有以下的目标函数:
f(x, y) = x^2 + y^2 - 4x - 6y + 13
该函数的最小值可以通过牛顿法来求解。
案例分析

算法步骤

Python代码实现
# 定义函数及其梯度和海森矩阵
def f_2d(x, y):
return x**2 + y**2 - 4*x - 6*y + 13
def grad_f_2d(x, y):
return np.array([2*x - 4, 2*y - 6])
def hess_f_2d(x, y):
return np.array([[2, 0], [0, 2]])
# 牛顿法(多变量)
def newton_method_2d(f, grad_f, hess_f, x0, y0, tol=1e-6, max_iter=100):
x, y = x0, y0
history = [(x, y)] # 存储迭代过程中的解
for i in range(max_iter):
grad = grad_f(x, y)
hess = hess_f(x, y)
# 求解牛顿法的更新步
delta = np.linalg.solve(hess, grad)
x_new, y_new = np.array([x, y]) - delta
history.append((x_new, y_new))
if np.linalg.norm(delta) < tol:
break
x, y = x_new, y_new
return (x, y), np.array(history)
# 初始猜测
x0, y0 = 0.0, 0.0
# 使用牛顿法优化
optimal_xy, history_2d = newton_method_2d(f_2d, grad_f_2d, hess_f_2d, x0, y0)
# 打印结果
print(f"Optimal (x, y): {optimal_xy}")
# 绘制迭代过程
history_2d = np.array(history_2d)
plt.plot(history_2d[:, 0], history_2d[:, 1], marker='o', color='red')
plt.scatter(2, 3, color='blue', label="Optimal Point (2, 3)", zorder=5)
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.title('Newton Method Optimization (2D)')
plt.grid(True)
plt.show()
代码详解
- 函数定义:我们定义了一个二维目标函数 f(x, y) = x^2 + y^2 - 4x - 6y + 13,并计算了该函数的梯度和海森矩阵。通过这些信息,牛顿法可以高效地更新每次迭代的解。
- 牛顿法实现:
newton_method_2d函数使用海森矩阵的逆和梯度来更新变量 x和 y。np.linalg.solve用来求解线性方程组,这对于大规模优化问题中的性能至关重要。
- 结果:通过绘图,我们可以看到牛顿法如何从初始猜测逐步逼近最优解 (x,y)=(2,3)
案例 3: 神经网络训练中的牛顿法应用
案例描述
神经网络的训练通常使用梯度下降法来优化损失函数。然而,牛顿法的高效性使其在一些高精度要求或小数据集的任务中得到应用,尤其是在不依赖大数据时,牛顿法可以在收敛速度上优于梯度下降法。
假设我们有一个简单的神经网络,其损失函数为均方误差(MSE):

为了利用牛顿法来优化该问题,我们需要计算损失函数的梯度和海森矩阵。梯度下降法基于一阶导数,而牛顿法则使用二阶导数来加速收敛。
案例分析
在神经网络训练中,梯度和海森矩阵的计算比较复杂,但牛顿法的优势在于更快的收敛。对于神经网络的优化问题,牛顿法的计算量较大,通常需要通过迭代求解海森矩阵和梯度,但在小规模问题中非常有效。
对于简单的网络(比如一个具有单隐层的前馈网络),我们可以应用牛顿法优化权重。由于神经网络的复杂性,计算海森矩阵可能会变得非常昂贵,因此在实践中,我们通常采用“拟牛顿法”(如BFGS)来近似海森矩阵,从而避免直接计算。
算法步骤
- 初始化网络权重。
- 定义损失函数和其梯度。
- 计算损失函数的海森矩阵。
- 使用牛顿法更新网络权重:
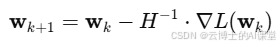
- 重复步骤2至步骤4,直到达到收敛条件。
Python代码实现
import numpy as np
# 激活函数及其导数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_grad(x):
return sigmoid(x) * (1 - sigmoid(x))
# 定义网络前向传播
def forward(x, w):
return sigmoid(np.dot(x, w))
# 定义均方误差损失函数及其梯度
def mse_loss(y_true, y_pred):
return np.mean((y_true - y_pred) ** 2)
def grad_mse_loss(y_true, y_pred, x):
return -2 * np.dot(x.T, (y_true - y_pred)) / len(y_true)
# 构造海森矩阵(Hessian Matrix)
def hessian_mse_loss(x, y_pred):
s = sigmoid_grad(np.dot(x, w)) # 对sigmoid的输入求梯度
hessian = np.dot(x.T, s * (1 - s) * x) / len(x)
return hessian
# 训练数据生成(模拟数据)
np.random.seed(42)
X = np.random.randn(100, 3) # 100个样本,3个特征
y = np.random.randn(100, 1) # 100个目标值
# 初始化权重
w_init = np.random.randn(3, 1)
# 牛顿法训练网络
def newton_method_nn(X, y, w_init, max_iter=100, tol=1e-6):
w = w_init
history = [w]
for i in range(max_iter):
# 前向传播
y_pred = forward(X, w)
# 计算梯度
grad = grad_mse_loss(y, y_pred, X)
# 计算海森矩阵
H = hessian_mse_loss(X, y_pred)
# 牛顿法更新权重
delta_w = np.linalg.solve(H, grad) # 解线性方程 H * delta_w = grad
w_new = w - delta_w
history.append(w_new)
# 收敛检查
if np.linalg.norm(delta_w) < tol:
break
w = w_new
return w, np.array(history)
# 使用牛顿法优化
optimal_w, history_nn = newton_method_nn(X, y, w_init)
# 打印结果
print("Optimal weights:", optimal_w)
# 绘制损失随迭代变化(假设可以计算损失值)
loss_history = [mse_loss(y, forward(X, w)) for w in history_nn]
import matplotlib.pyplot as plt
plt.plot(loss_history)
plt.xlabel("Iterations")
plt.ylabel("MSE Loss")
plt.title("Newton Method for Neural Network Optimization")
plt.grid(True)
plt.show()
代码详解
- 激活函数和前向传播:我们使用Sigmoid激活函数,并定义了前向传播过程。
- 损失函数及其梯度:定义了均方误差(MSE)损失函数以及梯度。
- 海森矩阵:通过计算Sigmoid函数的导数来构造海森矩阵。注意在神经网络中,计算海森矩阵通常是昂贵的,因此需要谨慎处理。
- 牛顿法训练:使用牛顿法优化神经网络的权重。在每次迭代中,我们计算梯度和海森矩阵,使用线性方程求解来更新权重。
- 损失绘图:通过绘图观察损失函数在迭代中的变化情况,可以看到牛顿法如何加速收敛。
小结
在本节中,我们展示了牛顿法在多种AI优化任务中的应用:从简单的单变量优化到多变量优化,再到神经网络中的应用。尽管牛顿法在计算上有一定的复杂性,尤其是在大规模问题中,但它的收敛速度和精度使得它在一些特定的任务中非常有效。尤其在小数据集、简单神经网络等场景下,牛顿法能够显著提高优化效率。
通过这些案例,读者可以更深入地理解牛顿法的理论基础和在实际应用中的优势与局限。对于大规模问题,使用牛顿法的近似方法(如拟牛顿法)可以在保证效率的同时减小计算成本。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









