







目录
1 语言处理与python
自然语言工具包(NLTK)入门
NLTK定义了一个使用Python进行NLP编程的基础工具。自带大量文档http://www.nltk.org网站提高的API文档。

安装
从http://www.nltk.org/免费下载适合的版本,进行安装。
或者直接在cmd/pycharm终端中书写命令 pip install nltk,后打开python解释器输入两行命令来安装本书所需的数据,然后选择book,如下图所示:


如果输入完两行命令后跳出11004 error:
解决方法:
1、先在自己的电脑里创建一个上图中Download Directory路径下的nltk_data文件夹
2、在在系统中找到 hosts 文件
Window:C:\Windows\System32\drivers\etc\hosts
Linux:/etc/hosts
Mac:/etc/hosts
注:遇到权限不够需要管理员权限才能修改,可以把hosts文件移到桌面上,修改后再移回去。或者在文件的属性下把用户权限改为可修改。
在最后添加 199.232.68.133 raw.githubusercontent.com(这里的ip写按照下面方法查询到的) 保存后打开命令行执行ipconfig/flushdns 进行刷新。
这里我们可以在谷歌网址输入 raw.githubusercontent.com.ipaddress.com 将查询到的ip地址都按照上面的格式写入hosts文件中。
3、再次输入nltk.download()即可


如果还是不能成功安装,经常中途报错,建议直接下载nltk_data提取码k12t ,放置刚刚创建的nltk_data文件夹中。
nltk_data的路径问题解决方法:
from nltk import data
data.path.append(r"C:\Users\admin\AppData\Roaming\nltk_data")
测试是否安装成功:

一些函数
函数括号中写a代表需要填写参数
搜索文本
- concordance(a) :词语索引,连同上下文和单词一起显示。
from nltk.book import *
text1.concordance("monstrous")
- similar(a) : 查询哪些词出现在相似的上下文中。
- common_contexts(a) : 研究两个或两个以上的词共同的上下文。格式如下:
from nltk.book import *
text2.common_contexts(["monstrous","very"])
- dispersion_plot(a) : 通过离散图表示词的位置信息,每一竖线代表一个单词,每一行代表整个文本。

- generate() : 产生随机文本。标点符号被从前面的词分裂出去。
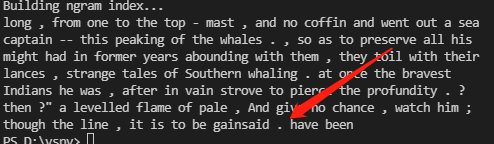
计数词汇
-
len(a) : 获取文本从头到尾的长度,也是词数。
-
set(a) : 获得a的词汇表,不包含重复的词。
-
sorted(set(a)) :得到词汇项的排序表,这个表以各种标点符号开始,然后是以A开头的词汇,大写单词排在小写单词前面。
词类型:一个词在一个文本中独一无二的出现形式或拼写。不包括标点符号。
-
count(a) :计数一个词在文本中出现的次数。
将文本当作词链表
链表
- 创建文本链表
sent1 = ['call', 'me', 'dualcircles', ','] - 加号+ : 连接两个链表。
- append(a) : 向链表中追加一个元素。
sent1.append(["da", "af"])
索引列表
索引:这个词的位置次序数字。从0开始
是一种常见的用来获取文本中词汇的方式。访问链表中元素的方式。
- index(a) : 找出词a第一次出现的索引
- 切片 sent[m:n] : 表示sent句子中包含索引m、m+1…n-1的句子元素(左闭右开)
[:3] : 省略第一个数字,表示切片从链表第一个元素开始
[141:] :省略第二个数字,表示切片到链表最后一个元素处结尾
可以通过切片来整体替换一整个片段。
变量
必须以字母开头,可以包含数字和下划线。变量名不能是python的保留字,如def、if等
字符串
- join(a) : 把词用链表连接起来组成单个字符串
print(''.join(['yaya', 'liuwen'])) #''引号中间可以填写用来连接词语 - split() :将字符串分割成一个链表。
print('yaya liuwen'.split())
简单的统计
频率分布
- FreqDist(a) : 统计文本a中出现的词的频率。 得到的是一个字典类型,如:{’,’:19,‘the’:18…}
- items() : 查看FreqDist得到的条例
print(fdist1.items()) - keys() : 获取文本中不重复的词类型形成链表。以频率递减的顺序。
注:在python3中keys不允许切片,先转List再切片就好了
结果:fdist1 = FreqDist(text1) word1 = fdist1.keys() print(list(word1)[:50])
- 累积频率图
fdist1.plot(50, cumulative=True) # 去掉参数cumulative就是频率分布图。
- hapaxes() : 查看只出现过一次的词
细粒度的选择词
V=set(text1)
long_words = [w for w in V if len(w)>15]
fdist5 = FreqDist(text5)
print(sorted([w for w in set(text5) if len(w)>7 and fdist5[w]>7) )# 长度超过7个字符并且出现次数超过7词的词
词语搭配和双连词
- bigrams(a) :双连词
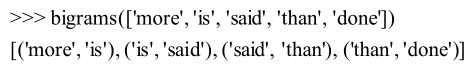
- collocations() :统计文本中频繁的双连词
print(text4.collocations())
计数其他东西


决策控制

自动理解自然语言
词意消歧:要算出特定上下文中的词被赋予的是哪个意思。
指代消解:确定代词或名词短语指的是什么。
语义角色标注:确定名词短语如何与动词相关联。
自动生成语言:自动问答、机器翻译。
机器翻译:
人机对话系统
获得文本语料和词汇资源
古腾堡语料库:
nltk.corpus.gutenberg.fileids() 太繁琐可以
from nltk.corpus import gutenberg
print(gutenberg.fileids())
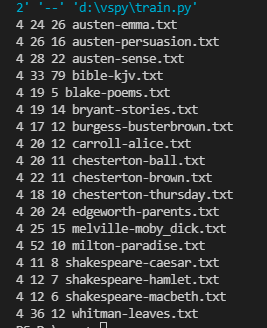
for fileid in gutenberg.fileids():
num_charts = len(gutenberg.raw(fileid))
num_words = len(gutenberg.words(fileid))
num_sents = len(gutenberg.sents(fileid))
num_vocab = len(set([w.lower() for w in gutenberg.words(fileid)]))
print(int(num_charts / num_words), int(num_words / num_sents),
int(num_words / num_vocab), fileid)# 平均词长、平均句子长度、本文中每个词出现的平均次数
raw() 函数 给我们没有进行过任何语言学处理的文件的内容。
len(gutenberg.raw(‘blake-poems.txt’))即是告诉我们文本中出现的词汇的个数,包括词之间的空格。
sents()函数把文本划分成句子,其中每一个句子是一个词链表。
网络和聊天文本
网络文本小集合:

消息聊天会话语料库:

布朗语料库



路透社语料库
包含10788个新闻文档,这些文档分成90个主题,按照“训练”和“测试”分成两组。

就职演说语料库
55个文本的集合,每个文本都是一个总统的演说。特性是它的时间维度。

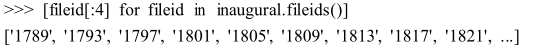
标注文本语料库
许多文本语料库都包含语言学标注,有词性标注、命名实体、句法结构、语义角色等。
NLTK中提供了很方便的方式来访问这些语料库中的几个。有关下载信息请参阅http://www.nltk.org/data ,在http://www.nltk.org/howto查阅HOWTO。
其他语言的语料库
在使用其他语言的语料库之前需要学习如何在python中处理字符编码(见第三章)。
这些语料库的最后,Udhr,是超过300种语言的世界人权宣言。这个语料库的fileids包括有关文件所使用的字符编码,如UTF8或者Latin1。
- “世界人权宣言”的6个翻译版本的累积字长分布:

文本语料库的结构
下图为文本预料库的常见结构


载入自己的语料库
待更…















 7556
7556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









