








第3节 CNN关键技术与优化
在上一节中,我们深入剖析了卷积神经网络(Convolutional Neural Network, CNN)的基本架构和核心组件,包括卷积层、池化层和全连接层。CNN能够自动提取多层次特征,在图像处理任务中表现出色。然而,随着网络层数的增加和任务复杂度的提高,CNN的训练和优化变得愈加重要。本节将重点介绍CNN的关键技术,包括权重初始化、正则化、归一化、优化算法、数据增强、迁移学习等,从理论到实践全面提升CNN的性能。
3.1 CNN的训练挑战
在训练深度CNN时,我们可能会遇到以下几个关键挑战:
- 梯度消失与梯度爆炸:随着网络层数增加,梯度在反向传播过程中可能变得极小(梯度消失)或极大(梯度爆炸),导致权重更新异常。
- 过拟合问题:CNN模型拥有大量参数,容易在训练集上表现良好,但在测试集上泛化能力不足。
- 计算资源消耗大:深度CNN训练通常需要大量数据和计算资源,特别是在大规模数据集上训练时,计算成本极高。
- 训练不稳定:优化过程中可能出现收敛慢、震荡或陷入局部最优等问题。
- 数据不足:深度模型需要大量数据进行训练,但在许多应用场景下,获取标注数据的成本较高,影响CNN的学习效果。
为了解决这些问题,研究者提出了一系列优化策略,我们将在接下来的小节中详细讲解。
3.2 权重初始化
权重初始化对于CNN的稳定训练至关重要,合适的初始化策略可以有效缓解梯度消失或爆炸的问题。
3.2.1 随机初始化
最简单的方法是使用小随机值初始化权重:
- 均匀分布随机初始化:权重从[−a,a]范围内均匀随机采样。
- 正态分布随机初始化:权重从均值为0、方差较小的正态分布中采样。
然而,这种方式容易导致梯度消失或梯度爆炸,特别是对于深度网络。
3.2.2 Xavier 初始化(Glorot Initialization)
Xavier初始化(Glorot & Bengio, 2010)根据网络输入和输出的节点数调整权重初始值:
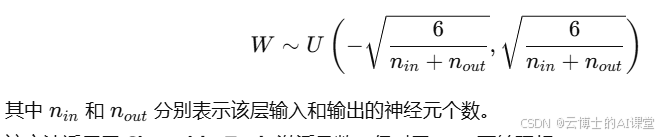
该方法适用于 Sigmoid、Tanh 激活函数,但对于ReLU不够理想。
3.2.3 He 初始化(Kaiming Initialization)
针对ReLU激活函数,He等人在2015年提出了更适合的方法:
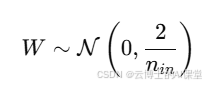
He初始化可以保持ReLU激活的输入分布稳定,避免梯度消失问题,因而成为深度CNN的主流初始化方法。
3.3 归一化技术
在深度CNN中,归一化(Normalization)可以有效地稳定训练,提高模型收敛速度,缓解梯度消失问题。以下是常见的归一化方法:
3.3.1 批量归一化(Batch Normalization, BN)
BN(Ioffe & Szegedy, 2015)通过对每个小批量(Mini-batch)的输入进行归一化,使其均值为0,方差为1:

优点:
- 使梯度分布更稳定,加速训练。
- 允许更大的学习率,提高模型泛化能力。
- 缓解梯度消失问题,使得网络可以训练更深。
3.3.2 层归一化(Layer Normalization, LN)
LN(Ba et al., 2016)是BN的改进版本,不依赖小批量数据,而是在每个样本的特征维度进行归一化,适用于RNN等不固定批次大小的网络。
3.3.3 组归一化(Group Normalization, GN)
GN(Wu & He, 2018)针对BN在小批量数据上的问题,将特征图划分为若干组,分别归一化,适用于小批量训练场景,如目标检测等。
3.4 正则化与防止过拟合
深度CNN容易过拟合,以下几种正则化技术可以有效提高模型的泛化能力。
3.4.1 L1/L2 正则化
- L1正则化(Lasso):添加权重绝对值的惩罚项,能产生稀疏权重,有助于特征选择。
- L2正则化(Ridge):添加权重平方的惩罚项,有效防止过拟合,深度CNN中常用。
3.4.2 Dropout
Dropout(Srivastava et al., 2014)是一种随机失活策略,在训练过程中随机丢弃一部分神经元,防止神经元对训练数据的过拟合。
3.4.3 数据增强
数据增强(Data Augmentation)通过增加训练数据的多样性,提高模型泛化能力。例如:
- 图像变换(旋转、翻转、缩放、剪切)
- 颜色变换(亮度、对比度、色相调整)
- Cutout、Mixup、CutMix(增强鲁棒性)
3.5 先进的优化算法
在深度学习中,优化算法决定了训练的收敛速度和稳定性。
3.5.1 自适应学习率优化
- SGD(Stochastic Gradient Descent):随机梯度下降法,学习率固定,难以调优。
- Momentum SGD:引入动量项,加速收敛。
- Adam(Adaptive Moment Estimation):结合Momentum和RMSProp,学习率自适应调整,适用于大多数CNN任务。
3.5.2 学习率调度
- Step Decay:固定步长衰减。
- Exponential Decay:指数级减少学习率。
- Cosine Annealing:余弦退火策略,适用于大规模训练。
3.6 迁移学习
迁移学习(Transfer Learning)利用已有的预训练模型(如ResNet、VGG、EfficientNet)进行微调,可以在小数据集上取得良好效果。常见方法:
- 微调(Fine-tuning):冻结前几层,仅更新后几层权重。
- 特征提取(Feature Extraction):固定整个预训练模型,仅作为特征提取器使用。
3.7 小结
本节介绍了CNN的关键技术和优化策略,包括权重初始化、归一化、正则化、优化算法和迁移学习等。掌握这些技巧可以帮助我们在实际应用中训练更稳定、更高效、更具泛化能力的CNN模型。下一节,我们将深入讨论CNN的经典架构(如LeNet、AlexNet、VGG、ResNet等)及其演进,带领读者进入更高级的CNN设计领域。
【哈佛博后带小白玩转机器学习】 哔哩哔哩_bilibili
总课时超400+,时长75+小时



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









