







一、前言
针对Policy iteration 中存在的exploitation问题,在第五章中将强化学习算法分为on-policy算法和off-policy算法。前两章中,我们讨论了对on-policy问题的函数逼近,本章中将重点介绍off-policy问题的函数逼近。两者差异很大。第六章、第七章中出现的 tabular off-policy 方法很容易用semi-gradient方法进行扩展,但在off-policy下算法的收敛性比on-policy下差。本章我们研究收敛问题,加深对线性逼近的了解,介绍 learnable的概念,然后介绍一个对 off-policy而言,收敛性强的新算法。
回忆在off-policy learning 中,我们需要用behavior policy b b 生成的数据来学习target policy 的value function。在prediction 问题中,两个policy都是给定且不变的,我们需要找到特定的state value v̂ ≈vπ v ^ ≈ v π 或action value q̂ ≈qπ q ^ ≈ q π 。在control 问题中,要学习action value,两个policy在学习过程中都是变化的—— π π 是 q̂ q ^ 的greedy policy , b b 则是另外一些探索性比较强的策略如 的 ϵ ϵ -greedy policy。
off-policy learning 的挑战分为两大类:一类出现在表格化问题(tabular case) 中,与update target有关,另一类出现在函数逼近中,与update distribution有关。第5章和第7章中介绍的方法解决了第一类问题,本章第一节将探讨这些方法与函数逼近的结合。
但off-policy learning的函数逼近相比on-policy learning 需要一些其他东西,因为其中的update distrbution不再是on-policy distribution。on-policy distribution 起到了平衡对semi-gradinet的作用,在off-policy learning中,有两个方法可以用于解决该问题:
- 一个是第5章和第7章中介绍的importance sampling,此处将update distribution变为 on-policy distribution,保证了算法的收敛性。
- 另个一是开发一种不依赖于任何特定分布的 true gradient f方法。
二、Semi-gradient Methods
首先,我们开始讨论前几章中提到的off-policy 方法与函数逼近如semi-gradient方法的结合。这些方法重点针对 off-policy的第一类挑战,(不断变化的update targets),而非针对第二类挑战(不断变化的update distribution),因此,对某些任务而言,这些方法会发散,但很多情况下表现良好。对tabular case是函数逼近的特例,使用这些方法可以确保稳定且无偏。所以可以用合适的特征选择方法,将两者结合起来得到一个稳定的系统。
在第7章中,我们讨论了很多 tabular off-policy 算法,将他们与semi-gradient算法结合,可以将更新(V 或 Q)变为用value function的逼近( v̂ v ^ 或 q̂ q ^ )的梯度来更新( w w )。这些算法大部分都采用了per-step importance sampling ratio:
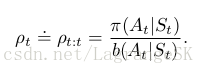
one-step state-value 算法 semi-gradient off-policy TD(0):
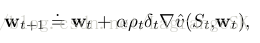
其中:
episodic and discounted problem:
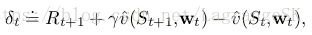
continuing and undiscounted problem:
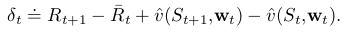
action values, the one-step algorithm is semi-gradient Expected Sarsa:
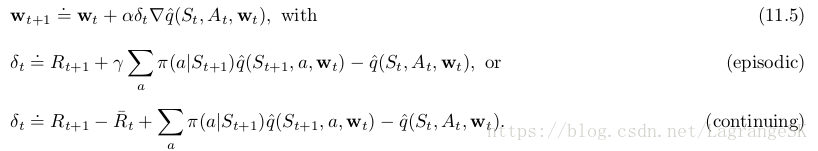
注意,这里并没有使用importance sampling。在tabular case中,很明显不需要用importance sampling,因为只有一个sample action At A t ,在学习这个action value 时,不需要考虑到其他的action。对函数逼近问题而言,不太明显,因为在进行一个全局逼近时,我们可能希望不同的state-action pairs有不同的权重。等我们更深入理解强化学习函数逼近思想时再说明更合适的处理方式,。
对muti-step 算法的泛化,无论是state value 还是 action value都需要importance sampling。
the n-step version of semi-gradient Expected Sarsa:
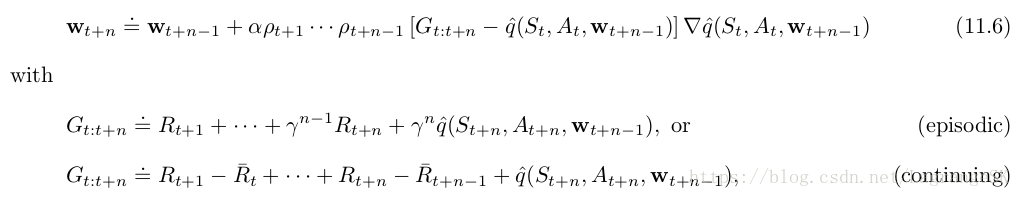
回忆第7章中不使用 importance sampling的off-policy 算法:n-step tree-backup算法。
the n-step version of semi-gradient tree-backup:
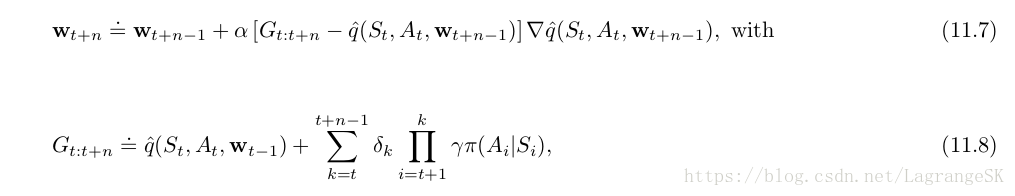
三、Examples of Off-policy Divergence
本节我们开始讨论使用函数逼近的 off-policy learning 的第二类挑战。这里的update distribution 不再满足 on-policy distribution。我们先来看一些使用 semi-gradient 或其他算法导致不稳定或不收敛的off-policy learning 反例。
先来看一个简单的例子。假设在一个大型MDP中,有两个states的估计 value function 是w 和2w的函数如下图,此处的参数矩阵 w w 仅仅包含一个量 w。本例中,特征向量值分别为1和2。在first state处,只有一个可行的action,执行这个action就一定会以reward为0转移到 second state。

假设初始时刻 w=10 w = 10 ,从estimated value为10的state转移到estimated value为20的state。看起来似乎是一个不错的转移,w会增加,first state 的estimate value会随之增加。如果 γ γ 接近1,那么TD error接近10,如果 α=0.1 α = 0.1 ,那么w以减小TD error为目标,会增加到接近11。second state的estimate value也会增加,接近22。如果再次转移,那么将从 ≈11 ≈ 11 的state转移到 ≈22 ≈ 22 的state,TD error ≈11 ≈ 11 ——比第一次转移大。first state 的value会再次增加到 ≈12.1 ≈ 12.1 。这样循环往复 w w 会增加到无穷大。
为了详细说明发生了什么,我们来看一下数学表达。TD error为:
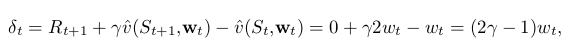
off-policy semi-gradient TD(0)的更新为:
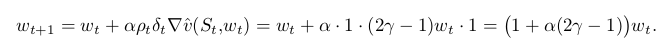
注意,本例中的 为1,因为在first state只有一个action,所以target 和 behavior policy下选择action的概率都是1。更新后的权重是更新前的 (1+α(2γ−1)) ( 1 + α ( 2 γ − 1 ) ) ,如果该值大于1,那么系统将不稳定,w会发散于无穷大。此处,当 γ>0.5 γ > 0.5 时,该值大于1。这表明系统是否稳定不依赖于step size( α>0 α > 0 ),step size的大小只能影响w趋于正无穷的速度,不会影响w是否收敛。
这个例子的关键在于一直在重复一个状态转移下更新 w。这在off-policy learning 下是可能发生的,因为 behavior policy可能会选择target policy永远不会选择的那些 action。对于这些转移而言, ρt ρ t 可能为0,且这些转移上的权重不会更新。在 on-policy training中, ρt ρ t 总是1,那么从estimated value为10的state转移到estimated value为20的state会提升 w,则一定会有2w state之外的状态转移,这个转移会减小w。在on-policy中,future reward 会被传承下去,且系统会进行检查,但在off-policy中,future reward 虽然也可能被传承下去,但一旦选择action 后,future reward可能被遗忘了( ρt=0 ρ t = 0 )。
这个简单的例子说明了off-policy training为什么会发散的一些原因,但并不完整。因为他只是MDP中的一部分,会存在完全不稳定的系统吗?举个完全发散的例子——Baird’s counterexample。考虑一个有七个states,两个action的episodic问题,如图11.1所示。
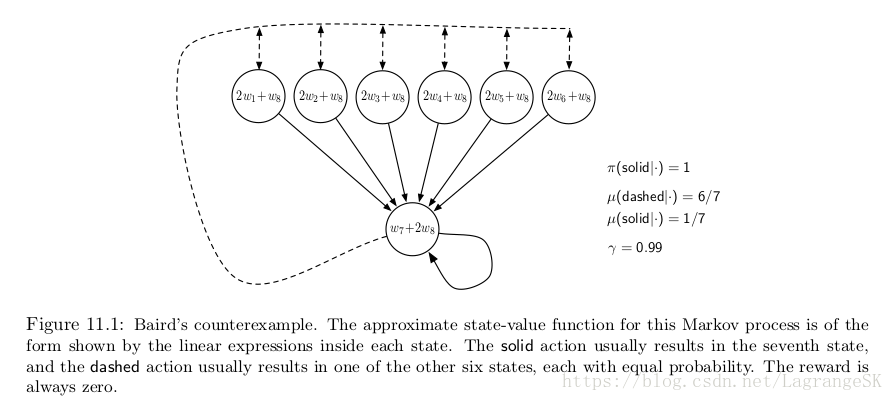
虚线的action等可能的将state带向上面6个states,而实线的action 将state带向第7个state,behavior policy b选择虚线或实线的概率分别为 67 6 7 和 17 1 7 ,是均匀分布。target policy π π 则总是选择 实线action,也就是说 on-policy distribution 只能到第7个state,所有的状态转移reward 均为0,dicount rate γ=0.99 γ = 0.99 。
state-value的线性估计表示在圆圈内部。例如,最左侧的state estimated value为 2w1+w8 2 w 1 + w 8 ,对应的特征向量为 x(1)=(2,0,0,0,0,0,0,1)T x ( 1 ) = ( 2 , 0 , 0 , 0 , 0 , 0 , 0 , 1 ) T ,由于所有的状态转移reward 均为0,所以所有state s 的true value function vπ(s)=0 v π ( s ) = 0 ,当 w=0 w = 0 时被准确估计。 事实上,很多问题中,权重向量的维度(8维度)大于 state的维度(7维度)。这也就是说 { x(s):s∈S} { x ( s ) : s ∈ S } 是线性独立的。这个例子比较像我们用线性函数逼近时遇到的一般情况。
如果,我们此时采用 semi-gradient TD(0),那么权重会发散到无穷大。无论采用多大的正向 step size都会发散。如果采用DP形式更新:
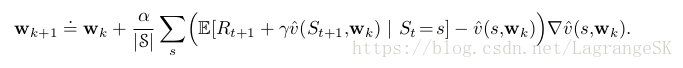
也会发散。
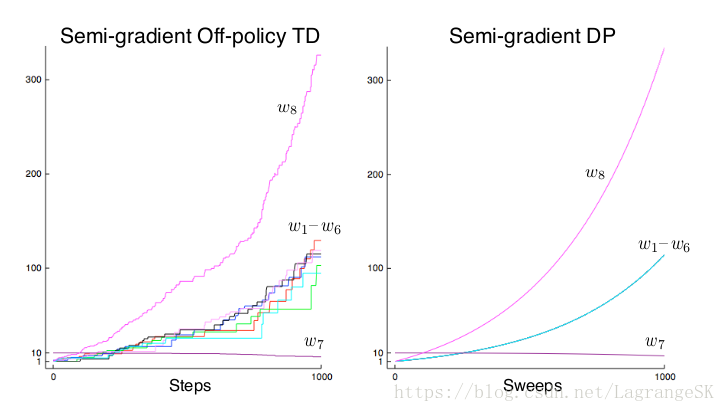
如果我们将Baird’s counterexample中的DP update distribution变成 on-policy distribution,模型会收敛。TD 和DP方法是最简单易懂的bootstrapping方法,线性semi-gradient是最简单的函数逼近方法,这两者在update distribution 不满足 on-policy distribution情况下的结合都会导致算法不稳定。
还有一个与 Baird’s counterexample类似的 counterexample表示了使用Q-learning的发散,这值得我们注意,因为Q-learning是收敛性最好的control 方法。考虑如何补救的思路一般是使得behavior policy 和target policy足够接近,如 ϵ ϵ -greedy policy。接下来,我们介绍另外一些思想。
假设和 Baird’s counterexample不同,不再是每次迭代都朝着 expected one-step return 前进一步,现在以最小均方根误差为标准来改变 value function。这会改善不稳定问题吗?当 {
x(s):s∈S} { x ( s ) : s ∈ S } 线性独立时(如 Baird’s counterexample中)当然可以。因为每次迭代都会使得准确度上升,使得tabular DP的平均值下降。但这个例子中,即使这么处理了,还是不能保证系统稳定,如图所示:

另一种防止系统不稳定的方法是采用特殊的函数逼近方法,尤其是不用observed target进行预测的函数逼近方法,这些方法被称为 averages,包括最近邻方法和locally weighted regression,但不包括 tile coding 和 artificial neural network。
四、The Deadly Triad
上一小节中,我们举例说明了系统存在不稳定性的情况,本节对系统不稳定性情况进行整体归纳分析。可能导致系统不稳定的元素有三——死亡三元素:
Function Approximation(函数逼近)、Bootstrapping 和off-policy training,当三者同时出现时,会导致系统不稳定,而只出现其中两个时,系统会稳定,那么如何取舍?
首先,function approximation不能被舍弃,我们需要用他来泛化强化学习方法,扩展强化学习的应用,至少需要一个线性函数逼近。 State aggregation(聚类)或非参数化的方法随着数据增加复杂度增加,且效果不是太强就是不足,Least-square 方法如LSTD的计算复杂度太高。
不用 bootstrapping是可以的,但是要牺牲计算效率和数据利用率。首先来看计算效率,MC方法需要记忆库来存储每次预测和最终返回值间的所有信息,当获得最终返回值时,完成所有运算,对计算机硬件要求高。在bootstrapping和 eligibility trace(第12章会谈到)中,数据都是用完就丢弃的,不需要很多存储空间。
不用bootstrapping的数据利用率损失也是不可忽略的,在第7章和第9章中的random-walk例子中,一些 bootstrapping方法表现比MC方法好。实验结果表明 bootstrapping方法的学习速度更快,原因在于他可以利用最终返回值之前的states特性来进行学习。但bootstrapping在state没有明确表达的问题(仅仅知道特征向量的情况)中表现不好,会导致一些不好的泛化。总体来说,boostrapping方法是很有价值的,但可以选择用 n-step updates来取代单步更新。
最后,我们来看 off-policy learning,我们可以放弃吗?On-policy方法通常情况下足够强大。对 model-free 强化学习问题来说,我们可以使用Sarsa而不是 Q-learning。off-policy 方法将target policy和behavior policy区别开来,会使得运用变得简单,但不是必须的。但 off-policy learning 对一类预测问题来说十分有效,这类问题书中没有提到,但对构建更有智慧的高级智能体来说十分重要。
在这类问题中,agent 不仅学习一个value function和单个policy,而是要并行学习一系列的 value function和Policy。这基于人和动物的可以通过学习来预测不同事件(不仅仅是预测reward)的普遍真理。我们对不寻常的事件表示惊讶,然后会更正我们对事物的预测,无论往好预测还是往坏预测。这种预测假设是规划中预测模型的基础。我们根据眼睛看到的场景进行预测,如估计需要多长时间走回家,打篮球时篮球跳起的可能性,对新接收项目的满意度。这些任务中,需要预测的事件和我们的行为密切相关。如何并行的学习他们?需要从一部分经验中学习,此时有很多target policy,一个behavior policy不可能平等的对待他们,并行学习的behavior policy 可以部分重叠这些target policies,为了并行学习,需要使用 off-policy learning。
五、Linear Value-function Geometry
为了更好的理解 off-policy learning 所面临的稳定性挑战,将value function approximation 独立与learning 之外,进行抽象分析。假设一个state space中的所有state-value function 都是实数 v:S→R v : S → R ,且大部分value function 不对应任何 policy。我们的目标不再是找到一个可以用的函数逼近,而是找到一个参数小于states个数的函数逼近。
假设有一个state space S=s1,s2,...,s|S| S = s 1 , s 2 , . . . , s | S | ,任何value function v v 都相当于一个由每个state value以此组成的矢量(vector) 列表 [v(s1),v(s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4298
4298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









