







文章目录
Python第3天
Python容器的分类
字符串
列表
元组
字典
集合
容器-字符串
基本操作
-
定义
name1 = 'Tom' #该方式内部不能再包含单引号 name2 = "Rose" #该方式内部可以包含单引号 str1 = '''I am Tom, nice to meet you! ''' #该方式内部可以包含单引号 str2 = """ I am Rose, nice to meet you! """ #该方式内部可以包含单引号 -
下标/索引的概念
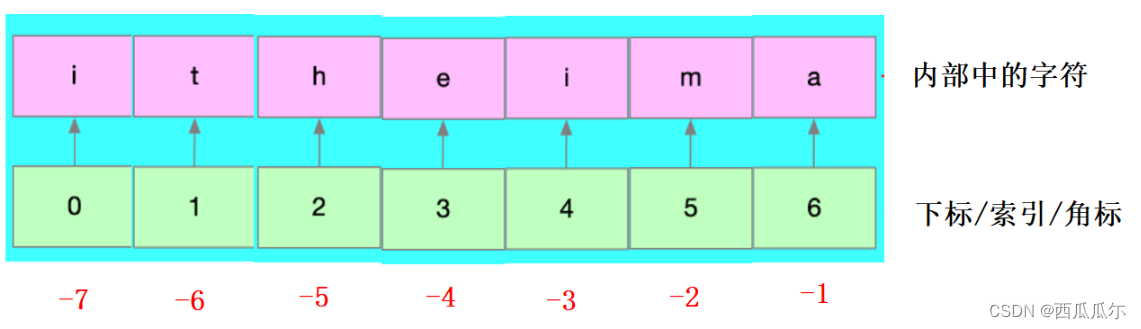
1、将字符串存入内存中,这些字符串的每个字符是连续存放的,是挨着的 2、为了更加方便的去访问字符串中的每一个字符,python将每一个字符都进行了编号,编号从0开始 3、字符串中每个字符的编号被称为下标,索引,或者角标 4、之所以设计索引或者角标是为了以后能够快速的找到某个字符 5、如果一个字符串长度是n,则下标的范围是:0 到 n- 1 6、最后一个元素的索引也可以-1 -
代码1-访问每个元素
name = 'abcde' print('------------使用下标访问---------------') print(name[0]) print(name[1]) print(name[2]) print(name[3]) print(name[4]) print('------------使用for访问每个元素---------------') for x in name: print(x) print('------------使用for访问下标获取元素---------------') for i in range(0,5): # i是数字,当做索引 print(name[i]) print('------------使用for访问下标获取元素2---------------') for i in range(0, len(name)): # 通过len获取字符串的长度,也就是字符串中字符的个数 print(name[i])
切片
-
格式
#包含起始索引,不包含结束索引, 步长表示一次跳几个字符,如果步长为1表示一个一个截取,如果步长为2则就是一次跳过一个 字符串[起始索引:结束索引:步长] #步长不写的话,默认就是1 -
代码1
card_id = '430421200112236789' #截取出生年份 print(card_id[6:10:1]) name = 'abcdefghijk' print(name[2:5:1]) # cde print(name[2:5]) # cde 步长默认是1 print(name[2:7:2]) # ceg print(name[:7:1]) # abcdefg 起始索引不写表示从0开始 print(name[2::]) # cdefghijk 结束索引不写,表示截取到最后 print(name[2:]) # cdefghijk 结束索引不写,步长不写,表示截取到最后 print(name[:-1]) # abcdefghij从开头截取到倒数第二个(-1表示倒数第一个) print(name[:-3]) # abcdefgh 从开头截取到倒数第四个(-3表示倒数第三个) print(name[-6:-3]) # fgh 从倒数第六个截取到倒数第四个 print(name[::-1]) # kjihgfedcba 如果步长为-1,则将字符串翻转 print('-----------') print(name[8:2:-1]) # ihgfed 从索引为8的字符开始截取到索引为3(不包含2) print(name[8:2:-2]) # ige 将最后一个元素当做索引为0的元素,从右向左开始输出 file1 = 'ldlkdkl.txt' file2 = 'a.py' #判断文件是否是txt结尾 if file1[-3:] == 'txt': print('文件是txt') -
代码2
s = 'Hello World!' print(s[4]) # o 通过索引访问 print(s) # Hello World! print(s[:]) # Hello World! print(s[1:]) # ello World! print(s[:5]) # Hello print(s[:-1]) # Hello World print(s[-4:-1]) # rld print(s[1:5:2]) # el
方法
find方法
-
特点
#在大串中查找是否包含某个子串,可以指定查找的区间,这个区间是包头不包尾 #查到之后会返回该子串在大串中第一次出现的索引,如果没有找到则返回-1 字符串序列.find(子串, 开始位置下标, 结束位置下标) -
操作
mystr = "abchelloworldandhellopythonhelloaaa" rs1 = mystr.find('hello') #在整个字符串中查找hello第一次出现的索引 print(rs1) rs2 = mystr.find('hello',2,7) #在索引为 2 - 6 之间查找是否包含hello,注意不包含索引7 print(rs2) rs2 = mystr.find('hello',5) #在索引为 2 -最后 之间查找是否包含hello,注意不包含索引7 print(rs2)
index方法
-
特点
#作用和find相同,只是如果没有找到子串,则报错 字符串序列.index(子串, 开始位置下标, 结束位置下标) -
操作
print('------------index--------------') rs1 = mystr.index('hello') #在整个字符串中查找hello第一次出现的索引 print(rs1) rs2 = mystr.index('hello',2,7) #在索引为 2 - 6 之间查找是否包含hello,注意不包含索引7 print(rs2)
replace方法
-
特点
字符串序列.replace(旧子串, 新子串, 替换次数) #1、功能是将字符串中的旧字符串替换为新字符串,默认是全部替换 #2、如果你指定了替换次数n,则会替换前n个子串 #3、替换之后,原来的字符串并没有发生变化,会发生新的字符串 -
操作
print('------------replace--------------') str1 = '你好,我是写作小帮,有任何写作的问题,都可以向我提问,我们一起提高写作能力。' print(str1) str2 = str1.replace('写作','编程') # 全部替换 print(str2) str3 = str1.replace('写作','编程',2) # 替换前2个 print('------------先查找再替换--------------') str1 = '你好,我是写作小帮,有任何写作的问题,都可以向我提问,我们一起提高写作能力' rs1 = str1.find('写作') #先查找 if rs1 != -1: str2 = str1.replace('写作','写代码') print('替换后的字符串:'+str2) else: print('没有找到你要替换的内容')
split方法
-
特点
字符串序列.split(分割字符, num) #1、功能是对字符串按照分隔符进行切割,默认是全部切割,指定num参数之后,可以切割前num次 #2、切割之后原字符串不变,返回切割后的内容 #3、split切割时,如果不指定分隔符,默认的分隔符是一切的空白符:一个空格,多个空格,\n、 \t -
操作
print('------------split--------------') str1 = '2024-12-24' print(str1.split('-')) print(str1.split('-',1)) str1 = '2024/12/24' print(str1.split('/')) print('-----------------------') str1 = '2024 12 24' print(str1.split(' ')) # 只能切一个空格 print(re.split(' +',str1)) # 正则表达式,+表示一个空格或者多个空格都能切
endswith和startswith方法
-
特点
endswith:以什么结尾 字符串.endswith(子串) startswith:以什么开头 字符串.startswith(子串) -
操作
print('--------------------------')
str_file = 'abc.png.txt'
# 该方法用来判断是否以某个字符串结尾
# 如果匹配成功则返回True,否则返回False
rs1 = str_file.endswith('.png')
if rs1:
print('该文件是以.png结尾')
else:
print('该文件不是以.png结尾')
print('--------------------------')
str1 = 'helloworldpython'
str1.endswith()
if str1.startswith('hello'):
print('字符串以hello开头')
else:
print('字符串不以hello开头')
练习
# 练习题1:输入一个字符串,打印所有偶数位上的字符(下标是0,2,4,6…位上的字符)
str1 = input('请输入一个字符串:') #abcdefghijk
print(str1[::2])
print('-----------------------------')
for i in range(0, len(str1)):
if i % 2 == 0:
print(str1[i])
print('-----------------------------')
# 练习题2:给定一个文件名,判断其尾部是否以".png"结尾
str_file = 'abc.png.txt'
if str_file[-4:] == '.png':
print('该文件是以.png结尾')
else:
print('该文件不是以.png结尾')
print('--------------------------')
str_file = 'abc.png.txt'
rs1 = str_file.find('.png',-4) #表示从倒数第4个开始查到最后,看是否包含.png
if rs1 != -1:
print('该文件是以.png结尾')
else:
print('该文件不是以.png结尾')
print('--------------------------')
str_file = 'abc.png.txt'
# 该方法用来判断是否以某个字符串结尾
# 如果匹配成功则返回True,否则返回False
rs1 = str_file.endswith('.png')
if rs1:
print('该文件是以.png结尾')
else:
print('该文件不是以.png结尾')
容器-列表
语法
列表名称 = [数据1, 数据2, 数据3, 数据4, ...]
解释:
列表名称: list1、list2、list_student...
列表的标记符号是中括号
列表中可以同时存放任何类型的数据
#列表是可变的,也就是列表中的数据是可以被修改的
操作
定义列表
# 1、定义一个空列表
#空列表必须有[]
list1 = []
print(list1)
# 2、定义一个有内容列表,类型一致
#如果列表中只存放一个类型的数据,则类似其他语言的数组
list2 = ['刘备', '关羽', '张飞']
print(list2)
# 3、定义一个有内容列表,类型不一致
list3 = ['刘备', 32, False, 120.5]
print(list3)
# 4、定义一个嵌套列表
#List列表和其他容器包括自己可以无限的嵌套
list4 = [['刘备', 32, False, 120.5],['关羽', 33, True, 130.5]]
下标/索引
-
概念
列表的底层存储形式和字符串都是一样的,其也是通过索引下标来对其进行引用的 list1 = ['刘备', '关羽', '张飞', '赵云', '张飞'] 正索引: 0 1 2 3 4 负索引: -1 -2 -3 -4
-
操作
# 1、定义列表 list1 = ['刘备', '关羽', '张飞', '赵云', '张飞'] # 2、使用索引来访问 """ 正索引: 0 1 2 3 4 负索引: -1 -2 -3 -4 """ # 列表的名字[下标] print(list1[0]) # 访问第一个元素 print(list1[4]) # 访问最后一个元素 print(list1[-1]) # 访问最后一个元素 使用 -1 print('---------------------------') # 3、使用for来遍历列表 # for会将列表中的每一个元素依次的给x for x in list1: print(x)
列表的遍历
-
概念
1、遍历就是将列表中的元素一个个的输出 -
代码
# 1、定义列表 list1 = ['刘备', '关羽', '张飞', '赵云', '张飞'] print('------------for遍历-1---------------') # 2、使用for来遍历列表 # for会将列表中的每一个元素依次的给x for x in list1: #x是每一个元素数据,不是索引 print(x) print('------------for遍历-2---------------') for i in range(0, len(list1)): #i是每一个的索引 print(list1[i]) print('------------while遍历---------------') # while遍历可以直接访问到列表中每一个索引 i = 0 while i < len(list1): # 0 1 2 3 4 print(list1[i]) i += 1
列表的切片
-
介绍
1、列表的切片规则和字符串是一样的 2、截取之后原来的列表不会发生变化,我们可以把截取后的列表存入一个新列表中,方便后期计算 -
操作
list_name = ['刘备', '关羽', '张飞', '赵云', '郭嘉','曹操','孙权','徐晃','典韦','黄忠'] list_name2 = list_name[2:5:1] # 我们可以把截取后的列表存入一个新列表中,方便后期计算 print(list_name[2:5:1]) # ['张飞', '赵云', '郭嘉'] print(list_name[2:5]) # ['张飞', '赵云', '郭嘉'] print(list_name[2:7:2]) # ['张飞', '郭嘉','孙权'] print(list_name[:7:1]) # ['刘备', '关羽', '张飞', '赵云', '郭嘉', '曹操', '孙权'] print(list_name[2::]) # ['张飞', '赵云', '郭嘉', '曹操', '孙权', '徐晃', '典韦', '黄忠'] print(list_name[2:]) # ['张飞', '赵云', '郭嘉', '曹操', '孙权', '徐晃', '典韦', '黄忠'] print(list_name[:-1]) # ['刘备', '关羽', '张飞', '赵云', '郭嘉', '曹操', '孙权', '徐晃', '典韦'] print(list_name[:-3]) # 从头到倒数第4个 ['刘备', '关羽', '张飞', '赵云', '郭嘉', '曹操', '孙权'] print(list_name[-6:-3]) # 倒数第6个到倒数第4个 ['郭嘉', '曹操', '孙权'] print(list_name[::-1]) # 倒叙 ['黄忠', '典韦', '徐晃', '孙权', '曹操', '郭嘉', '赵云', '张飞', '关羽', '刘备'] print(list_name[:-3:-1]) # 倒叙 ['黄忠', '典韦', '徐晃', '孙权', '曹操', '郭嘉', '赵云', '张飞', '关羽', '刘备'] print(list_name)
列表的操作-添加
-
方法
添加元素 ("增"append, extend, insert) #1、append方法 语法: 列表.append(新的元素) #1.1每次将新的元素追加到原来列表的后边 #1.2如果添加一个列表,则会将改列表当做一个整体添加 #2、extend方法 语法: 列表.extend(新的元素) #2.1 每次将新的元素追加到原来列表的后边,但是会把任何添加的内容当做一个容器,如果数据是一个序列,则将这个序列的数据逐一添加到列表 #2.2 该方法可以将两个列表进行合并 #3、insert方法 语法:列表.insert(索引,新数据) #3.1 insert和append、extend不同,insert可以指定添加到列表中的任意位置 #3.3 insert添加时,添加位置的元素及后边的元素依次向后移,空出一个空位进行添加
-
操作
print('---------------append------------------') # 1、定义列表 list1 = ['刘备', '关羽', '张飞', '赵云', '张飞'] # 2、向列表中追加元素: 曹操 list1.append('曹操') #已经修改了原来的列表 ['刘备', '关羽', '张飞', '赵云', '张飞',’曹操‘] list1.append('孙权') #已经修改了原来的列表 list1.append(18) #添加其他类型,已经修改了原来的列表 list1.append(['周瑜','大乔']) #这种添加会将小列表整体进行添加:['刘备', '关羽', '张飞', '赵云', '张飞', '曹操', '孙权', ['周瑜', '周瑜']] list1.extend(['诸葛亮','吕布']) #这种添加会将小列表整体进行添加:['刘备', '关羽', '张飞', '赵云', '张飞', '曹操', '孙权', ['周瑜', '大乔'], '诸葛亮', '吕布'] print(list1) print('---------------extend------------------') # 1、定义列表 list1 = ['刘备', '关羽', '张飞', '赵云', '张飞'] # 2、使用extend进行添加 list1.extend('小乔') #['刘备', '关羽', '张飞', '赵云', '张飞', '小', '乔'] 此时,会将小乔当做一个容器,进行拆分,将拆分后的 小 和 乔 分别进行添加 list1.extend(['小乔']) #['刘备', '关羽', '张飞', '赵云', '张飞', '小', '乔','小乔'] 此时,会将小乔当做一个容器,进行拆分,将拆分后的 小 和 乔 分别进行添加 print(list1) print('---------------extend-列表合并------------------') list1 = ['刘备', '关羽', '张飞', '赵云'] list2 = ['曹操', '郭嘉', '典韦', '徐晃'] list1.extend(list2) #['刘备', '关羽', '张飞', '赵云', '曹操', '郭嘉', '典韦', '徐晃'] print(list1) print(list2) print('---------------insert------------------') # 1、定义列表 list1 = ['刘备', '关羽', '张飞', '赵云'] #2、在索引为1的位置添加 曹操 list1.insert(1,'曹操') # ['刘备', '曹操', '关羽', '张飞', '赵云'] print(list1) list1.insert(1,['曹操','孙权']) # ['刘备', ['曹操', '孙权'], '曹操', '关羽', '张飞', '赵云'] print(list1) #如果要添加的索引值超过了列表的最大索引,则会将数据添加到最后 list1.insert(100,'刘协') # ['刘备', ['曹操', '孙权'], '曹操', '关羽', '张飞', '赵云', '刘协'] print(list1)
列表的操作-查找

index
-
语法
语法:列表序列.index(数据, 开始位置下标, 结束位置下标) 解释: 数据:是要查找的内容 开始位置下标, 结束位置下标:要查找的区间索引,包头不包尾 -
代码
print('---------------index------------------') # 1、定义列表 list1 = ['刘备', '关羽', '张飞',['孙权','黄盖'], '赵云','曹操', '郭嘉', '典韦', '徐晃'] """ 语法:列表序列.index(数据, 开始位置下标, 结束位置下标) """ # 2、查看列表中是否有赵云 rs1 = list1.index('赵云') # 如果找到返回第一个索引值,找不到则报错 print(rs1) # 3、查看列表中是否有孙权 rs1 = list1.index('孙权') # 找不到,因为index只能看到['孙权','黄盖']这个子列表整体,看不到里边的内容 print(rs1) # 3、查看列表中是否有['孙权','黄盖'] rs1 = list1.index(['孙权','黄盖']) # 可以找到 print(rs1)
count
-
语法
#count()方法:统计指定数据在当前列表中出现的次数 列表序列.count(数据) #解释: 数据:你要统计的内容 该方法返回统计的次数 -
代码
print('---------------count------------------') list1 = ['刘备', '关羽', '张飞',['孙权','黄盖','张飞'], '赵云','曹操', '郭嘉', '典韦','张飞', '徐晃'] # 统计list1列表中有几个张飞 print(list1.count('张飞')) # 2 次
in和not in
-
语法
数据 in 列表 #判断数据是否在列表中,如果是返回True,否则返回False 数据 not in 列表 #判断数据是否不在列表中,如果是返回True,否则返回False -
代码
print('---------------in和not ------------------') list1 = ['刘备', '关羽', '张飞',['孙权','黄盖','张飞'], '赵云','曹操2', '郭嘉', '典韦','张飞', '徐晃'] list2 = ['刘备', '关羽', '张飞',['孙权','黄盖','张飞'], '赵云','曹操', '郭嘉', '典韦','张飞', '徐晃'] #判断曹操是否在list1中 print('曹操' in list1) # list1.in('曹操') #判断曹操是否不在list1中 print('曹操' not in list1) if '曹操' in list1 and 3 >2: print('曹操在列表中') else: print('曹操不在列表中')
列表的操作-删除
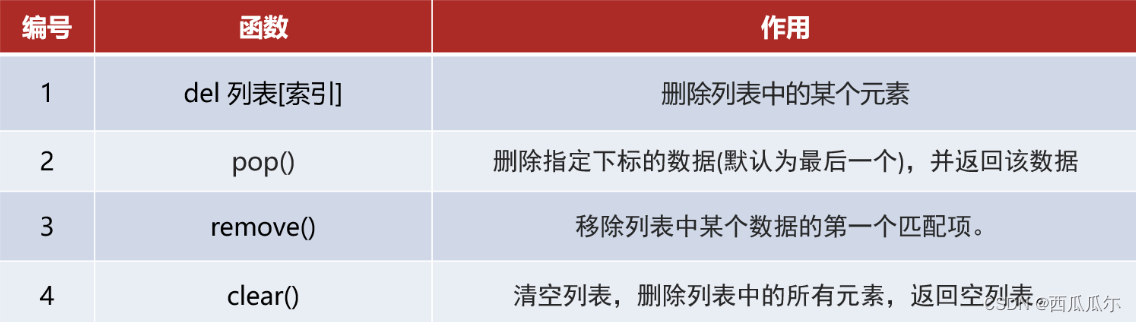
del:一般知道要删除的数据索引,用该方法 ,销毁列表,也可以该方法
pop:一般删除最后一个元素,用该方法, 或者知道索引,也可以用该方法
remove: 知道要删除数据的内容,用该方法
clear: 清空表内容,用该方法
del方法
-
语法
del 列表[要删除的数据索引] # 将索引对应元素的数据删除 del 列表 # 将整个列表销毁,列表不存在 -
操作
print('---------------del------------------') # 1、定义列表 list1 = ['刘备', '关羽', '张飞',['孙权','黄盖'], '赵云','曹操', '郭嘉', '典韦', '徐晃'] # 2、在list1列表删除典韦 del list1[-2] # 删除list1中索引为1位元素 # del list1[100] # 索引下标越界 print(list1) # 3、在list1列表删除内嵌的列表:['孙权','黄盖'] del list1[3] print(list1) print('-----------') # 4、将整个列表销毁 del list1 print(list1) # 报错,因为列表已经被删除
pop方法
-
语法
列表序列.pop() # 弹出列表最后一个数据,并返回 列表序列.pop(下标) # 弹出(获取)指定索引的数据,并将数据返回 #pop其实是弹栈或者出栈,是一种先进后出的数据结构 -
代码
print('---------------pop------------------') """ 列表.pop(索引) """ # 1、定义列表 list1 = ['刘备', '关羽', '张飞',['孙权','黄盖'], '赵云','曹操', '郭嘉', '典韦', '徐晃'] print(list1.pop()) # 取出最后一个元素,并返回 ,原列表会被修改 print(list1.pop(1)) # 取出索引为1元素, 并返回 ,原列表会被修改 print(list1) # 原列表少了被取出的元素
remove方法
-
语法
列表.remove(要删除的数据) # 在列表中删除指定的数据,但是只能删除第一次遇到的数据 -
代码
print('---------------remove------------------') """ 列表.remove(要删除的数据) 该方法没有返回值 """ # 1、定义列表 list1 = ['刘备', '关羽', '张飞',['孙权','黄盖'], '赵云','曹操', '郭嘉', '关羽', '徐晃'] print(list1) # 2、在list1列表中删除关羽 list1.remove('关羽') print(list1) # 3、在list1列表中删除 ['孙权','黄盖'] list1.remove(['孙权','黄盖']) print(list1) # 4、删除一个不存在的元素 if '诸葛亮' in list1: # 判断 诸葛亮是否存在,如果存在则删除,否则不存在,删除则报错 list1.remove('诸葛亮')
clear方法
-
语法
列表.clear() #将列表的内容清空,留下空列表 [] -
代码
print('---------------remove------------------') """ 列表.clear() """ # 1、定义列表 list1 = ['刘备', '关羽', '张飞',['孙权','黄盖'], '赵云','曹操', '郭嘉', '关羽', '徐晃'] # 2、清空list1列表 list1.clear() print(list1)
列表的操作-修改
修改操作
-
语法
列表[索引] = 新值 #将指定索引的值修改为新值 列表序列.reverse():将字符串翻转 列表序列.sort( reverse=False) 注意:reverse表示排序规则,reverse = True降序, reverse = False升序(默认) -
代码
print('-----------------根据索引修改---------------------') # 1、定义列表 list1 = ['刘备', '关羽', '张飞',['孙权','黄盖'], '赵云','曹操', '郭嘉', '典韦', '徐晃'] print(list1) # 2、将张飞修改为张苞 list1[2] = '张苞' print(list1) # 3、将['孙权','黄盖'] 改为 ['孙坚','黄盖'] list1[3] = ['孙坚','黄盖'] print(list1) print('-----------------反转---------------------') """ 列表名.reverse() """ # 1、定义列表 list1 = ['刘备', '关羽', '张飞',['孙权','黄盖'], '赵云','曹操', '郭嘉', '典韦', '徐晃'] print(list1) # 2、对以上列表进行翻转 list1.reverse() print(list1) print('--------------------------------------') """ 列表序列.sort(reverse=False) 注意:reverse表示排序规则,reverse = True降序, reverse = False升序(默认) 列表中一般是数字和字母 """ # 1、定义列表 list1 = [34,524,56,77,12,66,22] print(list1) # 2、对列表进行排序-升序 list1.sort() # 默认是升序 print(list1) list1.sort(reverse=False) # 指定升序 print(list1) # 3、对列表进行排序-降序 list1.sort(reverse=True) # 指定降序序 print(list1) # 4、对有英文字母的列表进行排序-升序 # 如果是英文排序,则按照单词在字典中出现的先后顺序来排 # 两个单词如果前边一样一样,哪个短,哪个在前边 list1 = ['student','hello','123','zero','aba','door','23','about','teachr','female','abandon'] list1.sort(reverse=False) # 指定升序 print(list1)
列表的嵌套
-
概念
列表的嵌套可以理解为一个大列表中嵌套了小列表 -
代码
list1 = [ ['刘备','关羽','张飞'], # 这个小列表名字是:list1[0] ['宝玉','黛玉','宝钗'], # 这个小列表名字是:list1[1] ['宋江','智深','武松','门庆'], # 这个小列表名字是list1[2] ['悟空','悟净','悟能'] # 这个小列表名字是:list1[3] ] # 访问智深 print(list1[2][1]) # 将 悟净 修改为 八戒 list1[3][1] = '八戒' print(list1) print('---------------对嵌套的列表进行遍历-----------------------') for x in list1: # x是大列表中包含的每一个小列表 ['刘备','关羽','张飞'] for name in x: # name是小列表中每一个元素 print(name) print('--------------------------------------') list1 = [ ['刘备',['关羽','诸葛'],'张飞'], # list1[0] ['宝玉','黛玉','宝钗'], # list1[1] ['宋江','智深','武松','门庆'], # list1[2] ['悟空','悟净','悟能'] # list1[3] ] #访问 诸葛 print(list1[0][1][1])
n’]
list1.sort(reverse=False) # 指定升序
print(list1)
### 列表的嵌套
+ 概念
```shell
列表的嵌套可以理解为一个大列表中嵌套了小列表
-
代码
list1 = [ ['刘备','关羽','张飞'], # 这个小列表名字是:list1[0] ['宝玉','黛玉','宝钗'], # 这个小列表名字是:list1[1] ['宋江','智深','武松','门庆'], # 这个小列表名字是list1[2] ['悟空','悟净','悟能'] # 这个小列表名字是:list1[3] ] # 访问智深 print(list1[2][1]) # 将 悟净 修改为 八戒 list1[3][1] = '八戒' print(list1) print('---------------对嵌套的列表进行遍历-----------------------') for x in list1: # x是大列表中包含的每一个小列表 ['刘备','关羽','张飞'] for name in x: # name是小列表中每一个元素 print(name) print('--------------------------------------') list1 = [ ['刘备',['关羽','诸葛'],'张飞'], # list1[0] ['宝玉','黛玉','宝钗'], # list1[1] ['宋江','智深','武松','门庆'], # list1[2] ['悟空','悟净','悟能'] # list1[3] ] #访问 诸葛 print(list1[0][1][1])















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









