







正文
本文将使用PyTorch和torchtext构建一个机器学习模型,这里的例子是德语和英语之间的翻译。
以RNN为例, 效果如图:

每个句子加了开始与结束标志
RNN接受序列后的输出送到下个RNN作为隐层,这部分叫编码,隐层输入到下个RNN,对于训练过程这个RNN的输入也是安排好的, 叫做解码。
这里黄色的是embedding层,输入与输出的embedding层不一样。
对于语言来说我们需要建立一个叫 tokenizers 的东西, 可以把句子分为token 。 e.g. “good morning!” 变为 [“good”, “morning”, “!”]
作者发现反转句子可能是有用的, 可以把德语变为token后反转再复制。
- 还有 index, 对每个token有不同的index
- 使用BucketIterator而不是标准 Iterator ,因为它创建批处理的方式使源语句和目标语句中的填充量最小化
- 使用迭代器得到实例时需要填充保证所有源语句padding到同样的长度,target也同样, 但这里BucketIterator 实现了已经。
数据处理部分
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.legacy.datasets import Multi30k
from torchtext.legacy.data import Field, BucketIterator
import spacy
import numpy as np
import random
import math
import time
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
# spacy为每种语言提供了模型, 加载这些模型后可以访问每个模型的 tokenizers
spacy_de = spacy.load('de_core_news_sm')
spacy_en = spacy.load('en_core_web_sm')
# 创建tokenize 函数。它们可以传递给torchtext,
# 并将句子作为string接收,并将句子作为list返回。
def tokenize_de(text):
"""
Tokenizes German text from a string into a list of strings (tokens) and reverses it
"""
return [tok.text for tok in spacy_de.tokenizer(text)][::-1]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings (tokens)
"""
return [tok.text for tok in spacy_en.tokenizer(text)]
# 德语作为source, 英语作为target, 将其都变为小写lowercase
SRC = Field(tokenize = tokenize_de,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)
TRG = Field(tokenize = tokenize_en,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)
print(f"Number of training examples: {len(train_data.examples)}")
print(f"Number of validation examples: {len(valid_data.examples)}")
print(f"Number of testing examples: {len(test_data.examples)}")
print(vars(train_data.examples[0])) # 输出的是倒叙的德语和正序英语
>>
>> Number of training examples: 29000
>> Number of validation examples: 1014
>> Number of testing examples: 1000
>> {'src': ['.', 'büsche', 'vieler', 'nähe', 'der', 'in', 'freien', 'im', 'sind', 'männer', 'weiße', 'junge', 'zwei'], 'trg': ['two', 'young', ',', 'white', 'males', 'are', 'outside', 'near', 'many', 'bushes', '.']}
# 这就是构建索引吧,将每个token和索引关联 这里还用了minfreq参数,出现次数小于2次的token被转换为<unk>标记
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)
print(f"Unique tokens in source (de) vocabulary: {len(SRC.vocab)}")
print(f"Unique tokens in target (en) vocabulary: {len(TRG.vocab)}")
>> Unique tokens in source (de) vocabulary: 7853
>> Unique tokens in target (en) vocabulary: 5893
# 准备数据的最后一步是创建迭代器,返回的数据带有src属性(就是数字化的源语句)还有trg属性(就是数字化的目标语句)
# 数字化就是建立索引那一步.
# 使用BucketIterator而不是标准 Iterator ,因为它创建批处理的方式使源语句和目标语句中的填充量最小化
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
构建seq2seq模型

- encoder 是这样, 输入有结束和开始标志
# 这里使用的是最后的隐藏状态
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
# src = [src len, batch size]
embedded = self.dropout(self.embedding(src))
# embedded = [src len, batch size, emb dim]
outputs, (hidden, cell) = self.rnn(embedded)
# outputs = [src len, batch size, hid dim * n directions]
# hidden = [n layers * n directions, batch size, hid dim]
# cell = [n layers * n directions, batch size, hid dim]
# outputs are always from the top hidden layer
return hidden, cell
# 这里每次只解码一个token,所以seq是1
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
# input = [batch size]
# hidden = [n layers * n directions, batch size, hid dim]
# cell = [n layers * n directions, batch size, hid dim]
# n directions in the decoder will both always be 1, therefore:
# hidden = [n layers, batch size, hid dim]
# context = [n layers, batch size, hid dim]
input = input.unsqueeze(0)
# input = [1, batch size]
embedded = self.dropout(self.embedding(input))
# embedded = [1, batch size, emb dim]
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
# output = [seq len, batch size, hid dim * n directions]
# hidden = [n layers * n directions, batch size, hid dim]
# cell = [n layers * n directions, batch size, hid dim]
# seq len and n directions will always be 1 in the decoder, therefore:
# output = [1, batch size, hid dim]
# hidden = [n layers, batch size, hid dim]
# cell = [n layers, batch size, hid dim]
prediction = self.fc_out(output.squeeze(0))
# prediction = [batch size, output dim]
return prediction, hidden, cell
seq2seq
# 这部分实现要确保编码器和解码器的层数和hidden还有cell的维度要相等,首先要建立一个向量Y存储所有的预测项
# 解码器这部分是有一个循环:
# -将输入、先前隐藏和先前单元状态传递到解码器中
# -从解码器接收预测、下一个隐藏状态和下一个单元状态
# -把我们的预测y放在Y中
# - 有个参数**teacher force**
# 如果我们这样做了,下一个输入就是序列中的下一个基本真值标记,y/trg[t]
# 否则,下一个输入是序列中预测的下一个标记,y/top1,我们通过对输出张量执行argmax得到
# 我们的解码器循环从1开始,而不是0。这意味着输出张量的第0个元素保持为全零。
# 输入到decoder的最后一个是eos之前的值, eos不被输入到decoder
# 所以我们的trg和输出看起来像下图:
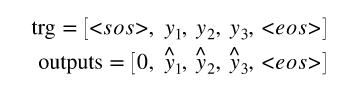
# 稍后当我们计算损耗时,我们切下每个张量的第一个元素,得到
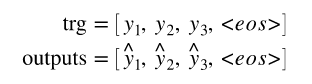
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
assert encoder.hid_dim == decoder.hid_dim, \
"Hidden dimensions of encoder and decoder must be equal!"
assert encoder.n_layers == decoder.n_layers, \
"Encoder and decoder must have equal number of layers!"
def forward(self, src, trg, teacher_forcing_ratio=0.5):
# src = [src len, batch size]
# trg = [trg len, batch size]
# teacher_forcing_ratio is probability to use teacher forcing
# e.g. if teacher_forcing_ratio is 0.75 we use ground-truth inputs 75% of the time
batch_size = trg.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
# tensor to store decoder outputs
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
# last hidden state of the encoder is used as the initial hidden state of the decoder
hidden, cell = self.encoder(src)
# first input to the decoder is the <sos> tokens
input = trg[0, :]
for t in range(1, trg_len):
# insert input token embedding, previous hidden and previous cell states
# receive output tensor (predictions) and new hidden and cell states
output, hidden, cell = self.decoder(input, hidden, cell)
# place predictions in a tensor holding predictions for each token
outputs[t] = output
# decide if we are going to use teacher forcing or not
teacher_force = random.random() < teacher_forcing_ratio
# get the highest predicted token from our predictions
top1 = output.argmax(1)
# if teacher forcing, use actual next token as next input
# if not, use predicted token
input = trg[t] if teacher_force else top1
return outputs
训练过程
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
HID_DIM = 512
N_LAYERS = 2
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT)
model = Seq2Seq(enc, dec, device).to(device)
# 从-0.08到+0.08之间的均匀分布初始化所有权重
def init_weights(m):
for name, param in m.named_parameters():
nn.init.uniform_(param.data, -0.08, 0.08)
model.apply(init_weights)
# 定义一个函数来计算模型中可训练参数的数量。
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
optimizer = optim.Adam(model.parameters())
# 使用CrossEntropyLoss, 如果是<pad>部分就忽略
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)
# training loop
# 当我们计算损失时,我们切断每个张量的第一个元素,得到
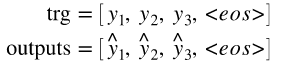
'''
在每次迭代中:
从批中获取源句子和目标句子,然后
将最后一批计算的梯度归零
将源和目标输入模型以获得输出,
由于损失函数仅适用于具有1d目标的2d输入,因此我们需要使用.view将每个目标展平
我们切掉输出和目标张量的第一列,如上所述
用loss.backward()计算梯度
clip the gradients 以防止其爆炸(RNNs中的常见问题)
通过执行优化器步骤来更新模型的参数
将损失值加总成
'''
















 7555
7555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











