







随着人工智能热潮的发展,图像识别已经成为了其中非常重要的一部分。图像识别是指计算机对图像进行处理、分析,以识别其中所含目标的类别及其位置(即目标检测和分类)的技术。其中图像分类是图像识别的一个类,是给定一幅测试图像,利用训练好的分类器判定它所属的类别。
该项目分为三部分:
- 第一部分:系统驱动的安装与环境的搭建
- 第二部分:利用VGG16网络进行模型训练与预测
- 第三部分:通过模型算法的部署,实现模型预测的页面可视化
本文主要讲解的是项目中的第二部分,其余两部分可通过Github了解
项目中所有的代码及数据集已放入Github
数据集的获取
本文的数据集中包含五个类,分别是Animal(动物)、Architecture(建筑)、people(人)、plane(飞机)、Scenery(风景)。由于身边条件的欠缺,数据集的获取途径主要通过爬取百度图片的方式获取,并将相同类的图片放在同一文件夹(代码:Reptile_img.py)。
爬取一个类示例:
注意:保存的图片采用英文格式,不然后续无法利用OpenCV读入。
数据集的清洗及读取
由于获取的图片数据集较为杂乱,所以我们需要人为清洗数据,以提高数据集的准确性。而后,数据集中可能会存在无法利用OpenCV读取的图片,我们采取遍历所有文件,并将其读入,将无法读入显示的图片删除,保证数据集的正确性(代码:open_img.py)。
将所有图片读取示例:

出现下方错误证明是爬取的图片无法读入,找到相对应的图片删除就好。

数据增强
清洗处理以后,我们五个类的图片集数量分别为:
| 类别 | 数量 |
|---|---|
| Animal | 500张 |
| Architecture | 500张 |
| people | 700张 |
| plane | 500张 |
| Scenery | 700张 |
总体来说,数据集的数量太少,得出的模型可能存在模型泛化能力不强的情况。所以利用数据增强,对图片集进行随即旋转、平移变换、缩放变换、剪切变换、水平翻转等等操作,使得每张数据集得到50张处理后的图片,并保存在原本的文件夹下,整个数据集得到扩大(代码:data_augmentation.py)。
代码示例:
from keras.preprocessing.image import ImageDataGenerator
import os
import cv2
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.15,
height_shift_range=0.15,
zoom_range=0.15,
shear_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
dir = './data/'
path = os.path.abspath(dir)
all_file = os.listdir(dir)
all_file.sort()
i = 0
for file1 in all_file:
# print(file1)
img_file = os.listdir(os.path.join(path, file1))
img_file.sort()
for file2 in img_file:
img = cv2.imread(os.path.join(path, file1, file2))
x = img.reshape((1,) + img.shape) # datagen.flow要求rank为4 (1, x.shape)
datagen.fit(x)
prefix = file2.split('.')[0] # 以 . 分离字符串,去掉后缀
counter = 0
for batch in datagen.flow(x, batch_size=32, save_to_dir=dir + all_file[i], save_prefix=prefix, save_format='jpg'):
counter += 1
print(file2, '======', counter)
if counter > 30:
break # 否则生成器会退出循环
i += 1
rotation_range=20 图片随机旋转20°
width_shift_range=0.15 图片宽度随机水平偏移0.15
height_shift_range=0.15 图片高度随机竖直偏移0.15
zoom_range=0.15 随机缩放幅度为0.15
shear_range=0.2 剪切强度为0.15
horizontal_flip=True 随机对图片进行水平翻转
模型训练
利用处理好的数据集导入Keras自带VGG16网络结构,进行模型训练,并将模型保存。为了方便后续的调参,将每次不同batch、epoch、size的测试loss、accuracy写入txt文本,最后通过不断调参画出折线图,得出最佳的一个模型(代码:TrainAndTest_VGG.py)。
将五个类的文件夹按ASCII大小排序,并输出相对应的标签
def CountFiles(path):
files = []
labels = []
path = os.path.abspath(path)
subdirs = os.listdir(path)
# print(subdirs)
subdirs.sort()
for index in range(len(subdirs)):
subdir = os.path.join(path, subdirs[index])
sys.stdout.flush()
print("label --> dir : {} --> {}".format(index, subdir))
for image_path in glob.glob("{}/*.jpg".format(subdir)):
files.append(image_path)
labels.append(index)
# 将标签与数值对应输出
return files, labels, len(subdirs)

将数据集中每张图片的数据与对应的标签绑定,随机打乱后将标签转为One-Hot码。
files, labels, clazz = CountFiles(r"data")
c = list(zip(files, labels))
random.shuffle(c)
files, labels = zip(*c) # 数值与标签绑定,并随机打乱
labels = np.array(labels)
labels = keras.utils.to_categorical(labels, clazz) # 将标签转为One-Hot码
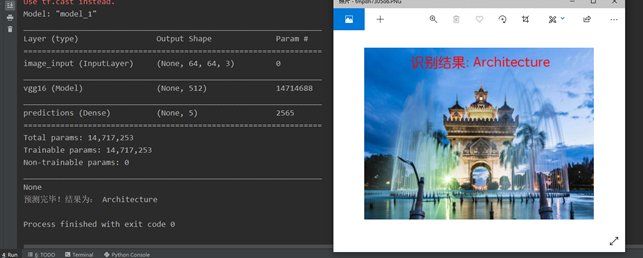
加载模型并预测展示
选取五个类中的一个类的图片,加载模型训练中loss较低accuracy较高的模型,将结果可视化在原有图片上,结果完全吻合实际(代码:Predict.py)。

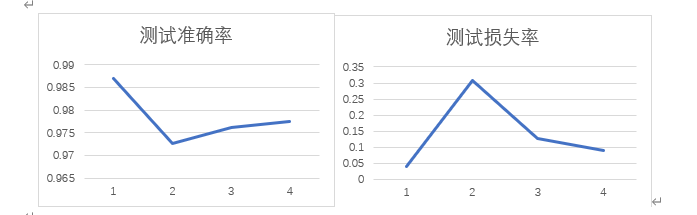
训练准确率折线图绘制
将模型batch、size参数进行多次修改,得出下图每次训练得到的最好模型准确率与损失率,并绘制相对应的折线统计图,可以发现,当batch=25,size=(64, 64)时,得到的训练准确率最高,损失率也较低,所以最终我们采用batch=25,size=64*64的模型。
















 370
370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









