







MySQL笔记
SQL语言介绍
-
SQL语句概念
1.SQL全称: Structured Query Language,是结构化查询语言,用来访问结构化数据(类似Excel文本数据) 2.SQL用来操作数据库系统 3.SQL发展到现在,制定了很多的标准,有:SQL-92、SQL-99标准,不同的标准表达方式不同 -
SQL语言的分类
数据定义语言-DDL (create/drop/show) 数据操作语言-DML (insert/delete/update) 数据查询语言-DQL (select/group by/order by) !!!!!!! 数据控制语言-DCL -
SQL语法特点
SQL 对关键字的大小写不敏感 SQL语句可以以单行或者多行书写,以分行结束 -
SQL的注释
-- 单行注释 # 单行注释 /* 多行注释 多行注释 多行注释 多行注释 */
数据库系统
关系型数据库
-
介绍
关系型数据库最大的特点是:数据库中存储的是一张张的表格,表格与表格之间存在的某种关系 -
分类
1、Oracle数据库 (老大,最挣钱的数据库) 2、MySQL数据库 (最流行中型数据库)) 3、SQL server数据库 (Windows上最好的数据库) 4、PostgreSQL(功能最强大的开源数据库) 5、SQLite(最流行的嵌入式数据库 #黑马的课程设计的数据库:MySQL数据库、Oracle数据库、PostgreSQL数据库
非关系型数据库
-
介绍
菲关系型数据库中存储的是键值对,大部分都不是表 -
分类
1、Redis(最好的缓存数据库) 2、MongoDB(最好的文档型数据库) 3、Elasticsearch(最好的搜索服务) 4、Cassandra(最好的列式数据库) 5、HBase(优秀的分布式、列式数据库) #黑马的课程设计的数据库:Elasticsearch、HBase、MongoDB
SQL和数据库系统的关系
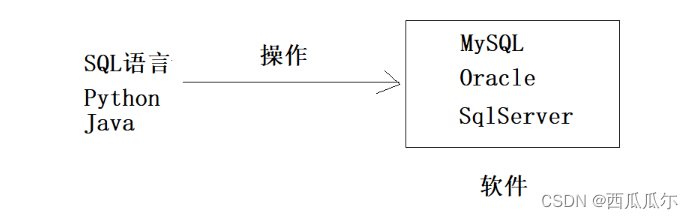
1、SQL是一种用于操作数据库的语言,SQL适用于所有关系型数据库。
2、MySQL、Oracle、SQLServer是一个数据库软件,我们使用SQL可以操作这些软件,不过每一个数据库系统会在标准SQL的基础上扩展自己的SQL语法。
数据库系统架构
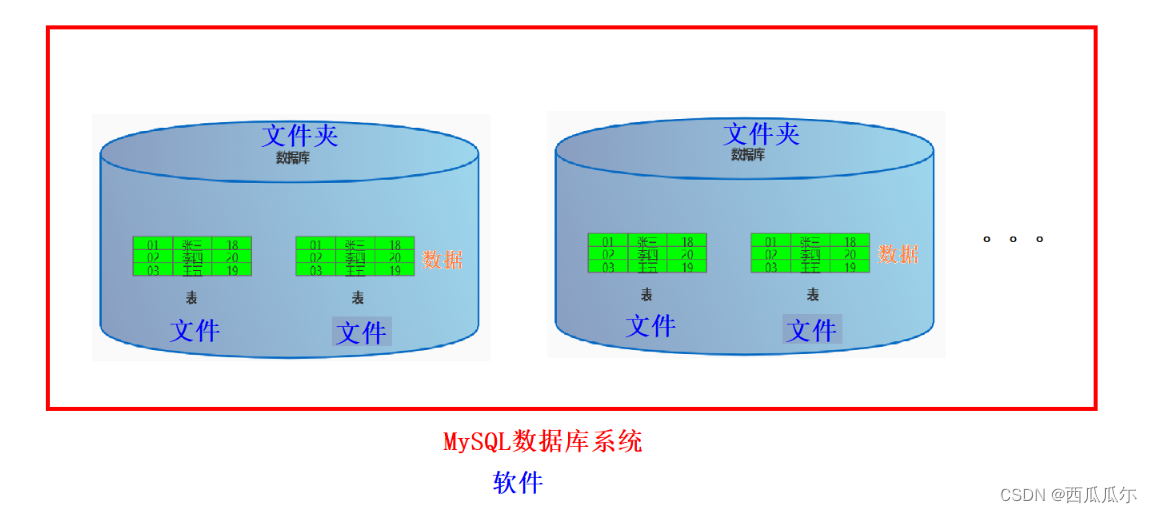
数据库系统 --->数据库 --->表 --->数据
MySQL的介绍
概念
1、MySQL现在归属于Oracle公司(甲骨文)、该公司旗下还有一个Oracle数据库,
2、MySQL底层是C语言
3、MySQL支持多种操作系统,多种编程语言访问()
MySQL的版本
MySQL的经典数字版本: MySQL 8.x 和 MySQL 5.x
可以安装 社区版MySQL 8.x 或者 商业版 MySQL 8.x
MySQL的DDL操作-重点
基本数据库操作
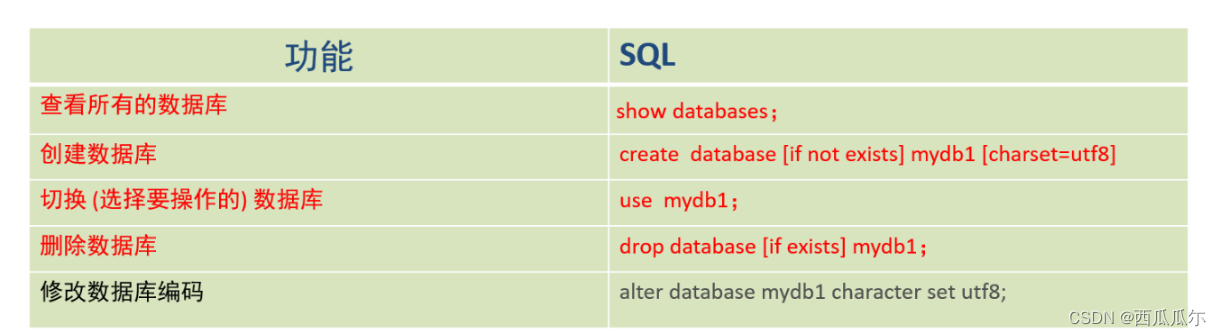
-- 1、查看所有的数据库
show databases ;
-- 2、创建数据库
#不推荐使用以下命令,如果数据库存在,则报错
create database mydb1;
#推荐使用以下命令,如果数据库存在,则什么也不做,如果数据库不存在,则创建
create database if not exists mydb1;
-- 3、选择当前要使用哪个数据库
use mydb1;
-- 4、删除数据库
#以下命令不推荐,因为如果数据库不存在,则报错
drop database mydb1;
#以下命令推荐,因为如果数据库不存在,则什么也不做
drop database if exists mydb1;
-- 5、修改数据库编码
#我们目前的数据库默认就是utf-8编码
-- alter database mydb1 character set utf8;
d=img-5BSVIfZf-1715992255382)
基本表操作
-
数据类型
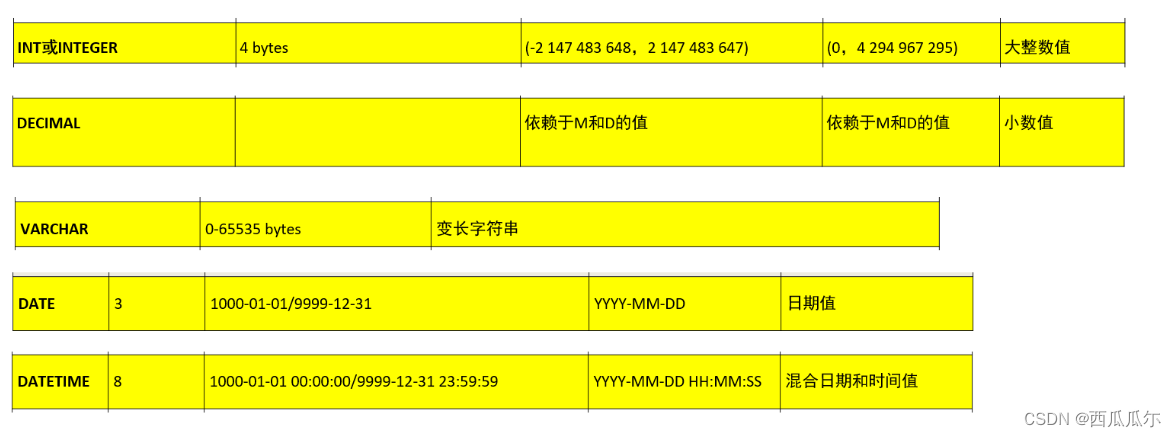
-
创建表语法
create table [if not exists]表名( 字段名1 类型[(宽度)] [约束条件] [comment '字段说明'], 字段名2 类型[(宽度)] [约束条件] [comment '字段说明'], 字段名3 类型[(宽度)] [约束条件] [comment '字段说明'] )[表的一些设置]; -
创建表操作
-- 1、创建学生表 use mydb1; -- comment是给表字段(列)加注释,可以通过表结构查看注释 -- decimal(10,2) :10表示最多是10为有效数字(整数+小数) ,小数保留2位,整数最多是8位 -- 12345678.34 :整数8位 + 小数2位 -- varchar(20) 这里边最多存入20个字符,超过会截断 create table if not exists student2( sid int comment '学生学号', name varchar(20) comment '学生名字', gender varchar(2) comment '学生的性别', age int comment '学生的年龄', birth date comment '学生的生日', -- 2000-12-23 address varchar(50) comment '学生的地址', score decimal(10,2) comment '学生的成绩' ); use mydb1; -- 查看所有的表 show tables ; -- 查看表创建时的sql语句 show create table student2; -- 查看表结构,表字段名字和类型 desc student; -- 删除表 drop table student;
MySQL的DML操作-重点
insert-插入数据
-
语法
insert into 表 (列名1,列名2,列名3...) values (值1,值2,值3...); #向表中插入某些 insert into 表 values (值1,值2,值3...); #向表中插入所有列 -
代码
#------------------DML操作-insert插入数据----------------------- -- 添加一行数据 insert into student(sid,name,gender,age,birth,address,score) values (1,'宝玉','男',19,'2000-12-23','北京',87); -- 添加一行数据 #前边跟几个字段,后边就要跟几个值,类型要相同 insert into student(sid,name,gender) values (2,'黛玉','女'); -- 添加一行数据 # 如果表的后边没有加字段,则values后边需要给所有字段赋值 insert into student values (3,'宝钗','女',16,'2000-12-23','上海',98); -- 添加多行数据 insert into student values (4,'晴雯','女',17,'2002-12-23','深圳',56), (5,'贾琏','男',34,'2023-10-23','广州',98), (6,'贾雨村','男',156,'2008-02-21','杭州',45);
update-更新数据
-
语法
update 表名 set 字段名=值,字段名=值...; update 表名 set 字段名=值,字段名=值... where 条件; -
代码
#------------------DML操作-update更新数据----------------------- -- 将所有学生的地址改为:吉山村 update student set address = '吉山村'; -- 将所有学生的age改为18,score改为100 update student set age = 18,score = 100; -- 将所有学生的age在原来基础加上10岁 update student set age = age + 10 ; -- 将 晴雯 的address改为广州 update student set address = '广州' where name = '晴雯'; update student set address = '广州' where sid = 4;
delete-删除数据
-
语法
delete from 表名 [where 条件]; truncate table 表名 或者 truncate 表名 -
代码
#------------------DML操作-delete删除数据----------------------- -- 删除操作,如果后边不加where条件,则会将该表的所有数据全部删除,比较危险 delete from student ; -- 删除宝玉这个学生 delete from student where name = '宝玉'; -- 清空表的所有内容 #注意:delete和truncate原理不同,delete只删除内容,而truncate类似于drop table ,可以理解为是将整个表删除,然后再创建该表; truncate table student; truncate student; -- 作用同上
MySQL的约束-了解
概述
约束就是给某一列加限制,让该列的值复合某种要求,英文:constraint
约束的分类
主键约束(primary key) PK
自增长约束(auto_increment)
非空约束(not null)
唯一性约束(unique)
默认约束(default)
外键约束(foreign key) FK
主键约束
-
特点
1、MySQL主键约束是一个列或者多个列的组合,其值能唯一地标识表中的每一行,方便在数据库中尽快的找到某一行。 2、主键约束相当于 非空 + 唯一 的组合,主键约束列不允许重复,也不允许出现空值(null值)。 3、每个表最多只允许一个主键 4、主键约束的关键字是:primary key -
语法
#----------------方式1----------------------- -- 在 create table 语句中,通过 PRIMARY KEY 关键字来指定主键。 --在定义字段的同时指定主键,语法格式如下: create table 表名( ... <字段名> <数据类型> primary key ... ) #----------------方式2----------------------- --在定义字段之后再指定主键,语法格式如下: create table 表名( ... primary key(字段名) ); -
代码
#----------------方式1----------------------- drop table if exists student; create table if not exists student( sid int primary key comment '学生学号', # !!!添加主键-sid这一列的值不能为空,而且必须唯一 name varchar(20) comment '学生名字', gender varchar(2) comment '学生的性别', age int comment '学生的年龄', birth date comment '学生的生日', -- 2000-12-23 address varchar(50) comment '学生的地址', score decimal(10,2) comment '学生的成绩' ); #----------------方式2----------------------- drop table if exists student; create table if not exists student( sid int comment '学生学号', name varchar(20) comment '学生名字', gender varchar(2) comment '学生的性别', age int comment '学生的年龄', birth date comment '学生的生日', -- 2000-12-23 address varchar(50) comment '学生的地址', score decimal(10,2) comment '学生的成绩', primary key (sid) # !!!添加主键 ,sid这一列的值不能为空,而且必须唯一 ); # 插入成功 insert into student values (1,'宝钗','女',16,'2000-12-23','上海',98); # 插入失败,因为主键不能重复 insert into student values (1,'宝玉','男',16,'2000-12-23','上海',98); # 插入失败,因为主键不能为空 insert into student values (null,'宝玉','男',16,'2000-12-23','上海',98); # 插入失败,因为主键列没有指定值,默认是null值,则不符合主键的要求 insert into student(name,gender) values ('黛玉','女'); -
删除主键
# 删除主键,但是还剩下一个非空约束 alter table student drop primary key; #再删除非空约束,这样主键的所有影响全部消除 ALTER TABLE student MODIFY sid INT NULL;
自增约束
-
概念
1、在 MySQL 中,当主键定义为自增长后,这个主键的值就不再需要用户输入数据了,而由数据库系统根据定义自动赋值。每增加一条记录,主键就会自动加1 2、自动增长必须要加在主键的后边,加了自动增长之后,该列的值可以自己在每次添加数据时加1 3、自动增长的列默认是1开始增长,每次加1 4、主键列必须是数字列 5、自动增长的关键字:auto_increment -
代码
#------------------DML操作-自动增长----------------------- # 自动增长必须要加在主键的后边,加了自动增长之后,该列的值可以自己在每次添加数据时加1 # 自动增长的列默认是1开始增长,每次加1 # 主键列必须是数字列 drop table if exists student; create table if not exists student( sid int primary key auto_increment, # 给主键添加自增长约束auto_increment name varchar(20) , gender varchar(2) , age int , birth date , address varchar(50) , score decimal(10,2) ); # 你可以执行以下命令多次,发现主键会自增 insert into student values (null,'宝玉','男',16,'2000-12-23','上海',98); # 删除所有数据,主键的历史记录不会被清空,下一次添加依然在之前最大的主键值之上加1 delete from student; # 你可以执行以下命令多次,发现主键会在最大值之上加1 insert into student values (null,'宝玉','男',16,'2000-12-23','上海',98); # 如果你想让主键重新回到1开始自增,则可以使用truncate命令(先删除表,再建表) truncate table student; # 你会发现,主键又从1开始增长 insert into student values (null,'宝玉','男',16,'2000-12-23','上海',98); # 我们也可以设置主键从某个值开始增长 drop table if exists student; create table if not exists student( sid int primary key auto_increment, # 给主键添加自增长约束auto_increment name varchar(20) , gender varchar(2) , age int , birth date , address varchar(50) , score decimal(10,2) )auto_increment = 100; # 我们也可以设置主键从100开始增长 # 插入以下数据,发现主键从100开始,然后依次加1 insert into student values (null,'宝玉','男',16,'2000-12-23','上海',98);
其他约束
create table if not exists student(
sid int primary key auto_increment,
name varchar(20) not null, # 非空约束,该列的值不能为空
gender varchar(2) unique , # 唯一约束,该列的值必须唯一
age int ,
birth date ,
address varchar(50) default '北京', # 默认值约束,该列如果没有给值,则模式是北京
score decimal(10,2)
);
,
score decimal(10,2)
)auto_increment = 100; # 我们也可以设置主键从100开始增长
插入以下数据,发现主键从100开始,然后依次加1
insert into student values (null,‘宝玉’,‘男’,16,‘2000-12-23’,‘上海’,98);
### 其他约束
```sql
create table if not exists student(
sid int primary key auto_increment,
name varchar(20) not null, # 非空约束,该列的值不能为空
gender varchar(2) unique , # 唯一约束,该列的值必须唯一
age int ,
birth date ,
address varchar(50) default '北京', # 默认值约束,该列如果没有给值,则模式是北京
score decimal(10,2)
);
MySQL的DQL操作-重点
语法
-
通用语法
select [all|distinct] <目标列的表达式1> [别名], <目标列的表达式2> [别名]... from <表名或视图名> [别名],<表名或视图名> [别名]... [where<条件表达式>] [group by <列名> [having <条件表达式>]] [order by <列名> [asc|desc]] [limit <数字或者列表>]; -
简化语法
select 字段 from 表 where 条件 # where是用来筛选那些行, select后边是来筛序哪些列
简单查询
-- 创建数据库
create database if not exists mydb2;
use mydb2;
-- 创建商品表:
drop table if exists product;
create table product(
pid int , -- 商品编号
pname varchar(20) not null , -- 商品名字
price double, -- 商品价格
category_id varchar(20) -- 商品所属分类
);
insert into product values(1,'海尔洗衣机',5000,'c001');
insert into product values(2,'美的冰箱',3000,'c001');
insert into product values(3,'格力空调',5000,'c001');
insert into product values(4,'九阳电饭煲',5000,'c001');
insert into product values(5,'啄木鸟衬衣',300,'c002');
insert into product values(6,'恒源祥西裤',800,'c002');
insert into product values(7,'花花公子夹克',440,'c002');
insert into product values(8,'劲霸休闲裤',266,'c002');
insert into product values(9,'海澜之家卫衣',180,'c002');
insert into product values(10,'杰克琼斯运动裤',430,'c002');
insert into product values(11,'兰蔻面霜',300,'c003');
insert into product values(12,'雅诗兰黛精华水',200,'c003');
insert into product values(13,'香奈儿香水',350,'c003');
insert into product values(14,'SK-II神仙水',350,'c003');
insert into product values(14,'SK-II神仙水',350,'c003');
insert into product values(15,'资生堂粉底液',180,'c003');
insert into product values(16,'老北京方便面',56,'c004');
insert into product values(17,'良品铺子海带丝',17,'c004');
insert into product values(18,'三只松鼠坚果',88,null);
use mydb2;
select 字段 from 表 where 条件
-- 1.查询所有的商品.
# * 表示所有字段
select * from product ;
select pid,pname,price,category_id from product ;
-- 2.查询商品名和商品价格.
select pname,price from product ;
-- 3.别名查询.使用的关键字是as(as可以省略的).
select pname as 商品名,price as 价格 from product ;
select pname 商品名, price 价格 from product ;
-- 4.对price列进行去重 distinct
select distinct price from product;
# 对一模一样的整行去重
select distinct * from product;
-- 5.将所有商品的价格+10元进行显示,并给新的price起别名
-- 字段名可以当成变量来用,字段名可以参与数学运算
select pname,price + 10 as new_price from product ;
select pname,price * 0.8 as new_price from product ;
条件查询
条件-算术运算符

select 6 + 2;
select 6 - 2;
select 6 * 2;
select 10 / 3; # 3.3333
select 10 % 3; # 取余数/取模 1 商为3
select 99 % 100; # 取余数/取模 99 商为0
条件-比较运算符
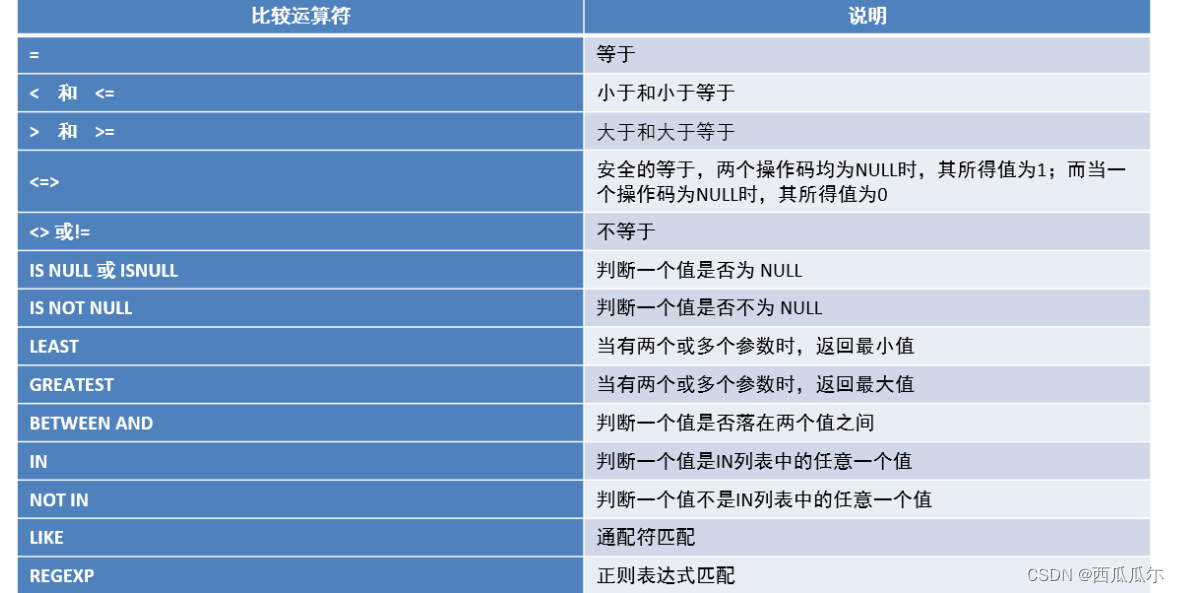
#-----------------------------------------
-- 查询商品名称为“海尔洗衣机”的商品所有信息:
select * from product where pname = '海尔洗衣机';
-- 查询价格为800商品所有信息
select * from product where price = 800;
-- 查询价格不是800的所有商品
select * from product where price <> 800;
select * from product where price != 800;
select * from product where not price = 800;
-- 查询商品价格大于60元的所有商品信息
select * from product where price > 60;
-- 查询商品价格在200到1000之间所有商品(包含200 和1000)
select * from product where price between 200 and 1000; # 包含边界值
-- 查询商品价格是200或800的所有商品
select * from product where price in(200,800);
-- select * from product where province in('广东省','湖南省','台湾省');
-- 查询商品价格不是200或800的所有商品
select * from product where price not in(200,800);
-- select * from product where province not in('广东省','湖南省','台湾省');
-- 查询含有‘裤'字的所有商品
-- %匹配任意个字符,0个或者多个都行
-- _匹配一个字符,什么字符都可以
select * from product where pname like '%裤%';
-- 查询第3个字为京的商品信息
select * from product where pname like '__京%';
-- 查询4个字的商品信息
select * from product where pname like '____';
-- 查询姓李的学生
-- select * from student where name like '李%';
-- 查询最后一个字是杰
-- select * from student where name like '%杰';
-- 查询以'海'开头的所有商品
select * from product where pname like '海%';
-- 查询第二个字为'蔻'的所有商品
select * from product where pname like '_蔻%';
-- 查询category_id为null的商品
-- null六亲不认,null和任何值都不同,甚至 null 不等于 null
select * from product where category_id = null; # 不能用=来判断是否等于null
select * from product where category_id is null; # 不能用=来判断是否等于null
-- 查询category_id不为null分类的商品
select * from product where category_id is not null;
-- 使用least求最小值
-- 如果有一个值为null,则结果就是null
select least(price); #错误的,least不能求一列的最小值
select least(23,66,12,5);
select least(23,66,null,5); # 结果是null
-- 使用greatest求最大值
-- 如果有一个值为null,则结果就是null
select greatest(23,66,12,5);
select greatest(23,66,null,5); # 结果是null
条件-逻辑运算符
-
分类

-
语法
# 多个条件必须同时成立,结果才为真,只要有一个条件不成立,结果就假 select 字段 from 表 where 条件1 and 条件2 and 条件3 select 字段 from 表 where '性别为女' and '美艳动人' and '温柔贤惠' select 字段 from 表 where '高' and '富' and '帅' # 多个条件只要有一个条件成立,则结果就为真,多个条件全部为假,结果才为假 select 字段 from 表 where 条件1 or 条件2 or 条件3 select 字段 from 表 where '性别为女' or '美艳动人' or '温柔贤惠' select 字段 from 表 where '高' or '富' or '帅' # ! 就是把真变成假,假变为真 select 字段 from 表 where !('性别为女' and '美艳动人' and '温柔贤惠') select 字段 from 表 where not('性别为女' and '美艳动人' and '温柔贤惠') -
代码
-- 查询价格大于500,并且属于c002分类的商品 select * from product where price > 500 and category_id = 'c002' ; # 建议用这个 select * from product where price > 500 && category_id = 'c002'; -- 查询价格大于500,或者属于c002分类的商品 select * from product where price > 500 or category_id = 'c002'; # 建议用这个 select * from product where price > 500 || category_id = 'c002'; -- -- 查询分类不属于c002分类的商品 select * from product where not (category_id = 'c002'); # 建议用这个 select * from product where ! (category_id = 'c002'); select * from product where (条件1 and 条件2) or (条件3 and 条件4); select * from product where ('高' and '富') or ('富' and '帅');
排序查询

-
语法
select 字段名1,字段名2,…… from 表名 order by 字段名1 [asc|desc],字段名2[asc|desc]…… -
代码
#------------------排序查询---------------- -- 1.使用价格排序(降序:从大到小) select * from product order by price desc;#topn -- 2.使用价格排序(升序:从小到大)吧 select * from product order by price asc; select * from product order by price ; #默认就是升序 -- 2.在价格排序(降序)的基础上,以分类排序(降序) # 先按照price进行降序排序,如果price相同,则按照category_id降序排序 select * from product order by price desc,category_id desc; -- 3.显示商品的价格(去重复),并排序(降序) select distinct price from product order by price desc ;
聚合查询
-
语法
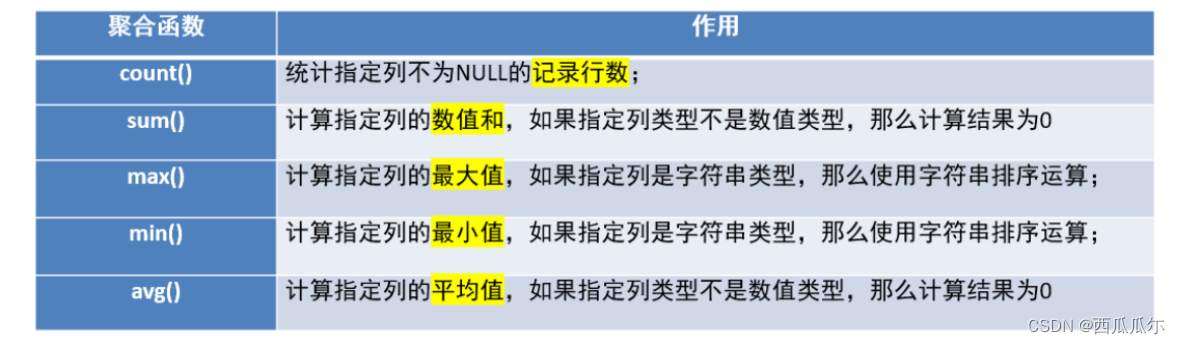
-
代码
#------------------------------------------ -- 1 查询商品的总条数 # 统计一张表的行数,有三种方式,以下方式都可以 select count(pid) from product; # 统计pid列有多少不为null的行 select count(*) from product; # 统计整个表有多少行 select count(1) from product; # 统计整个表有多少行 -- 2 查询价格大于200商品的总条数 select count(*) from product where price > 200; -- 3 查询所有商品的总和 select sum(price) from product; -- 4 查询分类为'c001'的所有商品的总和 select sum(price) from product where category_id = 'c001'; # sum不会统计null值,就当null值不存在 create table test1( id int, price int ); insert into test1 values (1,10); insert into test1 values (2,null); insert into test1 values (3,10); select sum(price) from test1; # 20 -- 4 查询商品的最大价格 # max不会统计null值,就当null值不存在 select max(price) from product; select max(price) from test1; -- 5 查询商品的最小价格 # min不会统计null值,就当null值不存在 select min(price) from product; select min(price) from test1; -- 6 查询所有商品的平均价格 # avg,就当null值不存在, select avg(price) from product; select avg(price) from test1;
分组查询
-
语法
select 字段1,字段2… from 表名 group by 分组字段 [ having 分组条件]; -
代码
#----------------分组查询----------------- # 分组之后一般要对同一组的数据进行统计:求和、求数量,求平局值 # 分组之后一般都要进行统计 # 分组之后group by的后边只能跟分组字段和聚合函数 # 1、统计每一类商品的个数 select category_id,count(*) from product group by category_id; select category_id,count(*) from product group by category_id having count(*) > 5; # 1、统计价格大于10的每一类商品的个数,并输出大于大于5的分类信息,并降序排序: Ctrl + Alt + l select category_id,count(*) from product where price > 10 # where是在分组之前进行筛选 group by category_id having count(*) > 5 # having是在分组统计之后进行筛选 order by count(*) desc; #----------------------------------- select category_id,count(*) as cnt from product where price > 10 # where是在分组之前进行筛选 group by category_id having cnt > 5 # having是在分组统计之后进行筛选 order by cnt desc; # 2、统计每一类商品的平均价格 select category_id,avg(price) from product group by category_id; # 3、统计每个省的学生都多少人 -- group by的后边可以跟多个字段,多个字段完全相同才能分到同一组 -- 同一个省分别有多少同学 select province,count(*) from mydb1.student group by province; -- 同一个省,同一个市分别有多少同学 select province,city,count(*) from mydb1.student group by province,city; -- 同年,同月,同日的同学都多少人(伪代码) select year,month,day,count(*) from mydb1.student group by year,month,day;
分页查询
-
语法
-- 方式1-显示前n条 select 字段1,字段2... from 表明 limit n -- 方式2-分页显示 select 字段1,字段2... from 表明 limit m,n m: 整数,表示从第几条索引开始,索引是从0开始,计算方式 (当前页-1)*每页显示条数 n: 整数,表示查询多少条数据 -
特点
limit 以后主要用于求TopN:求部门薪水最高的前n为员工 -
代码
#---------------------------------------- select * from product limit 5; # 显示前5条数据 # 显示1 - 5 行 select * from product limit 0,5; # 从索引为0(第1行)的行开始显示,一共显示5行 # 显示 6- 10 行 select * from product limit 5,5; # 从索引为5(第6行)的行开始显示,一共显示5行 # 显示 11- 15 行 select * from product limit 10,5; # 从索引为10(第11行)的行开始显示,一共显示5行 -- 显示 76 - 83 行 select * from product limit 75,8;
保存查询结果
-
语法
insert into Table2(field1,field2,…) select value1,value2,… from Table1 -
特点
1、该语句用来保存查询后的结果 2、结果表的字段一定要和查询的字段数量和类型一致 -
代码
# 1、创建目标表、用来保存辛苦查询的结果 create table mydb1.t_avg_price_per_category( category_id varchar(20), avg_price decimal(12,2) ); # 2、将查询的结果插入到结果表 insert into mydb1.t_avg_price_per_category select category_id,avg(price) from product group by category_id;
MySQL的多表关系
介绍
1、在实际的项目中,我们MySQL表一般是很多张,必须要学会多表查询
2、MySQL的多表查询包含:多表join查询,子查询、自关联查询
多表关系
一对一关系(A表和B表): A表的一行对应B的一行,反之B表的一行对应A的一行
一对多关系(A表和B表): A表的一行对应B的多行,反之B表的多行对应A的一行
多对多关系(A表和B表): A表的一行对应B的多行,反之B表的一行对应A的多行
操作-一对一关系
一对一关系由于两张表可以合成一张表,我们不做考虑
操作-一对多关系
介绍
1、一对多描述的表数据之间的包含关系:省对市,部门对员工,领导对员工
2、一对多关系(A表和B表): A表的一行对应B的多行,反之B表的多行对应A的一行
创建外键约束
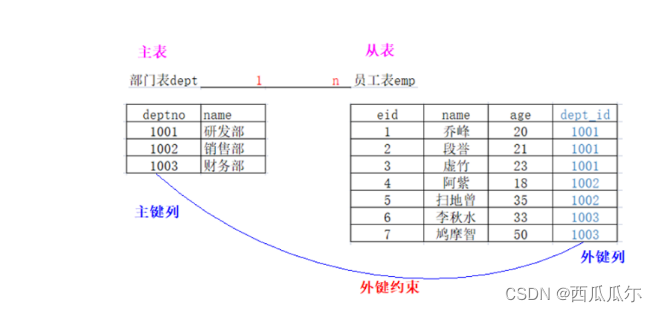
#------------------------------------方式1-----------------------------
create database if not exists mydb3;
use mydb3;
# 1、创建主表 - 部门表
create table if not exists dept(
deptno varchar(20) primary key , -- 部门号
name varchar(20) -- 部门名字
);
# 2、创建从表 - 员工表
create table if not exists emp
(
eid varchar(20) primary key, -- 员工编号
ename varchar(20), -- 员工名字
age int, -- 员工年龄
dept_id varchar(20) -- 员工所属部门
);
# 3、创建外键约束
#alter table <从表名字> add constraint <外键名> foreign key(<外键列名字>) references <主表名字> (<主键列名字>);\
# 给从表emp添加一个外键约束,约束的名字是fk_dept_emp,从表外键列是dept_id,该列要依赖主表dept的deptno主键列
alter table emp add constraint fk_dept_emp foreign key(dept_id) references dept (deptno);
# 4、删除表
# 必须先删除从表,再删主表
drop table emp;
drop table dept;
#------------------------------------方式2-----------------------------
# 1、创建主表 - 部门表
create table if not exists dept(
deptno varchar(20) primary key , -- 部门号
name varchar(20) -- 部门名字
);
# 2、创建从表 - 员工表
create table if not exists emp
(
eid varchar(20) primary key, -- 员工编号
ename varchar(20), -- 员工名字
age int, -- 员工年龄
dept_id varchar(20), -- 员工所属部门
constraint fk2_dept_emp foreign key (dept_id) references dept (deptno) -- 外键约束
);
# 4、删除表
# 必须先删除从表,再删主表
drop table emp;
drop table dept;
删除外键约束
alter table emp drop foreign key fk2_dept_emp;
外键约束下的数据操作
#添加数据: 一定要先给主表添加数据,再给从表添加数据
#删除数据:一定要先删从表数据,再删主表数据
# 1、创建主表 - 部门表
create table if not exists dept(
deptno varchar(20) primary key , -- 部门号
name varchar(20) -- 部门名字
);
# 2、创建从表 - 员工表
create table if not exists emp
(
eid varchar(20) primary key, -- 员工编号
ename varchar(20), -- 员工名字
age int, -- 员工年龄
dept_id varchar(20), -- 员工所属部门
constraint fk2_dept_emp foreign key (dept_id) references dept (deptno) -- 外键约束
);
# 3、添加数据
# 一定要先给主表添加数据,再给从表添加数据
insert into dept values ('1001','研发部');
insert into emp values (1,'乔峰',20,'1001');
# 4、删除数据
# 一定要先删从表数据,再删主表数据
delete from emp;
delete from dept;

操作-多对多关系
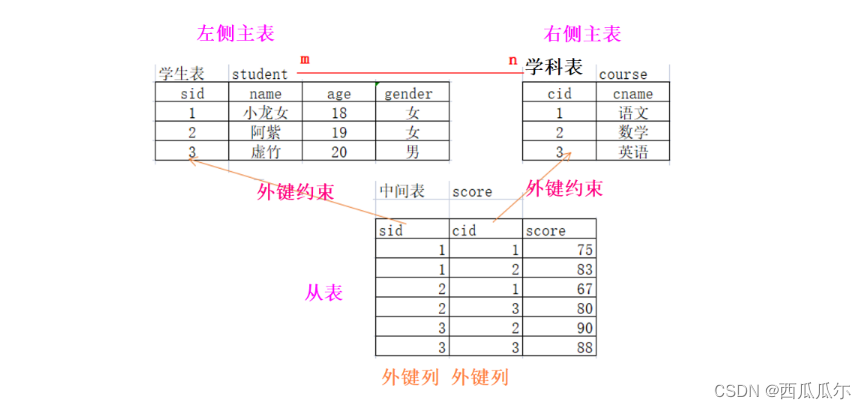
介绍
多对多关系(A表和B表): A表的一行对应B的多行,反之B表的一行对应A的多行
特点
多对多关系必须有中间表,通过中间表将两个表的关系进行定义
代码
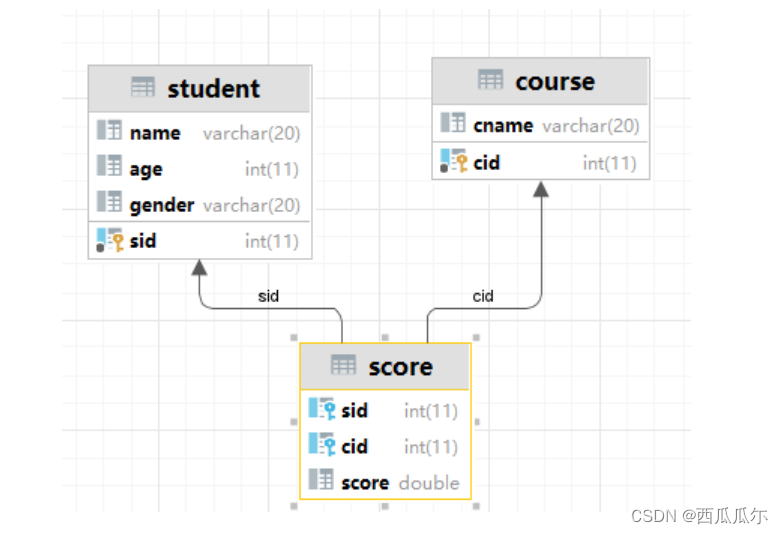
# 1、创建左侧主表-学生表
create table if not exists student(
sid int primary key auto_increment,
name varchar(20),
age int,
gender varchar(20)
);
# 2、创建右侧主表-学科表
create table course(
cid int primary key auto_increment,
cname varchar(20)
);
# 3、创建中间表-成绩表
create table score(
sid int,
cid int,
score double
);
# 4、创建左侧外键约束
alter table score add constraint fk1 foreign key(sid) references student (sid);
# 5、创建右侧外键约束
alter table score add constraint fk2 foreign key(cid) references course (cid);
# 6、插入数据
# 插入数据时,必须先给两侧的主表插入
insert into student values (1,'小龙女',18,'女');
insert into course values (1,'语文');
# 给中间表插入数据
insert into score values (1,1,88);
# 7、删除数据
# 先删除从表数据
delete from score;
# 再删除主表数据
delete from student;
delete from course;
MySQL的多表查询
分类
#交叉连接查询 [产生笛卡尔积,了解]
语法:select * from A,B;
#内连接查询(使用的关键字 inner join -- inner可以省略)
隐式内连接(SQL92标准):select * from A,B where 条件;
显示内连接(SQL99标准):select * from A inner join B on 条件;
#外连接查询(使用的关键字 outer join -- outer可以省略)
左外连接:left outer join
select * from A left outer join B on 条件;
右外连接:right outer join
select * from A right outer join B on 条件;
满外连接: full outer join
select * from A full outer join B on 条件;
#子查询
select的嵌套
交叉连接查询
-
语法
select * from 表1,表2; # 92标准写法 select * from 表1 cross join 表2; # 99标准写法 -
特点
1、内连接求两张表笛卡尔积,会产生大量的冗余数据,后续所有的查询都是在笛卡尔积基础上进行数据筛选 -
代码
use mydb3; -- 创建部门表 drop table if exists dept3; create table if not exists dept3( deptno varchar(20) primary key , -- 部门号 name varchar(20) -- 部门名字 ); -- 创建员工表 drop table if exists emp3; create table if not exists emp3( eid int primary key , -- 员工编号 ename varchar(20), -- 员工名字 age int, -- 员工年龄 dept_id varchar(20) -- 员工所属部门 ); -- 给dept3表添加数据 insert into dept3 values('1001','研发部'); insert into dept3 values('1002','销售部'); insert into dept3 values('1003','财务部'); insert into dept3 values('1004','人事部'); -- 给emp表添加数据 insert into emp3 values(1,'乔峰',20, '1001'); insert into emp3 values(2,'段誉',21, '1001'); insert into emp3 values(3,'虚竹',23, '1001'); insert into emp3 values(4,'阿紫',18, '1001'); insert into emp3 values(5,'扫地僧',85, '1002'); insert into emp3 values(6,'李秋水',33, '1002'); insert into emp3 values(7,'鸠摩智',50, '1002'); insert into emp3 values(8,'天山童姥',60, '1003'); insert into emp3 values(9,'慕容博',58, '1003'); insert into emp3 values(10,'丁春秋',71, '1005'); # 交叉连接是将两张表相乘:用左表的每一行去匹配右边的所有行 # 交叉连接产生了笛卡尔积,会产生大量的冗余数据,后续所有的查询都是在笛卡尔积基础上进行数据筛选 select * from dept3,emp3; # 92标准写法 select * from dept3 cross join emp3; # 99标准写法
内连接查询

-
语法
隐式内连接(SQL92标准):select * from A,B where 条件; 显示内连接(SQL99标准):select * from A inner join B on 条件; -
特点
求两张表的交集,重合的部分,就是在笛卡尔积基础上筛选 -
代码
# 求两张表的交集,重合的部分,就是在笛卡尔积基础上筛选 # 92标准:select * from A,B where 条件; select * from dept3,emp3 where deptno = dept_id ; select * from dept3 as t1 ,emp3 as t2 where t1.deptno = t2.dept_id ; #99标准:select * from A inner join B on 条件; select * from dept3 inner join emp3 on deptno = dept_id ; select * from dept3 join emp3 on deptno = dept_id ; select * from dept3 as t1 inner join emp3 as t2 on t1.deptno = t2.dept_id ; select * from dept3 as t1 join emp3 as t2 on t1.deptno = t2.dept_id ; # 三张表的内连接 select t1.sid,name,score,cname from student t1 join score t2 on t1.sid = t2.sid join course t3 on t2.cid = t3.cid ;
外连接查询
左外连接
](https://img-blog.csdnimg.cn/direct/2e20e65524b84d6bb226d391cd83cac7.png)
-
语法
左外连接:left outer join select * from A left outer join B on 条件; -
特点
# 左外连接:以左表为主,是把左表的输出全部输出,右表有交集部分的输出,没有交集部分就是输出NULL # 左外连接会丢失右表没有交集的数据 # 关键字: left outer join ---> left join -
代码
# 左外连接:以左表为主,是把左表的输出全部输出,右表有交集部分的输出,没有交集部分就是输出NULL # 左外连接会丢失右表没有交集的数据 # 关键字: left outer join ---> left join select * from dept3 left join emp3 on deptno = dept_id ; select t1.sid,name,score,cname from student t1 left join score t2 on t1.sid = t2.sid left join course t3 on t2.cid = t3.cid ;
右外连接
](https://img-blog.csdnimg.cn/direct/96f33a2ba7a84a3aa228fe30321fc296.png)
-
语法
左外连接:right outer join select * from A right outer join B on 条件; -
特点
# 右外连接:以右表为主,是把右表的输出全部输出,左表有交集部分的输出,没有交集部分就是输出NULL # 右外连接一般用的很少,因为对于左外连接来讲,交换两张表的位置也可以实现右外的效果 # 右外连接会丢失左表没有交集的数据 # 关键字: right outer join ---> right join -
代码
select * from dept3 right join emp3 on deptno = dept_id ;
满外连接

-
特点
1、mysql8.0不支持满外连接,可以使用union关键字来实现 2、满外连接,将左表和右边的数据全部输出,没有对应的部分都输出NULL,相当于左外和右外的并集 -
代码
# 满外连接,将左表和右边的数据全部输出,没有对应的部分都输出NULL # MySQL不支持满外 select * from dept3 full join emp3 on deptno = dept_id ; # 使用union关键字将左外和右外求并集,union关键字是将两张表上下拼接在一起 # union 去重, union all:不去重 select * from dept3 left join emp3 on deptno = dept_id union select * from dept3 right join emp3 on deptno = dept_id ;
案例
# 求每个部门的员工总数
select
deptno,name,count(eid) as cnt
from dept3
left join emp3 on deptno = dept_id
group by deptno,name
having cnt > 2
order by cnt desc
limit 3;
MySQL的子查询
概念
子查询就是select的嵌套
代码
#---------------子查询-----------------
# 查询员工年龄最大的信息
select max(age) from emp3;
select * from emp3 where age = (select max(age) from emp3);
# 查询大于平均年龄的员工信息
select avg(age) from emp3;
select * from emp3 where age > (select avg(age) from emp3);
# 查询研发部和销售部的员工信息
#------------------------------------------------
select
*
from dept3
left join emp3 on deptno = dept_id
where name in('研发部','销售部');
#------------------------------------------------
select deptno from dept3 where name in('研发部','销售部');
select * from emp3 where dept_id in(select deptno from dept3 where name in('研发部','销售部'));
#------------------------------------------------
# 查询研发部和销售部的员工年龄大于30岁的员工信息
select * from dept3 where name in('研发部','销售部'); # 在左表查询'研发部','销售部'信息
select * from emp3 where age > 30; # 在右表查询age大于30的员工信息
select * from (select * from dept3 where name in('研发部','销售部')) t1
join (select * from emp3 where age > 30) t2 on t1.deptno = t2.dept_id;
#删除研发部和销售部的员工
delete from emp3
where dept_id in (select deptno from dept3 where name = '研发部' or name = '销售部' );
union
select * from dept3 right join emp3 on deptno = dept_id ;
### 案例
```sql
# 求每个部门的员工总数
select
deptno,name,count(eid) as cnt
from dept3
left join emp3 on deptno = dept_id
group by deptno,name
having cnt > 2
order by cnt desc
limit 3;















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









