









前言
VGG参加2014年的ImageNet图像分类与定位挑战赛,取得了分类第二,定位第一的优秀成绩;
结构
VGG根据卷积核大小和卷积层数目不同,可以分为A,A-,LRN,B,C,D,E 6种,以D,E两种较为常用,分别称为VGG16和VGG19;
下图给出VGG的六种结构配置: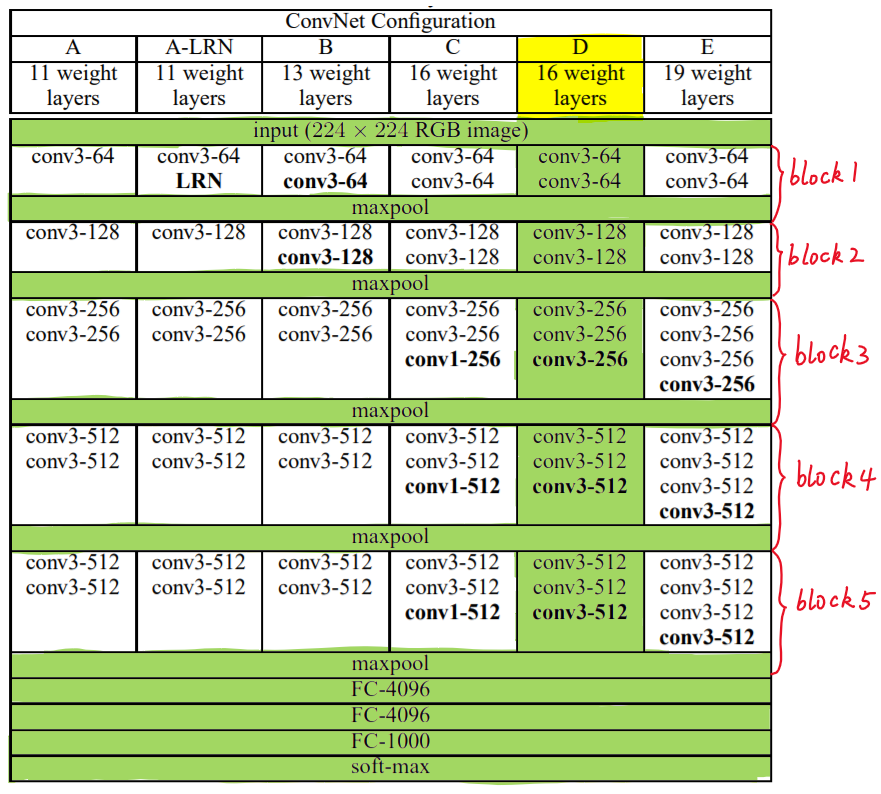
上图中,每一列对应一种结构配置,比如:图中的绿色部分即指明了VGG16所采用的结构;
针对其进行具体分析,可以看到VGG16共包含:
- 13个卷积层(Convolutional Layer),分别用conv3-xxx表示
- 3个全连接层(Fully connected Layer),分别用FC-XXXX表示
- 5个池化层(Pool Layer),用maxpool表示
其中,因为卷积层和全连接层都具有权重系数,因此也被称为权重层,可以得到13+3=16。[池化层不涉及权重]
特点
VGG16的突出特点为简单,体现在:
- 卷积层使用相同的卷积核参数。卷积层均表示为conv3-xxx,其中conv3表示卷积层采用的卷积核kernel size为3,3*3是很小的卷积核尺寸,结合其他参数(步幅stride=1,填充方式padding=same),就能保持每一个卷积层(张量)与前一层(张量)保持相同的宽和高,XXX代表卷积层的通道数。
- 池化层采用相同的池化核参数。池化层的参数均为2*2,步幅stride=2,max的池化方式,这样就能够使得每一个池化层(张量)的宽和高是前一层(张量)的????。
- 模型是由若干卷积层和池化层堆叠(stack)的方式构成,比较容易构成较深的网络结构;
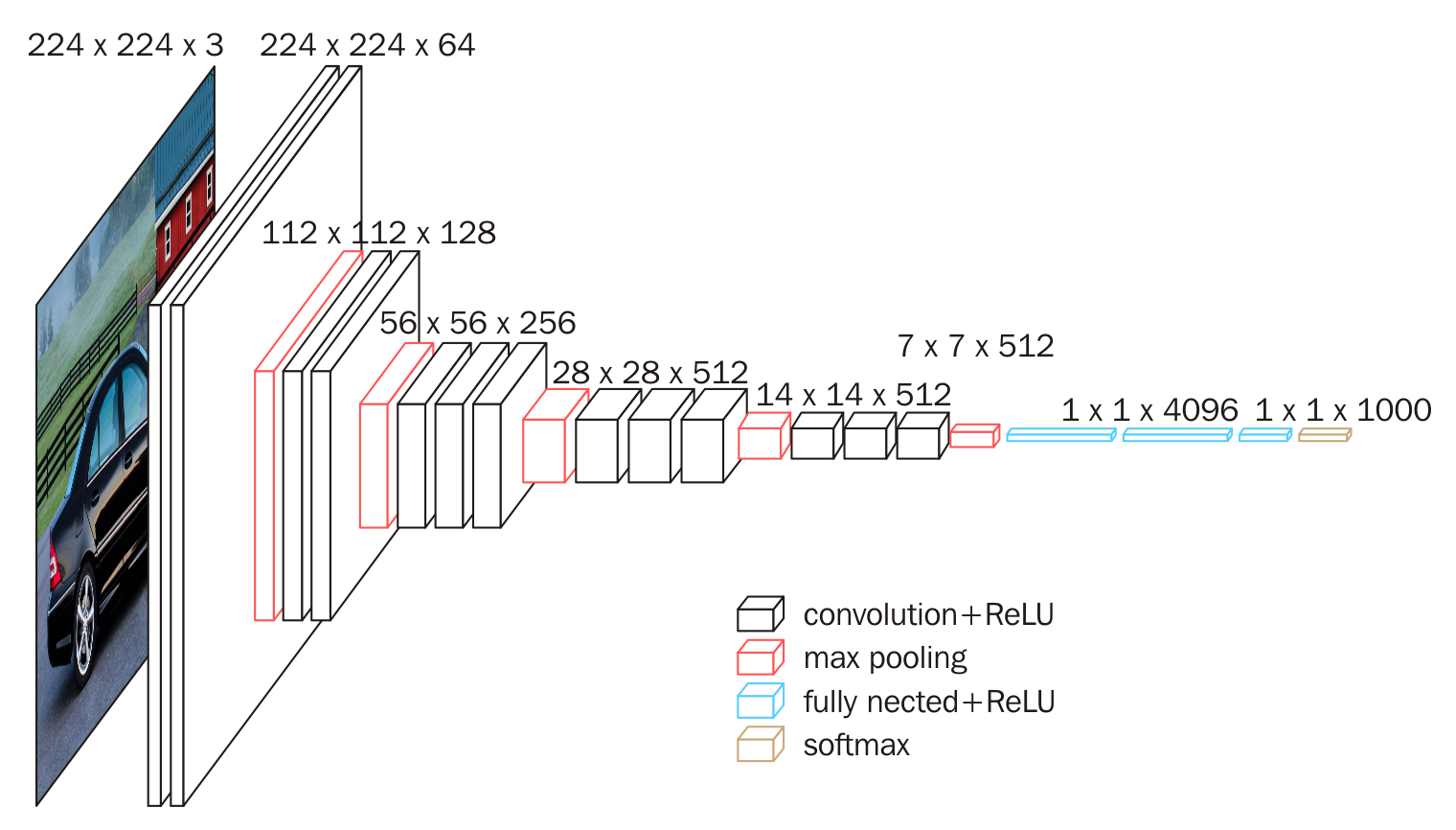
块的结构
第一张图片的右侧,VGG16的卷积层和池化层可以分成不同的Block,从上到下依次编号为Block1~block5;每一个块内包含若干卷积层和一个池化层;并且同一Block内,卷积层的通道(channel)数是相同的,例如:
- block2中包含2个卷积层,每个卷积层用convv3-128表示;即卷积核为3*3*3,通道数为128;
下图为按照块划分的VGG16结构图,可以结合第二张图进行理解: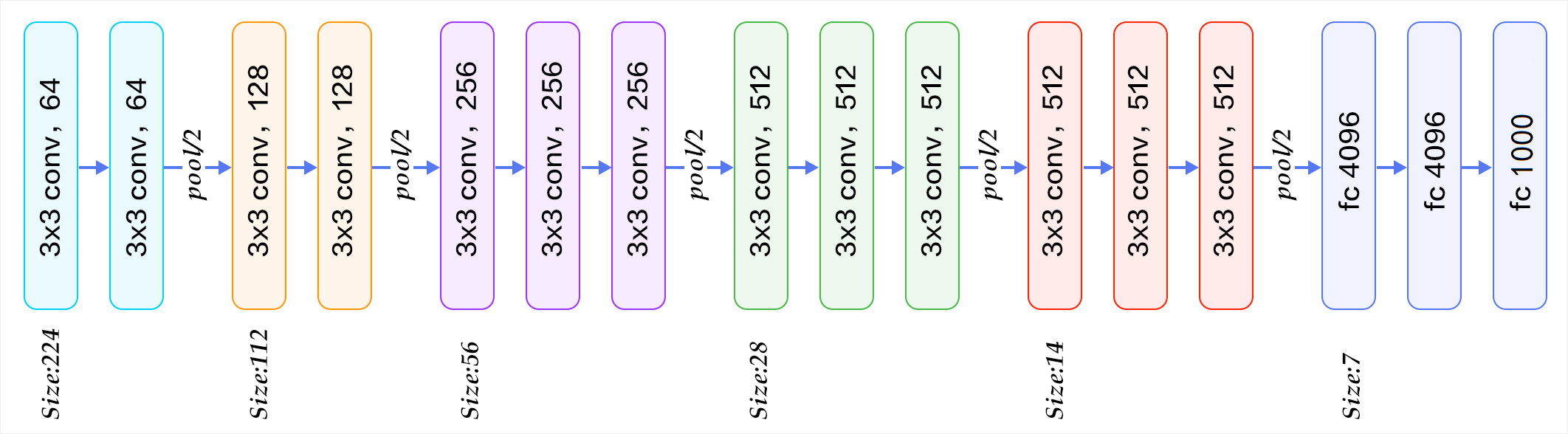
VGG的输入图像是244*244*3的图像张量,随着层数的增加,后一块内的张量相比于前一个块内的张量:
- 通道数翻倍,从64--128--256--512(保持)
- 高和宽变减半,由224--112--56--28--14--7
权重参数
VGG的结构虽然简单,但是所含的权重数目很大,达到惊人的139,357,544个参数,这些参数包括卷积核权重,全连接层权重。
- 例如:第一层卷积,输入图的通道数是3,网络必须学习大小为3*3,通道数为3的卷积核,这样的卷积核有64个,因此总共有(3*3*3)*64=1728个参数
- 计算全连接层的权重参数数目的方法为:前一层节点数*本层的节点数;因此全连接层的参数分别为:
7*7*512*4096;4096*4096;4096*1000;
FeiFei Li在CS231的课件中给出了整个网络的全部参数的计算过程(不考虑偏置),如下图所示:
图中蓝色是计算权重参数数量的部分;红色是计算所需存储容量的部分;
VGG16具有如此之大的参数数目,可以预期他具备很高的拟合能力;但同时具备了缺点:训练时间过长,需要的存储容量大;
实践
通过不断地卷积、池化来提取特征,通过全连接层以及softmax函数可以实现分类;根据结构来写代码,M代表最大池化,base里面定义了每一层通道数;
def vgg(cfg, i, batch_norm=False):
layers = []
in_channels = i
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v),nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Linear(512,4096)
conv7 = nn.Linear(4096,4096)
conv8 = nn.Linear(4096,1000)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True), conv8, nn.ReLU(inplace=True)]
return layers
base = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M',
512, 512, 512]
基于CIFAR-10数据集实现分类
import torch
import torch.nn as nn
from torch import optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
from tqdm import tqdm
'''定义超参数'''
batch_size = 256 # 批的大小
learning_rate = 1e-3 # 学习率
num_epoches = 100 # 遍历训练集的次数
'''
transform = transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean = [ 0.485, 0.456, 0.406 ],
std = [ 0.229, 0.224, 0.225 ]),
])
'''
'''下载训练集 CIFAR-10 10分类训练集'''
train_dataset = datasets.CIFAR10('./data', train=True, transform=transforms.ToTensor(), download=True)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataset = datasets.CIFAR10('./data', train=False, transform=transforms.ToTensor(), download=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
'''定义网络模型'''
class VGG16(nn.Module):
def __init__(self, num_classes=10):
super(VGG16, self).__init__()
self.features = nn.Sequential(
#1
nn.Conv2d(3,64,kernel_size=3,padding=1),
nn.BatchNorm2d(64),
'''在训练过程中,数据分布会发生变化,对下一层网络的学习带来困难。Batch Normalization将数据拉
回到均值为0,方差为1的正态分布上(归一化),一方面使得数据分布一致,另一方面避免梯度消失、梯度爆
炸。'''
nn.ReLU(True),
#2
nn.Conv2d(64,64,kernel_size=3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
#3
nn.Conv2d(64,128,kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
#4
nn.Conv2d(128,128,kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
#5
nn.Conv2d(128,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
#6
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
#7
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
#8
nn.Conv2d(256,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
#9
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
#10
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
#11
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
#12
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
#13
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.AvgPool2d(kernel_size=1,stride=1),
)
self.classifier = nn.Sequential(
#14
nn.Linear(512,4096),
nn.ReLU(True),
nn.Dropout(),
#15
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
#16
nn.Linear(4096,num_classes),
)
#self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
# print(out.shape)
out = out.view(out.size(0), -1)
# print(out.shape)
out = self.classifier(out)
# print(out.shape)
return out
'''创建model实例对象,并检测是否支持使用GPU'''
model = VGG16()
use_gpu = torch.cuda.is_available() # 判断是否有GPU加速
if use_gpu:
model = model.cuda()
'''定义loss和optimizer'''
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
'''训练模型'''
for epoch in range(num_epoches):
print('*' * 25, 'epoch {}'.format(epoch + 1), '*' * 25) # .format为输出格式,formet括号里的即为左边花括号的输出
running_loss = 0.0
running_acc = 0.0
for i, data in tqdm(enumerate(train_loader, 1)):
img, label = data
# cuda
if use_gpu:
img = img.cuda()
label = label.cuda()
img = Variable(img)
label = Variable(label)
# 向前传播
out = model(img)
loss = criterion(out, label)
running_loss += loss.item() * label.size(0)
_, pred = torch.max(out, 1) # 预测最大值所在的位置标签
num_correct = (pred == label).sum()
accuracy = (pred == label).float().mean()
running_acc += num_correct.item()
# 向后传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Finish {} epoch, Loss: {:.6f}, Acc: {:.6f}'.format(
epoch + 1, running_loss / (len(train_dataset)), running_acc / (len(train_dataset))))
model.eval() # 模型评估
eval_loss = 0
eval_acc = 0
for data in test_loader: # 测试模型
img, label = data
if use_gpu:
img = Variable(img, volatile=True).cuda()
label = Variable(label, volatile=True).cuda()
else:
img = Variable(img, volatile=True)
label = Variable(label, volatile=True)
out = model(img)
loss = criterion(out, label)
eval_loss += loss.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(
test_dataset)), eval_acc / (len(test_dataset))))
print()
# 保存模型
torch.save(model.state_dict(), './cnn.pth')结果展示
(由于本人电脑带不动,把Epoch改成20)
D:\VGG16\venv\Scripts\python.exe D:/VGG16/main.py
Files already downloaded and verified
Files already downloaded and verified
************************* epoch 1 *************************
782it [24:17, 1.86s/it]
Test Loss: 1.642333, Acc: 0.390700
************************* epoch 2 *************************
782it [18:56, 1.45s/it]
Finish 2 epoch, Loss: 1.541818, Acc: 0.429380
Test Loss: 1.504899, Acc: 0.452700
************************* epoch 3 *************************
782it [30:59, 2.38s/it]
Finish 3 epoch, Loss: 1.302713, Acc: 0.524280
Test Loss: 1.390377, Acc: 0.488000
************************* epoch 4 *************************
782it [30:20, 2.33s/it]
Finish 4 epoch, Loss: 1.139787, Acc: 0.587440
Test Loss: 1.444044, Acc: 0.489400
************************* epoch 5 *************************
782it [18:41, 1.43s/it]
Finish 5 epoch, Loss: 1.006991, Acc: 0.640920
0it [00:00, ?it/s]Test Loss: 1.122627, Acc: 0.600000
************************* epoch 6 *************************
782it [18:36, 1.43s/it]
Finish 6 epoch, Loss: 0.889473, Acc: 0.684000
0it [00:00, ?it/s]Test Loss: 1.399290, Acc: 0.534500
************************* epoch 7 *************************
782it [18:44, 1.44s/it]
Finish 7 epoch, Loss: 0.785274, Acc: 0.721920
0it [00:00, ?it/s]Test Loss: 1.046661, Acc: 0.633700
************************* epoch 8 *************************
782it [18:51, 1.45s/it]
Finish 8 epoch, Loss: 0.688535, Acc: 0.756460
0it [00:00, ?it/s]Test Loss: 1.060111, Acc: 0.652400
************************* epoch 9 *************************
782it [18:40, 1.43s/it]
Finish 9 epoch, Loss: 0.594265, Acc: 0.791100
0it [00:00, ?it/s]Test Loss: 1.010530, Acc: 0.655400
************************* epoch 10 *************************
782it [18:40, 1.43s/it]
Finish 10 epoch, Loss: 0.504314, Acc: 0.822940
0it [00:00, ?it/s]Test Loss: 1.903680, Acc: 0.509000
************************* epoch 11 *************************
782it [18:43, 1.44s/it]
Finish 11 epoch, Loss: 0.428687, Acc: 0.848480
0it [00:00, ?it/s]Test Loss: 1.145717, Acc: 0.652600
************************* epoch 12 *************************
782it [18:48, 1.44s/it]
Finish 12 epoch, Loss: 0.349519, Acc: 0.876460
Test Loss: 1.300202, Acc: 0.638100
************************* epoch 13 *************************
782it [18:41, 1.43s/it]
Finish 13 epoch, Loss: 0.272966, Acc: 0.906200
Test Loss: 1.025958, Acc: 0.706200
************************* epoch 14 *************************
782it [18:40, 1.43s/it]
Finish 14 epoch, Loss: 0.223521, Acc: 0.923620
Test Loss: 2.686784, Acc: 0.500500
************************* epoch 15 *************************
782it [18:34, 1.43s/it]
Finish 15 epoch, Loss: 0.179417, Acc: 0.940540
Test Loss: 1.121853, Acc: 0.712000
************************* epoch 16 *************************
782it [12:18:49, 56.69s/it]
Finish 16 epoch, Loss: 0.132646, Acc: 0.954180
0it [00:00, ?it/s]Test Loss: 1.269879, Acc: 0.702600
************************* epoch 17 *************************
782it [20:21, 1.56s/it]
Finish 17 epoch, Loss: 0.115610, Acc: 0.960840
Test Loss: 1.200604, Acc: 0.722800
************************* epoch 18 *************************
782it [20:40, 1.59s/it]
Finish 18 epoch, Loss: 0.099715, Acc: 0.964880
Test Loss: 1.644888, Acc: 0.651000
************************* epoch 19 *************************
782it [20:54, 1.60s/it]
Finish 19 epoch, Loss: 0.086601, Acc: 0.970900
0it [00:00, ?it/s]Test Loss: 1.844185, Acc: 0.656200
************************* epoch 20 *************************
782it [19:55, 1.53s/it]
Finish 20 epoch, Loss: 0.072556, Acc: 0.978360
Test Loss: 1.343983, Acc: 0.719900
Process finished with exit code 0
后验证,100个Epoch,结果为
Finish 100 epoch, Loss: 0.000004, Acc: 1.000000
Test Loss: 2.109977, Acc: 0.766200
170500096it [5:54:05, 8025.12it/s] 














 7228
7228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









