







文章目录
3DMM是什么
3DMM(3D Morphable Model)是一种较为基础的三维人脸统计模型,最早被提出是用于解决从二维人脸图像恢复三维形状的问题。
传统3DMM方法
一般将人脸分为了两种向量:
-
一种是形状向量(shape-vector),包含了 X , Y , Z X , Y , Z X,Y,Z 坐标信息, 使用 n n n个顶点的三维坐标对三维人脸的形状进行表示:
S = ( X 1 , Y 1 , Z 1 , X 2 , Y 2 , Z 2 , . . . . . . . , X n , Y n , Z n ) T S = (X_1, Y_1, Z_1, X_2, Y_2, Z_2,.......,X_n, Y_n, Z_n)^T S=(X1,Y1,Z1,X2,Y2,Z2,.......,Xn,Yn,Zn)T
这里的n指的是模型的顶点数,同以下纹理向量的n. -
另一种是纹理向量(texture-vector), 包含了 R , G , B R , G , B R,G,B 颜色值信息:
T = ( R 1 , G 1 , B 1 , R 2 , G 2 , B 2 , . . . . . . . R n , G n , B n ) T T= (R_1, G_1, B_1, R_2, G_2, B_2, .......R_n, G_n, B_n)^T T=(R1,G1,B1,R2,G2,B2,.......Rn,Gn,Bn)T
在有了以上的表示方法后,我们使用的建立三维形变的脸部模型由
m
m
m个脸部模型组成,其中每一个都包含相应的
S
i
,
T
i
S_{i}, T_{i}
Si,Ti两种向量。这样在表示新的三维脸部模型的时候,我们可以用以下的方式表示:
S
n
e
w
M
o
d
e
l
=
∑
i
=
1
m
a
i
S
i
S_{newModel}= \sum_{i=1}^{m} a_iS_i
SnewModel=i=1∑maiSi
T
n
e
w
M
o
d
e
l
=
∑
i
=
1
m
b
i
T
i
T_{newModel}= \sum_{i=1}^{m} b_iT_i
TnewModel=i=1∑mbiTi
其中,
∑
i
=
1
m
a
i
=
∑
i
=
1
m
b
i
=
1
\sum_{i=1}^{m} a_{i} = \sum_{i=1}^{m}b_{i} = 1
∑i=1mai=∑i=1mbi=1
原文这里的m是“exemplar faces”的个数,我的理解是采集的人脸样本数
那么变形模型的定义:根据系数 a ⃗ = ( a 1 , a 2 , . . . , a m ) T \vec a= ( a_1 , a_2 , . . . , a_m )^T a=(a1,a2,...,am)T 和 b ⃗ = ( b 1 , b 2 , . . . , b m ) T \vec b={(b_1,b_2,...,b_m)}^T b=(b1,b2,...,bm)T 产生的一系列人脸 ( S m o d e l ( a ⃗ ) (S_{model} (\vec a) (Smodel(a), T m o d e l ( b ⃗ ) ) T_{model}(\vec b)) Tmodel(b)), 不同的系数 a ⃗ \vec a a和 b ⃗ \vec b b会产生不同的形状和纹理。
PCA降维
构建模型的时候不能直接用这里的
S
i
,
T
i
S_{i}, T_{i}
Si,Ti作为基向量, 因为它们之间不是正相关的, 所以需要用PCA进行降维分解.
在讲解PCA之前简单了解一下特征值和特征向量, 具体可参见我的另一篇文章
- 首先明确特征值和特征向量是对谁而言的呢, 是对一个变换矩阵而言的, 特征值表示变换矩阵能起到多大作用, 特征值越大代表对应的变化程度越剧烈, 那么具体是变化谁呢? 就是变换的特征向量.
也就是说, 特征值是用来衡量变换矩阵对特征向量的变换程度
以下的步骤均为PCA算法流程,
- 计算 S ˉ , T ˉ \bar S, \bar T Sˉ,Tˉ
- 中心化人脸数据, 求得 △ S = S i − S ˉ \triangle S = S_{i} - \bar S △S=Si−Sˉ, △ T = T i − T ˉ \triangle T = T_{i} - \bar T △T=Ti−Tˉ
- 分别计算协方差矩阵 C S , C T C_{S}, C_{T} CS,CT
- 求得相应协方差矩阵的特征值和特征向量
在完成以上步骤的后,新的脸部模型的就可以用以下的公式进行表示:
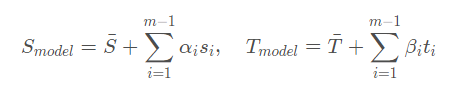
其中,
α
\alpha
α,
β
\beta
β,
s
s
s,
t
t
t 分别为协方差矩阵
C
S
,
C
T
C_{S}, C_{T}
CS,CT 的特征值和特征向量。有很多资料是这样写的,但是我感觉
α
\alpha
α,
β
\beta
β 应该并不像特征值, 应该是可变的
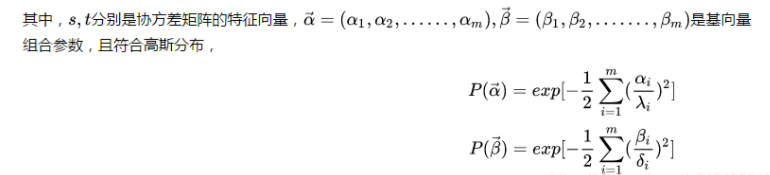
在开源的2009版BFM的里,采集了200个人脸样本数据,得到的特征向量数量是199个. 进行PCA降维保证了得到的特征向量是线性无关的, 取前几个s, t的分量就可以对原始样本做很好的近似.
但注意, 尽管有了上面的特征值以及m−1个互不相交的子空间,仍然还是无法直接和具体人脸的眼睛、鼻子等联系对应起来。
模型求解问题分析
线性表示中有一个纹理部分,但是拟合效果往往不够好,一般直接从照片中提取纹理进行贴合,因此这里只考虑重建人脸形状的部分
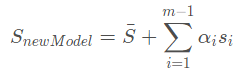
14年的时候,FacewareHouse这篇论文提出并公开了一个人脸表情数据库,使得3DMM有了更强的表现力。从而人脸模型的线性表示可以扩充为:
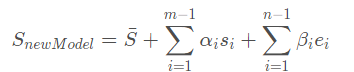
加入了e(expression,表情), 于是人脸重建问题转为了求
α
,
β
\alpha , \beta
α,β 系数的问题。
得到一张单张正脸照片,可以从里面得到人脸的68个特征点坐标(X,Y),在BFM模型中有对应的68个特征点( X 3 d X_{3d} X3d),根据这些信息便可以求出 α , β \alpha , \beta α,β系数,将平均脸模型与照片中的脸部进行拟合。
- 具体求解过程如下:
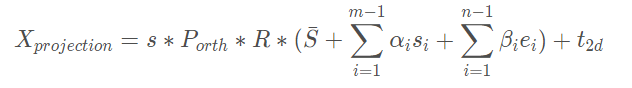
X p r o j e c t i o n X_{projection} Xprojection是三维模型投影到二维平面的点, P o r t h P_{orth} Porth = [ [ 1 , 0 , 0 ] , [ 0 , 1 , 0 ] ] [ [ 1 , 0 , 0 ] , [ 0 , 1 , 0 ] ] [[1,0,0],[0,1,0]]为正交投影矩阵, R ( 3 , 3 ) R(3,3) R(3,3)为旋转矩阵, t 2 d t_{2d} t2d 为位移矩阵, s是scale。
于是乎,再一次三维求解问题又可以转化为求解满足以下的能量方程的系数
(
s
,
R
,
t
2
d
,
以
及
α
和
β
)
({s, R, t_{2d}}, 以及\alpha和 \beta)
(s,R,t2d,以及α和β)
也就是说, 从2d照片得到3d参数的过程需要的是landmarks和3d的landmarks
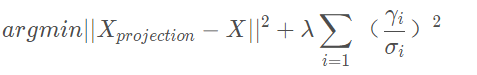
这里加了正则化部分,其中
γ
\gamma
γ是PCA系数(包括形状系数
α
\alpha
α以及表情系数
β
\beta
β),
σ
\sigma
σ表示对应的主成分偏差。即,由上式求解使得三维模型中的68特征点投影到二维平面上的值与二维平面原68个特征点距离相差最小的系数。
具体参数 ( s , R , t 2 d , α , β ) ({s, R, t_{2d}}, \alpha, \beta) (s,R,t2d,α,β)的求解
可以把参数分为三个部分,
s
,
R
,
t
2
d
{s, R, t_{2d}}
s,R,t2d 以及
α
,
β
\alpha, \beta
α,β。
求解方法如下:
- 将α, β 初始化为0
- 求出 s , R , t 2 d {s, R, t_{2d}} s,R,t2d
- 将上一步求出的 s , R , t 2 d {s, R, t_{2d}} s,R,t2d代入,求出α
- 将之前求出的 s , R , t 2 d {s, R, t_{2d}} s,R,t2d以及α代入,求出β
- 利用求得的α以及β,重复2-4步骤进行迭代。
估计 s , R , t 2 d {s, R, t_{2d}} s,R,t2d
人脸模型的三维点以及对应照片中的二维点存在映射关系,这个可以由一个3x4的仿射矩阵进行表示。即:
x
2
d
=
P
∗
X
3
d
x_{2d}=P∗X_{3d}
x2d=P∗X3d
P即是我们需要求得仿射矩阵,作用在三维坐标点上可以得到对应二维点的坐标。
使用黄金标准算法(Gold Standard algorithm) 来求解该仿射矩阵, 有什么DLT啥的, 有点复杂, 先放着了.
算法如下:
目标: 给定n>=4组3维
(
X
i
)
(X_i)
(Xi)到 2维
(
x
i
)
(x_i)
(xi)的图像点对应,确定仿射摄像机投影矩阵的最大似然估计。
- 归一化,对于二维点
(
x
i
)
(x_i)
(xi)计算一个相似变换T,使得
x
ˉ
=
T
x
i
\bar x = T x_{i}
xˉ=Txi
,同样的对于三维点,计算 X ˉ = U X i \bar X = U X_{i} Xˉ=UXi - 对于每组对应点 x i x_{i} xi 对应于 X i X_{i} Xi,都有上图方程的对应关系存在,形如 A x = b A x = b Ax=b
- 求出A的伪逆
- 去掉归一化,得到仿射矩阵
- 得到仿射矩阵P之后,需要将P进行分解,得到缩放系数s,旋转矩阵R,以及位移矩阵t
估计 α \alpha α和 β \beta β
A
=
s
∗
P
∗
R
A=s∗P∗R
A=s∗P∗R
b
=
s
∗
P
∗
R
∗
(
S
ˉ
+
e
β
)
+
t
2
d
b = s * P * R * ( \bar S + e \beta) + t_{2d}
b=s∗P∗R∗(Sˉ+eβ)+t2d
可以得到,
X
p
r
o
j
e
c
t
i
o
n
=
A
∗
s
α
+
b
X_{projection} = A * s \alpha + b
Xprojection=A∗sα+b
- 以BFM模型为例,设模型顶点总数为n, 得到各个参数的维数为:
s (3n x 199)
α (199 x 1)
A (2 x 3)
在进行
A
∗
s
α
A * s \alpha
A∗sα的时候,需要后者进行一下变换,否则不满足矩阵相乘要求。
s
h
a
p
e
=
r
e
s
h
a
p
e
(
s
α
)
shape=reshape(sα)
shape=reshape(sα)
使得(3n x 1)—>(3 x n)
A * shape的维数为(2 x n)
为了求解方便,对A * shape, b进行reshape使其维数变为(2n x 1), 得到
x
f
l
a
t
t
e
n
=
A
∗
s
h
a
p
e
+
b
f
l
a
t
t
e
n
x_{flatten}=A∗shape+b_{flatten}
xflatten=A∗shape+bflatten
未完待续, 这个地方不太理解
附录: PCA详解
矩阵相乘的意义
两个向量的 A 和 B 内积我们知道形式是这样的:
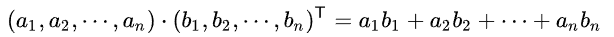
内积运算将两个向量映射为实数,从几何角度来分析,为了简单起见,我们假设 A 和 B 均为二维向量,则:
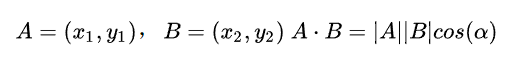
其几何表示见下图:

我们看出 A 与 B 的内积等于 A 到 B 的投影长度乘以 B 的模。
如果假设 B 的模为 1,即让 ∣ B ∣ = 1 |B|=1 ∣B∣=1 ,那么就变成了:

也就是说,A 与 B 的内积值等于 A 向 B 所在直线投影的标量大小。
在我们常说的坐标系种,向量 (3,2) 其实隐式引入了一个定义:以 x 轴和 y 轴上正方向长度为 1 的向量为标准。向量 (3,2) 实际是说在 x 轴投影为 3 而 y 轴的投影为 2。注意投影是一个标量,所以可以为负。所以,对于向量 (3, 2) 来说,如果我们想求它在 ( 1 , 0 ) , ( 0 , 1 ) (1, 0),(0,1) (1,0),(0,1)这组基下的坐标的话,分别内积即可。当然,内积完了还是 (3, 2)。
所以,我们大致可以得到一个结论,我们要准确描述向量,首先要确定一组基,然后给出在基所在的各个直线上的投影值,就可以了。为了方便求坐标,我们希望这组基向量模长为 1。因为向量的内积运算,当模长为 1 时,内积可以直接表示投影。然后还需要这组基是线性无关的,我们一般用正交基,非正交的基也是可以的,不过正交基有较好的性质。
对于向量 (3,2) 这个点来说,在
(
1
2
,
1
2
)
,
(
−
1
2
,
1
2
)
(\frac{1}{\sqrt{2}}, \frac{1}{\sqrt{2}}),(-\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}})
(21,21),(−21,21)这组基下的坐标是多少?
我们拿 (3,2) 分别与之内积,用矩阵相乘的形式简洁的表示这个变换:

左边矩阵的两行分别为两个基,乘以原向量,其结果刚好为新基的坐标。推广一下,如果我们有 m 个二维向量,只要将二维向量按列排成一个两行 m 列矩阵,然后用“基矩阵”乘以这个矩阵就可以得到了所有这些向量在新基下的值。例如对于数据点
(
1
,
1
)
,
(
2
,
2
)
,
(
3
,
3
)
(1,1),(2,2),(3,3)
(1,1),(2,2),(3,3)来说,想变换到刚才那组基上,则可以这样表示:
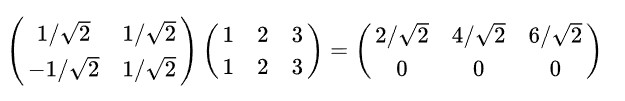
我们可以把它写成通用的表示形式:
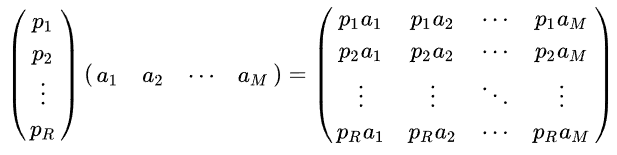
其中
p
i
p_i
pi是一个行向量,表示第 i 个基,
a
j
a_j
aj是一个列向量,表示第 j 个原始数据记录。实际上也就是做了一个向量矩阵化的操作。
上述分析给矩阵相乘找到了一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列向量
a
j
a_j
aj变换到左边矩阵中以每一行行向量为基所表示的空间中去。也就是说一个矩阵可以表示一种线性变换。如果基的数量少于向量本身的维数,则可以达到降维的效果。
降维问题的优化目标
对于高维数据,我们用协方差进行约束,协方差可以表示两个变量的相关性。为了让两个变量尽可能表示更多的原始信息,我们希望它们之间不存在线性相关性,因为相关性意味着两个变量不是完全独立,必然存在重复表示的信息。
- 将一组 N 维向量降为 K 维,其目标是选择 K 个单位正交基,使得原始数据变换到这组基上后,各变量两两间协方差为 0 (不存在线性相关性),而变量方差则尽可能大**(数据的分散程度好)**(在正交的约束下,取最大的 K 个方差)。
原矩阵与基变换后矩阵协方差矩阵的关系
- 设原始数据矩阵 X 对应的协方差矩阵为 C,而 P 是一组基按行组成的矩阵,设 Y=PX,则 Y 为 X 对 P 做基变换后的数据。设 Y 的协方差矩阵为 D,我们推导一下 D 与 C 的关系, 也就是变换后矩阵的协方差和原协方差的关系:

这样我们就看清楚了,我们要找的 P 是能让原始协方差矩阵对角化的 P。因为此时的D符合我们的要求: 除对角线外协方差为0 (不存在线性相关性), 对角线方差最大 (数据的分散程度好)
换句话说,优化目标变成了寻找一个矩阵 P,满足
∣
P
C
P
T
∣
|PCP^T|
∣PCPT∣ 是一个对角矩阵,并且对角元素按从大到小依次排列,那么 P 的前 K 行就是要寻找的基 (因为我们的P是行向量的基),用 P 的前 K 行组成的矩阵乘以 X 就使得 X 从 N 维降到了 K 维并满足上述优化条件.
对角化
一个 n 行 n 列的实对称矩阵一定可以找到 n 个单位正交特征向量,设这 n 个特征向量为 e 1 , e 2 . . . . . e n e_1,e_2.....e_n e1,e2.....en, 我们将其按列组成矩阵: E = ( e 1 , e 2 , . . . . . . e n ) E=(e_1, e_2, ......e_n) E=(e1,e2,......en), 则对协方差矩阵 C 有如下结论:

对角元素为各特征向量对应的特征值, 我们已经找到了需要的矩阵 P:
P
=
E
T
P=E^T
P=ET
P 是协方差矩阵的特征向量单位化后按行排列出的矩阵,其中每一行都是 C 的一个特征向量。如果设 P 按照对角矩阵中特征值的从大到小,将特征向量从上到下排列,则用 P 的前 K 行组成的矩阵乘以原始数据矩阵 X,就得到了我们需要的降维后的数据矩阵 Y
方差
我们知道数值的分散程度,可以用数学上的方差来表述。一个变量的方差可以看做是每个元素与变量均值的差的平方和的均值,即:

为了方便处理,我们将每个变量的均值都化为 0 ,因此方差可以直接用每个元素的平方和除以元素个数表示:

协方差
- 协方差(Covariance)是度量两个变量的变动的同步程度,也就是度量两个变量线性相关性程度。如果两个变量的协方差为0,则统计学上认为二者线性无关。注意两个无关的变量并非完全独立,只是没有线性相关性而已。计算公式如下:

当样本数较大时,不必在意其是 m 还是 m-1,为了方便计算,我们分母取 m。
假设我们只有 a 和 b 两个变量,那么我们将它们按行组成矩阵 X:

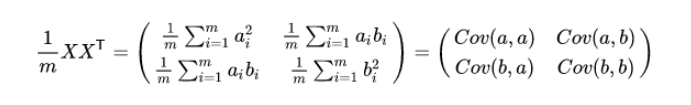
我们可以看到这个矩阵对角线上的分别是两个变量的方差,而其它元素是 a 和 b 的协方差。两者被统一到了一个矩阵里.
设我们有 n 个 m 维数据记录,将其排列成矩阵
X
n
,
m
X_{n,m}
Xn,m,设
C
=
1
m
X
X
T
C=\frac{1}{m}XX^T
C=m1XXT,则 C 是一个对称矩阵,其对角线分别对应各个变量的方差,而第 i 行 j 列和 j 行 i 列元素相同,表示 i 和 j 两个变量的协方差。
计算方法: 让样本矩阵中心化,即每一维度减去该维度的均值,使每一维度上的均值为0,然后直接用新得到的样本矩阵乘上它的转置,然后除以(N-1)即可。
协方差矩阵是一个对称的矩阵,而且对角线是各个维度上的方差。协方差矩阵是计算不同维度间的协方差,要时刻牢记这一点。样本矩阵的每行是一个样本,每列为一个维度,所以我们要按列计算均值。
















 7615
7615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











