






YOLOV3剪枝
论文:Network Slimming-Learning Efficient Convolutional Networks through Network Slimming
剪枝项目参考https://github.com/tanluren/yolov3-channel-and-layer-pruning
主要思路
-
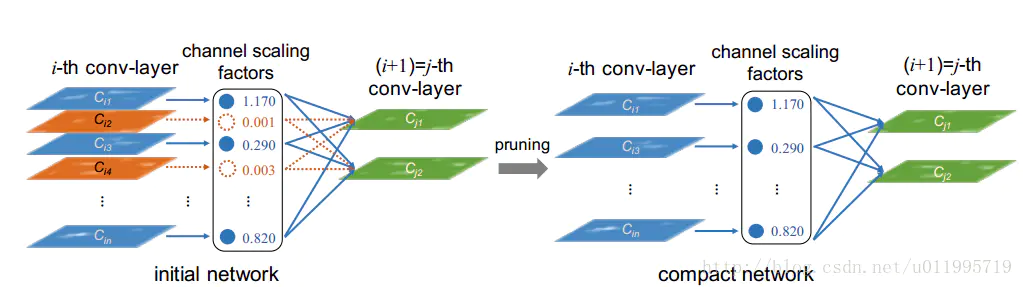
1、利用batch normalization中的缩放因子γ 作为重要性因子,即γ越小,所对应的channel不太重要,就可以裁剪(pruning)。
-
2、约束γ的大小,在目标方程中增加一个关于γ的L1正则项,使其稀疏化,这样可以做到在训练中自动剪枝,这是以往模型压缩所不具备的。
剪枝过程
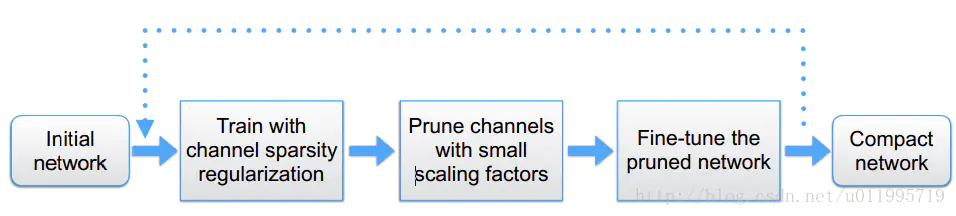
分为三部分,第一步,训练;第二步,剪枝;第三步,微调剪枝后的模型,循环执行
YOLOV3剪枝源码
1、正常剪枝
这部分分析来自该仓库https://github.com/coldlarry/YOLOv3-complete-pruning,但是更新的仓库也可以完成正常剪枝,prune.py。
使用了正常剪枝模式,不对short cut层(需要考虑add操作的维度一致问题)及上采样层(无BN)进行裁剪。
-
1、找到需要裁剪的BN层的对应的索引。
-
2、每次反向传播前,将L1正则产生的梯度添加到BN层的梯度中。
-
3、设置裁剪率进行裁剪。
-
将需要裁剪的层的BN层的γ参数的绝对值提取到一个列表并从小到大进行排序,若裁剪率0.8,则列表中0.8分位数的值为裁剪阈值。
-
将小于裁剪阈值的通道的γ置为0,验证裁剪后的map(并没有将β置为0)。
-
4、创建新的模型结构,β合并到下一个卷积层中BN中的running_mean计算。
-
5、生成新的模型文件。
2、优化的正常剪枝
slim_prune.py,在正常剪枝模式的基础上,完成对shortcut层的剪枝,同时避免裁剪掉整个层。
- 1、找到需要裁剪的BN层的对应的索引。
# 解析模型文件
def parse_module_defs2(module_defs):
CBL_idx = []
Conv_idx = []
shortcut_idx=dict()
shortcut_all=set()
ignore_idx = set()
for i, module_def in enumerate(module_defs):
if module_def['type'] == 'convolutional':
# 如果是卷积层中的BN层则将该层索引添加到CBL_idx
if module_def['batch_normalize'] == '1':
CBL_idx.append(i)
else:
Conv_idx.append(i)
if module_defs[i+1]['type'] == 'maxpool':
#spp前一个CBL不剪
ignore_idx.add(i)
elif module_def['type'] == 'upsample':
#上采样层前的卷积层不裁剪
ignore_idx.add(i - 1)
elif module_def['type'] == 'shortcut':
# 根据cfg中的from层获得shortcut的卷积层对应的索引
identity_idx = (i + int(module_def['from']))
# 如果shortcut连接的是卷积层则直接添加索引
if module_defs[identity_idx]['type'] == 'convolutional':
#ignore_idx.add(identity_idx)
shortcut_idx[i-1]=identity_idx
shortcut_all.add(identity_idx)
# 如果shortcut连接的是shortcut层,则添加前一层卷积层的索引
elif module_defs[identity_idx]['type'] == 'shortcut':
#ignore_idx.add(identity_idx - 1)
shortcut_idx[i-1]=identity_idx-1
shortcut_all.add(identity_idx-1)
shortcut_all.add(i-1)
# 得到需要剪枝的BN层的索引
prune_idx = [idx for idx in CBL_idx if idx not in ignore_idx]
return CBL_idx, Conv_idx, prune_idx,shortcut_idx,shortcut_all
-
2、每次反向传播前,将L1正则产生的梯度添加到BN层的梯度中。
-
3、设置裁剪率进行裁剪。
-
将需要裁剪的层的BN层的γ参数的绝对值提取到一个列表并从小到大进行排序,若裁剪率0.8,则列表中0.8分位数的值为裁剪阈值。
# 提取需要裁剪的层的BN参数 bn_weights = gather_bn_weights(model.module_list, prune_idx) # 排序 sorted_bn, sorted_index = torch.sort(bn_weights) # 分位数索引 thresh_index = int(len(bn_weights) * opt.global_percent) thresh = sorted_bn[thresh_index].cuda() -
将小于裁剪阈值的通道提取出来;如果整层的通道γ均低于阈值,为了避免整层被裁剪,保留该层中γ值最大的几个(根据layer_keep参数进行设置,最小为1)通道。
def obtain_filters_mask(model, thresh, CBL_idx, prune_idx): pruned = 0 total = 0 num_filters = [] filters_mask = [] for idx in CBL_idx: bn_module = model.module_list[idx][1] # 如果该层需要裁剪,则先确定裁剪后的最小通道数min_channel_num,然后根据裁剪阈值进行通道裁剪确定mask,如果整层的通道γ均低于阈值,为了避免整层被裁剪,留该层中γ值最大的几个(根据layer_keep参数进行设置,最小为1)通道。 if idx in prune_idx: weight_copy = bn_module.weight.data.abs().clone() channels = weight_copy.shape[0] min_channel_num = int(channels * opt.layer_keep) if int(channels * opt.layer_keep) > 0 else 1 mask = weight_copy.gt(thresh).float() if int(torch.sum(mask)) < min_channel_num: _, sorted_index_weights = torch.sort(weight_copy,descending=True) mask[sorted_index_weights[:min_channel_num]]=1. remain = int(mask.sum()) pruned = pruned + mask.shape[0] - remain print(f'layer index: {idx:>3d} \t total channel: {mask.shape[0]:>4d} \t ' f'remaining channel: {remain:>4d}') # 如果该层不需要裁剪,则全部保留 else: mask = torch.ones(bn_module.weight.data.shape) remain = mask.shape[0] total += mask.shape[0] num_filters.append(remain) filters_mask.append(mask.clone()) -
合并shortcut层的mask,采用取并集的策略。
def merge_mask(model, CBLidx2mask, CBLidx2filters): # 最后一层开始遍历 for i in range(len(model.module_defs) - 1, -1, -1): mtype = model.module_defs[i]['type'] if mtype == 'shortcut': if model.module_defs[i]['is_access']: continue Merge_masks = [] layer_i = i # 循环的停止条件是到网络的feature map 发生下采样时 while mtype == 'shortcut': # 标志为true model.module_defs[layer_i]['is_access'] = True # 如果前一层为卷积层,添加该层上一层卷积层通道的mask if model.module_defs[layer_i-1]['type'] == 'convolutional': bn = int(model.module_defs[layer_i-1]['batch_normalize']) if bn: Merge_masks.append(CBLidx2mask[layer_i-1].unsqueeze(0)) # 找到和该层shortcut连接的层的索引 layer_i = int(model.module_defs[layer_i]['from'])+layer_i mtype = model.module_defs[layer_i]['type'] # 如果和shortcut连接的层为卷积层,则添加该层通道的mask;否则进入下一次while循环 if mtype == 'convolutional': bn = int(model.module_defs[layer_i]['batch_normalize']) if bn: Merge_masks.append(CBLidx2mask[layer_i].unsqueeze(0)) # 综合考虑所有feature map 大小相同(即通道数相同,不发生下采样)的shortcut层对应的卷积层通道的mask,只要一个为true则全部不剪裁 if len(Merge_masks) > 1: Merge_masks = torch.cat(Merge_masks, 0) merge_mask = (torch.sum(Merge_masks, dim=0) > 0).float() else: merge_mask = Merge_masks[0].float() layer_i = i mtype = 'shortcut' # 更新新的merge_mask while mtype == 'shortcut': if model.module_defs[layer_i-1]['type'] == 'convolutional': bn = int(model.module_defs[layer_i-1]['batch_normalize']) if bn: CBLidx2mask[layer_i-1] = merge_mask CBLidx2filters[layer_i-1] = int(torch.sum(merge_mask).item()) layer_i = int(model.module_defs[layer_i]['from'])+layer_i mtype = model.module_defs[layer_i]['type'] if mtype == 'convolutional': bn = int(model.module_defs[layer_i]['batch_normalize']) if bn: CBLidx2mask[layer_i] = merge_mask CBLidx2filters[layer_i] = int(torch.sum(merge_mask).item())
-
-
4、验证裁剪模型之后的MAP。
-
5、实际裁剪模型参数,β合并到下一个卷积层中BN中的running_mean计算。验证MAP,比较模型参数量及inference速度
-
6、创建新的模型结构,保存新的cfg及weights。
3、层剪枝
和优化的正常剪枝类似。这个策略是在之前的通道剪枝策略基础上衍生出来的,针对每一个shortcut层前一个CBL进行评价,对各层的Gmma均值进行排序,取最小的进行层剪枝。为保证yolov3结构完整,这里每剪一个shortcut结构,会同时剪掉一个shortcut层和它前面的两个卷积层。是的,这里只考虑剪主干中的shortcut模块。但是yolov3中有23处shortcut,剪掉8个shortcut就是剪掉了24个层,剪掉16个shortcut就是剪掉了48个层,总共有69个层的剪层空间;实验中对简单的数据集剪掉了较多shortcut而精度降低很少。
稀疏策略
scale参数默认0.001,根据数据集,mAP,BN分布调整,数据分布广类别多的,或者稀疏时掉点厉害的适当调小s;-sr用于开启稀疏训练;--prune 0适用于prune.py,--prune 1 适用于其他剪枝策略。稀疏训练就是精度和稀疏度的博弈过程,如何寻找好的策略让稀疏后的模型保持高精度同时实现高稀疏度是值得研究的问题,大的s一般稀疏较快但精度掉的快,小的s一般稀疏较慢但精度掉的慢;配合大学习率会稀疏加快,后期小学习率有助于精度回升。
注意:训练保存的pt权重包含epoch信息,可通过python -c "from models import *; convert('cfg/yolov3.cfg', 'weights/last.pt')"转换为darknet weights去除掉epoch信息,使用darknet weights从epoch 0开始稀疏训练。
1、恒定s
这是一开始的策略,也是默认的策略。在整个稀疏过程中,始终以恒定的s给模型添加额外的梯度,因为力度比较均匀,往往压缩度较高。但稀疏过程是个博弈过程,我们不仅想要较高的压缩度,也想要在学习率下降后恢复足够的精度,不同的s最后稀疏结果也不同,想要找到合适的s往往需要较高的时间成本。
bn_module.weight.grad.data.add_(s * torch.sign(bn_module.weight.data))
2、全局s衰减
关键代码是下面这句,在epochs的0.5阶段s衰减100倍。前提是0.5之前权重已经完成大幅压缩,这时对s衰减有助于精度快速回升,但是相应的bn会出现一定膨胀,降低压缩度,有利有弊,可以说是牺牲较大的压缩度换取较高的精度,同时减少寻找s的时间成本。当然这个0.5和100可以自己调整。注意也不能为了在前半部分加快压缩bn而大大提高s,过大的s会导致模型精度下降厉害,且s衰减后也无法恢复。如果想使用这个策略,可以在prune_utils.py中的BNOptimizer把下面这句取消注释。
# s = s if epoch <= opt.epochs * 0.5 else s * 0.01
3、局部s衰减
关键代码是下面两句,在epochs的0.5阶段开始对85%的通道保持原力度压缩,15%的通道进行s衰减100倍。这个85%是个先验知识,是由策略一稀疏后尝试剪通道几乎不掉点的最大比例,几乎不掉点指的是相对稀疏后精度;如果微调后还是不及baseline,或者说达不到精度要求,就可以使用策略三进行局部s衰减,从中间开始重新稀疏,这可以在牺牲较小压缩度情况下提高较大精度。如果想使用这个策略可以在train.py中把下面这两句取消注释,并根据自己策略一情况把0.85改为自己的比例,还有0.5和100也是可调的。策略二和三不建议一起用,除非你想做组合策略。
#if opt.sr and opt.prune==1 and epoch > opt.epochs * 0.5:
# idx2mask = get_mask2(model, prune_idx, 0.85)
知识蒸馏
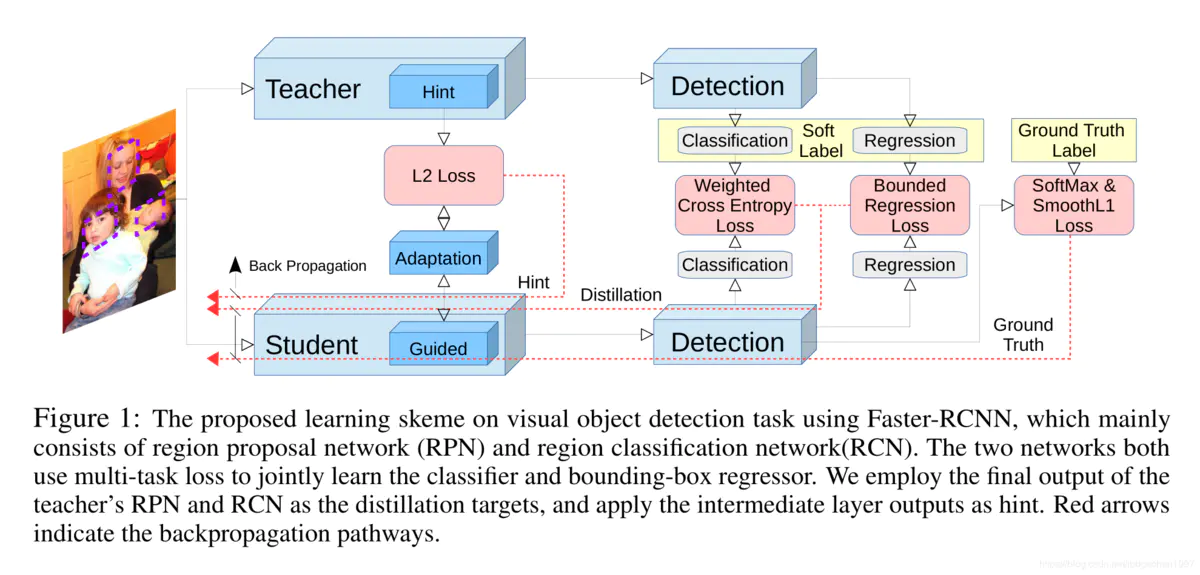
参考论文:Learning Efficient Object Detection Models with Knowledge Distillation。
核心思想:
- 对于obj和分类损失:将学生模型和老师模型的obj和分类的输出展开为一维向量,计算KL散度损失
- 对于Box损失:将学生模型xywh的输出x_offset,y_offset,w/grid_cell_w,h/grid_cell_h(这里是否有数量级的问题,似乎用归一化的欧式距离更好)分别和老师模型的输出、target计算L2距离,如果学生模型的输出,如果学生和老师更远,学生会再向target学习,而不是向老师学习。这时候老师的输出是hard label。
def distillation_loss2(model, targets, output_s, output_t):
'''
:param model: 学生模型
:param targets: 标签
:param output_s: 学生模型的输出
:param output_t: 老师模型的输出
:return: 附加Loss
'''
reg_m = 0.0
T = 3.0
Lambda_cls, Lambda_box = 0.0001, 0.001
# KL 损失,衡量两个分布的差异
criterion_st = torch.nn.KLDivLoss(reduction='sum')
ft = torch.cuda.FloatTensor if output_s[0].is_cuda else torch.Tensor
lcls, lbox = ft([0]), ft([0])
# 标签转换
tcls, tbox, indices, anchor_vec = build_targets(model, targets)
reg_ratio, reg_num, reg_nb = 0, 0, 0
for i, (ps, pt) in enumerate(zip(output_s, output_t)): # layer index, layer predictions
b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
nb = len(b)
if nb: # number of targets
pss = ps[b, a, gj, gi] # prediction subset corresponding to targets
pts = pt[b, a, gj, gi]
psxy = torch.sigmoid(pss[:, 0:2]) # pxy = pxy * s - (s - 1) / 2, s = 1.5 (scale_xy)
psbox = torch.cat((psxy, torch.exp(pss[:, 2:4]) * anchor_vec[i]), 1).view(-1, 4) # predicted box
ptxy = torch.sigmoid(pts[:, 0:2]) # pxy = pxy * s - (s - 1) / 2, s = 1.5 (scale_xy)
ptbox = torch.cat((ptxy, torch.exp(pts[:, 2:4]) * anchor_vec[i]), 1).view(-1, 4) # predicted box
l2_dis_s = (psbox - tbox[i]).pow(2).sum(1)
l2_dis_s_m = l2_dis_s + reg_m
l2_dis_t = (ptbox - tbox[i]).pow(2).sum(1)
l2_num = l2_dis_s_m > l2_dis_t
lbox += l2_dis_s[l2_num].sum()
reg_num += l2_num.sum().item()
reg_nb += nb
output_s_i = ps[..., 4:].view(-1, model.nc + 1)
output_t_i = pt[..., 4:].view(-1, model.nc + 1)
lcls += criterion_st(nn.functional.log_softmax(output_s_i/T, dim=1), nn.functional.softmax(output_t_i/T,dim=1))* (T*T) / ps.size(0)
if reg_nb:
reg_ratio = reg_num / reg_nb
return lcls * Lambda_cls + lbox * Lambda_box, reg_ratio
自己项目实验的总结:
一、测试环境
- 宿主机:Ubuntu 16.04, Docker环境:Ubuntu 16.04.6 LTS
- CPU:32 Intel(R) Xeon(R) CPU E5-2630 v3 @ 2.40GHz
- GPU:GTX 1080 8G
- CUDA_CUDNN:10.1.243,7.6.3.30
- Python:3.6.9
- onnx:1.4.1
- tensorrt:6.0.1.5
- pytorch:1.3.0
二、测试模型(YOLOV3)
模型采用pytorch框架训练、剪枝,转换为darknet模型,再转换成ONNX模型,最后转换为tensorrt模型。将以下六个模型依次命名为model1、model2、...、model6。
- Pytorch模型:model.pt
- Pytorch剪枝且微调模型:model_075.weights(转换为darknet格式)
- Tensorrt 模型:model_416416.trt(由model1转换)
- Tensorrt 模型:model_256416.trt(由model1转换)
- Tensorrt 模型:model_075_256416.trt(由model2转换)
- Tensorrt 模型:model_075_416416.trt(由model2转换)
三、测试结果
通过采用不同的输入形状(矩形和正方形)、不同的输入尺寸(320、416、608)、不同Batch Size(1、4、8、16)下对同一张图片采取循环推理1000次取平均时间,比较模型推理速度的差异。
注1:矩形输入指不改变宽高比的情况下,最长边resize到320、416、608,短边采用(128,128,128)填充至32的倍数。如输入尺寸为(720,1080)的720P图像,320、416、608分别对应(192, 320)、(256, 416)、(352, 608)。
注2:model3-6括号中的时间代表纯前向推理时间,batch size 均为1。
| Model | rec(1/4/8/16) [ms] | Square(1/4/8/16) [ms] |
|---|---|---|
| Model1(416) | 14.4/32.8/59.7/108.9 | 17.9/51.9/97.6/166.6 |
| Model1(608) | 21.3/63.8/122.5/196.9 | 31.1/105.3/205.5/322.2 |
| Model1(320) | 14.1/22.2/38.2/64.5 | 14.8/32.9/60.7/106.7 |
| Model2(416) | 13.9/21.6/39.9/76.6 | 14.4/33.4/63.9/124.7 |
| Model2(608) | 13.9/40.2/76.8/151.3 | 19.2/67.4/131.1/259.5 |
| Model2(320) | 13.9/14.0/24.1/44.9 | 14.3/20.9/38.3/73.6 |
| Model3和Model4(416) | 10.8(9.4) | 16.1(14.0) |
| Model5和Model6(416) | 8.4(6.4) | 12.1(9.7) |
四、测试结论
-
batch size 为 1 不能有效的利用显卡资源。通过多batch size 比较时间,矩形比正方形加速40%。(输入图片是16:9,矩形相对于正方形计算量少了43%)恰好证明了结论2。
-
当输入面积(N * H * W)大于一定值时,速度瓶颈才会出现在FLOPs上。详情请见,Roofline Model与深度学习模型的性能分析,模型的推理速度是由计算量为A且访存量为B的模型在算力为C且带宽为D的计算平台所能达到的理论性能上限E是多少决定的。
-
Tensorrt 可以降低模型的访存量,加速25%,但是似乎对模型计算量的降低非常有限。
-
通道剪枝可以降低模型的计算量和访存量,加速35%,但是在batch size 为 1时加速不明显,说明这次通道剪枝并没有优化模型的计算密度。和Ki和Ko的裁剪比例及大小有关。
-
若显卡的算力足够,提高batch size 为 1时的推理速度,核心是优化模型的访存量;提高多batch size时的推理速度核心是优化模型的计算量。
QA:
Q1:在做了矩形框输入和剪枝后,为什么batch size 为1时,320/416/608三种输入分辨率的前向推理的速度基本相同?
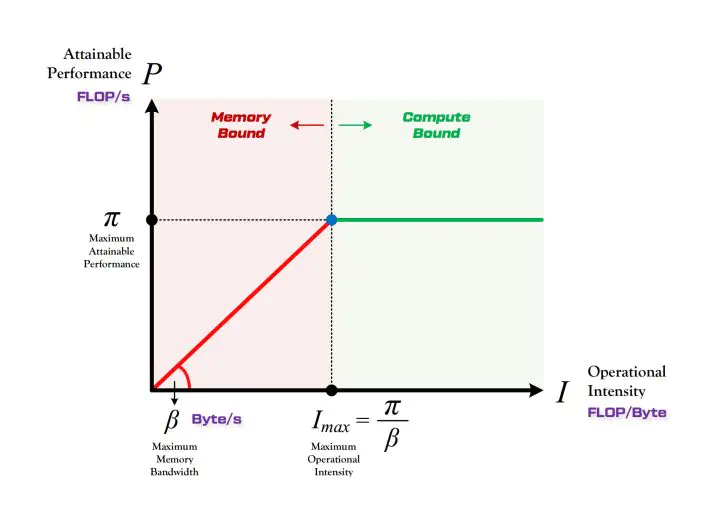
猜测:在计算量未达到GPU的瓶颈时,仅提高输入的分辨率而不改变模型,虽然计算密度基本不变(略微提高),但是实际带宽利用率会变大,所以FLOPS和FLOPs都会以相同的比例增长,因此最后的前向推理时间相同。
其中 表示计算密度,
表示输入通道数,
表示输出通道数,
表示卷积核的平面尺寸,
表示输出特征图的平面尺寸。仅当
改变时,计算密度基本不变,但是
表示实际带宽利用率变大,使得在相同的计算密度下FLOPs增大。
Q2:多batch size进行推理,为什么加速明显?
猜测:在多batch size中,FLOPS成倍增长但是时间却没有成倍增长,所以FLOPs提高。可能和Q1一样能够提高实际带宽利用率,并且由于模型参数均一致可以放入缓存中,同时降低访存量,提高了计算密度。
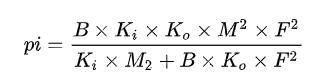
Q3:通道剪枝之后的模型,在320/416和未进行剪枝对比,batch size 为 1时前向推理速度基本相同?
猜测:FLOPS降低但是时间基本相同,说明FLOPs也同比例降低。
参考文献:
https://www.jianshu.com/p/d2d0d230eb74















 7054
7054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











