







后来想到了一维的方式,除内核与上面那方式不同外,其他的都相同:
内核如下;
const char *KernelSource=
"__kernel void add(__global int *outputB,__global int *inputA)"
"{"
" int i=get_global_id(0);"
" if(i<=3||(i>=8&&i<=11)||(i>=16&&i<=19)||(i>=24&&i<=27))"
" outputB[i]=inputA[i]+1;"
" else if((i>=4&&i<=7)||(i>=12&&i<=15)||(i>=20&&i<=23)||(i>=28&&i<=31))"
" outputB[i]=inputA[i]+2;"
" else if((i>=32&&i<=35)||(i>=40&&i<=43)||(i>=48&&i<=51)||(i>=56&&i<=59))"
" outputB[i]=inputA[i]+3;"
" else"
" outputB[i]=inputA[i]+4;"
"};";
这是通过观察需要变换的外置间的关系写的,但感觉这样做效率就体现不出来,因为感觉判断语句的内容太长了,感觉不是那么好,那能不能从二维的角度来看看呢?
于是我就换了种思路,就有了下面这种:
const char *KernelSource=
"__kernel void add(__global int *outputB,__global int *inputA)"
"{"
" int i=get_global_id(0);"
" int j=get_global_id(1);"
" if(i<4&&j<4)"
" outputB[i*8+j]=inputA[i*8+j]+1;"
" else if(i<4&&j>=4)"
" outputB[i*8+j]=inputA[i*8+j]+2;"
" else if(i>=4&&j<4)"
" outputB[i*8+j]=inputA[i*8+j]+3;"
" else "
" outputB[i*8+j]=inputA[i*8+j]+4;"
"}";
虽然分支跟上面类似但写法上感觉简练些了,
整个源代码如下:
#include<stdio.h>
#include<stdlib.h>
#include<CL/cl.hpp>
//矩阵变换
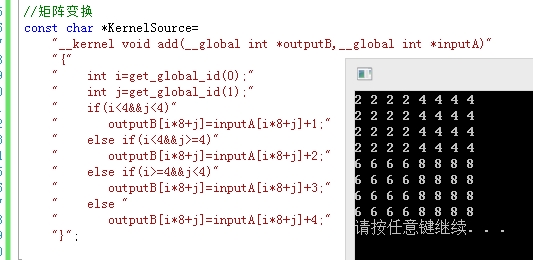
const char *KernelSource=
"__kernel void add(__global int *outputB,__global int *inputA)"
"{"
" int i=get_global_id(0);"
" int j=get_global_id(1);"
" if(i<4&&j<4)"
" outputB[i*8+j]=inputA[i*8+j]+1;"
" else if(i<4&&j>=4)"
" outputB[i*8+j]=inputA[i*8+j]+2;"
" else if(i>=4&&j<4)"
" outputB[i*8+j]=inputA[i*8+j]+3;"
" else "
" outputB[i*8+j]=inputA[i*8+j]+4;"
"}";
int main()
{
const int Row=8;
const int Line=8;
int i,j;
const size_t datasize=sizeof(int)*Row*Line;
int A[Row][Line]=
{
1,1,1,1,2,2,2,2,
1,1,1,1,2,2,2,2,
1,1,1,1,2,2,2,2,
1,1,1,1,2,2,2,2,
3,3,3,3,4,4,4,4,
3,3,3,3,4,4,4,4,
3,3,3,3,4,4,4,4,
3,3,3,3,4,4,4,4
};
int B[Row][Line];
cl_int err;
cl_platform_id platform;
err=clGetPlatformIDs(1,&platform,NULL);
cl_device_id device;
err=clGetDeviceIDs(platform,CL_DEVICE_TYPE_GPU,1,&device,NULL);
cl_context context;
context=clCreateContext(NULL,1,&device,NULL,NULL,&err);
cl_command_queue cmdQueue;
cmdQueue=clCreateCommandQueue(context,device,NULL,&err);
cl_mem BufferA;
cl_mem BufferB;
BufferA=clCreateBuffer(context,CL_MEM_READ_ONLY,datasize,NULL,&err);
BufferB=clCreateBuffer(context,CL_MEM_WRITE_ONLY,datasize,NULL,&err);
err=clEnqueueWriteBuffer(cmdQueue,BufferA,CL_TRUE,0,datasize,A,0,NULL,NULL);
cl_program program;
program=clCreateProgramWithSource(context,1,&KernelSource,NULL,&err);
err=clBuildProgram(program,1,&device,NULL,NULL,NULL);
cl_kernel kernel;
kernel=clCreateKernel(program,"add",&err);
err=clSetKernelArg(kernel,0,sizeof(cl_mem),&BufferB);
err=clSetKernelArg(kernel,1,sizeof(cl_mem),&BufferA);
size_t globalWorkSize[2]={8,8};
err=clEnqueueNDRangeKernel(cmdQueue,kernel,2,NULL,globalWorkSize,NULL,0,NULL,NULL);
err=clEnqueueReadBuffer(cmdQueue,BufferB,CL_TRUE,0,datasize,B,0,NULL,NULL);
for(i=0;i<Row;i++)
{
for(j=0;j<Line;j++)
{
printf("%d ",B[i][j]);
}
printf("\n");
}
system("pause");
}















 2783
2783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









