







3DMM是什么?
3DMM是一种人脸形状和外观的统计模型, 全称是3D Morphable Face Model, 即可变性人脸模型. 首先利用高精度一起扫描多组人脸3D数据, 并进行对齐. 之后利用PCA从这些三维形状和颜色数据中得到更低维的子空间.可变性体现在可以在这些PCA子空间进行组合变形, 将一个人脸的特性转移到另外一个人脸, 或者生成新的人脸.
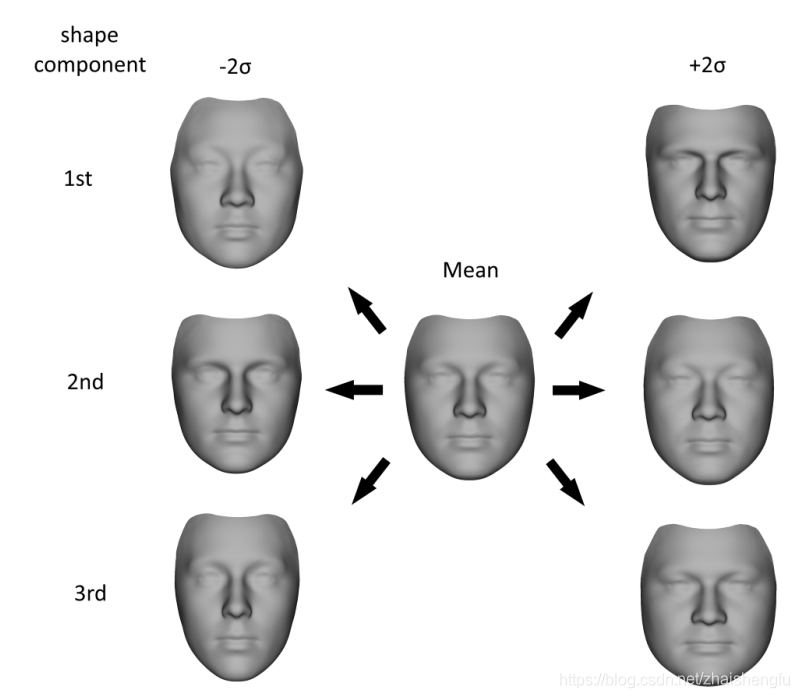
脸部PCA模型
2DMM本质是对对齐之后的人脸进行PCA. 人脸模型可以表示成一个向量 S ∈ R 3 N \bold{S} \in \mathbb{R}^{3N} S∈R3N, , 其中N代表顶点数量.同理颜色信息 T ∈ R 3 N \bold{T} \in \mathbb{R}^{3N} T∈R3N. 将所有的训练网格组成一个数据矩阵, 然后对这个数据矩阵运用PCA分解.注意形状和颜色是区分开的.最终3DMM会包含两个PCA模型, 分别对应形状和颜色. 对于每一个PCA模型, 都有
M = ( v ⃗ , σ , V ) (1.1) M = ({\bold{\vec{v}}} , \sigma, \bold{V} ) \tag{1.1} M=(v,σ,V)(1.1)
其中 v ⃗ {\bold{\vec{v}}} v是均值, V \bold{V} V是PCA得到的主成分, V = [ v 1 , v 2 , . . . v m ] ∈ R 3 N × m \bold{V} = [\bold{v_1}, \bold{v_2}, ...\bold{v_m}] \in \mathbb{R}^{3N \times m} V=[v1,v2,...vm]∈R3N×m , σ ∈ R m \sigma \in \mathbb{R}^{m} σ∈Rm代表标准差. m个主成分最好能够原始数据99%的变化.n代表扫描数据, 例如Basel Face Model中是200.
基于上面的模型, 脸部模型可以表达成:
S = v ⃗ + ∑ i = 1 m α i σ i v i \bold{S} = {\bold{\vec{v}}} + \sum_{i=1}^{m} \alpha_i\sigma_i{\bold{v}_i} S=v+i=1∑mαiσivi
上式中的
α
就
是
形
状
参
数
\alpha就是形状参数
α就是形状参数
表情建模
上面的是3DMM的形状建模. 除此之外人脸还有表情. 对于表情有两种方法:一种是类似形状一样, 扫描多种表情然后进行PCA, 得到表情基.但是这样的一种缺点就是得到的表情基没有实际语义, 很难拓展使用 ,但是这种方法可以使得不同人物的相同表情具有不同的自适应性;另外一种就是使用blendshape,这种在建模等领域广泛使用. 无论哪种方法, 加入表情的3DMM呈现下面形式:
S = v ⃗ + ∑ i = 1 m α i σ i v i + ∑ j = 1 k ψ j B j \bold{S} = {\bold{\vec{v}}} + \sum_{i=1}^{m} \alpha_i\sigma_i{\bold{v}_i} + \sum_{j=1}^{k}\psi_j\bold{B}_j S=v+i=1∑mαiσivi+j=1∑kψjBj
其中k代表表情基或者blendshape的数量.
人脸模型拟合
接下来讲述的方法是eos中的方法, 而非深度学习方法[在我看来, 深度学习相当于将许多之前需要人为努力设计的方法交给了神经网络自己学习, 并非不好, 只是不太喜欢这种托付. 对应的, 非深度学习方法需要自己设计很多框架, 但是过程更清晰].想看深度学习的请绕道.eos中的人脸重建包括四个步骤:姿态估计, 形状拟合, 表情拟合, 轮廓拟合.
正交相机模型
为了拟合3DMM和二维图像, 必须需要一个显式的相机模型,这个相机模型将三维模型从3D空间映射到图像空间.这个过程可以表示为:
P ( S , ρ ) : R 3 N → R 2 N P(\bold{S}, \rho): \mathbb{R}^{3N} \rightarrow \mathbb{R}^{2N} P(S,ρ):R3N→R2N
其中 S \bold{S} S代表人脸形状, ρ \rho ρ代表相机参数.
原则上, 这里可以选择很多类型相机模型:例如透视相机模型, 政教相机模型或者仿射投影模型. 具体的, 从三维点到二维点的过程可以分解为两步:
-
模型坐标系统到三维相机坐标系统
v c = [ x c , y c , z c ] T = R v + t \bold{v}_c = [x_c, y_c, z_c]^T = \bold{R}\bold{v} + \bold{t} vc=[xc,yc,zc]T=Rv+t
R \bold{R} R代表3 *3的旋转矩阵, t \bold{t} t代表三维平移向量 -
应用相机投影到二维空间
v ′ = π ( ρ i n t r , v c ) \bold{v}' = \pi(\rho_{intr}, \bold{v}_c) v′=π(ρintr,vc)
其中 ρ i n t r \rho_{intr} ρintr代表相机的内参.例如对于可缩放的正交投影, 内参只有一个缩放因子 s s s, 这样相机的所有参数就是
ρ = [ s , R , t x , t y ] \rho = [s,\bold{R}, t_x, t_y] ρ=[s,R,tx,ty]
我们在姿态估计的时候, 需要恢复这些参数.
相机的选择
相机有很多种, 那么到底应该选择哪种类型呢?首先, 仿射相机模型貌似是诱人的选择. 经典算法Gold Standard Algorithm(以下简称GSA)提供了求解仿射相机矩阵的方法. 给定一系列2D和3D点的对应, GSA方法找到这些对应点的最小平方估计从而来估计仿射矩阵.之所以说诱人, 是因为这个算法有闭合解.然后这种方法有一个争议点:它不包含相机变换的约束, 这会导致生成的人脸呈现倾斜特性., 以及x轴和y轴的不均匀缩放,这些都会导致不自然的人脸变形. 或者换句话说, 有一些原本应该由shape参数导致的人脸变形会被这里的仿射矩阵参数影响, 从而导致不正确的拟合结果, 如下图左边.

另外一个相机选择就是可缩放的正交投影相机模型.可能你会想, 正交投影并不真实, 怎么能用来进行拟合过程的相机建模呢?确实不真实, 这里我个人考虑是, 人脸的纵深关系不是特别大, 透视效应没有特别明显, 所以正交投影可以近似认为是正确的. 另外一个重要的原因是, 它保留了欧拉空间的刚性运动以及缩放.上图右边是用可缩放正交投影的拟合结果.这个时候相机参数没有扰乱shape参数.
最终选择可缩放的正交投影模型
可缩放正交投影相机模型
这种模型需要加入旋转矩阵 R \bold{R} R的正交限制, 也就是列之间彼此垂直. 决定了采用这个模型之后如何求解呢?历史上有过Levenberg-Marquardt等方法求解, 但是容易陷入局部最优, 从而导致最终效果不太好.eos采用一种迭代的方法求解相机参数.这个问题可以规范描述为:
将二维坐标点和三维对应坐标点用其次坐标表达, 分别为 x i ∈ R 3 {x_i \in \mathbb{R}^3} xi∈R3以及 X i ∈ R 4 {X_i \in \mathbb{R}^4} Xi∈R4. 给定超过四组对应点, 希望找到相机矩阵 A ∈ R 3 × 4 \bold{A} \in \mathbb{R}^{3 \times 4} A∈R3×4, 使得 ∑ i ∣ ∣ x i − A X i ∣ ∣ \sum_{i}||\bold{x}_i - \bold{A}\bold{X}_i|| ∑i∣∣xi−AXi∣∣最小.这里先采用仿射相机的假设, 即 A 3 = [ 0 , 0 , 0 , 1 ] \bold{A}_3 = [0, 0, 0, 1] A3=[0,0,0,1]
[这里其实有我不能理解的点, 就是已经假定是可缩放正交投影了, 为什么这里还能采用仿射相机的假设?仅仅是为了可以求解的妥协吗?如果是这样的话就没有任何道理了, 仅仅为了求解就随便做假设? 或者是基于一定误差范围内的合理假设, 但是我自己不太明白这种合理性, 读者有理解的欢迎交流]
这个迭代过程包括两步:
-
将数据进行归一化处理. 通过相似变换, 将2D图像点的中心和3D模型的中心移动到各自坐标系的原点, 并缩放模型使得到原点的均方差距离分别是 2 \sqrt{2} 2以及 3 \sqrt{3} 3. 这个过程本质上平移和缩放, 所以可以用矩阵表示为:
x ~ i = T x i , T ∈ R 3 × 3 X ~ i = U X i , U ∈ R 4 × 4 \tilde{\bold{x}}_i= \bold{T}\bold{x}_i, \bold{T} \in \mathbb{R}^{3 \times 3} \\ \tilde{\bold{X}}_i= \bold{U}\bold{X}_i, \bold{U} \in \mathbb{R}^{4 \times 4} x~i=Txi,T∈R3×3X~i=UXi,U∈R4×4
之后估计归一化的相机矩阵 A ~ ∈ R 3 × 4 \tilde{\bold{A}} \in \mathbb{R}^{3 \times 4} A~∈R3×4. 每组都会贡献两个等式:
[ X ~ i 0 T 0 T X ~ i ] [ A 1 ~ T A 2 ~ T ] = [ x ~ i y ~ i ] \begin{gathered} \begin{bmatrix} \tilde{\bold{X}}_i & \bold{0}^T \\ \bold{0}^T & \tilde{\bold{X}}_i \end{bmatrix} \quad \begin{bmatrix} \tilde{\bold{A_1}}^T \\ \tilde{\bold{A_2}}^T \end{bmatrix} \quad = \begin{bmatrix} \tilde{x}_i \\ \tilde{y}_i \end{bmatrix} \quad \end{gathered} [X~i0T0TX~i][A1~TA2~T]=[x~iy~i]
这个方程可以求解得到 A ~ \tilde{\bold{A}} A~, 最后得到仿射矩阵 A = T − 1 A ~ U {\bold{A}} = \bold{T}^{-1}\tilde{\bold{A}}\bold{U} A=T−1A~U. 这个仿射矩阵很好求解, 但是如前面所说, 他的缺点说没办法保证欧拉空间的刚性运动特性.
-
约束姿态估计是刚性运动, 具体来说是可缩放正交投影. 从上面的仿射相机矩阵 A \bold{A} A中, 根据相应算法, 运用SVD分解得到与原始仿射矩阵最接近的单位正交旋转矩阵
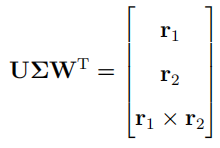
最终的旋转矩阵 R = U W T \bold{R} = \bold{U}\bold{W}^T R=UWT. 上面的 r 1 \bold{r}_1 r1等如何获取? 根据上面估计得到的仿射矩阵 A \bold{A} A获取.缩放因子 s = ( ∣ ∣ r 1 ∣ ∣ + ∣ ∣ ∣ r 2 ∣ ∣ ) / 2 s = (||\bold{r}_1|| + |||\bold{r}_2||) / 2 s=(∣∣r1∣∣+∣∣∣r2∣∣)/2, 平移因子 t = [ A 1 , 4 , A 2 , 4 ] \bold{t} = [\bold{A}_{1,4}, \bold{A}_{2,4}] t=[A1,4,A2,4]
最终得到的旋转矩阵是单位正交列的. 这样最终得到的可缩放正交投影参数 ρ \bold{\rho} ρ 包含缩放因子 s s s, 旋转矩阵 R \bold{R} R, 以及平移矩阵 t \bold{t} t
我们总结一下, 这个方法不同于以往直接用线性或者分线性优化策略求解约束问题来计算相机参数, 它分为两个步骤: 第一个步骤, 假定仿射投影并利用GSA来求解仿射相机参数; 第二步,利用上面的仿射相机参数, 通过SVD分解得到一个最接近他的正交投影矩阵. 之后二哥步骤不断迭代并最终求到收敛解.
个人的疑问有以下几点:首先就是仿射矩阵的假设, 利用GSA来求解的合理性; 其次, 通过用正交投影来即使仿射投影的合理性是什么?仅仅是因为有这样的两个算法可以使用吗?其次, 这种迭代的好处是什么?最后, eos也说了, 这种求解方法必须假设脸部模型没有受到严重的透视效果影响.如果基于这种假设, 那么仿射投影或者正交投影应该都算作真实成像的一种为了计算方便的假设. 这里其实就是很多传统方法的弊端了, 为了过程可以求解以及清晰, 就会做很多妥协, 然后用人类可想到的方法进行求解. 深度学习就不这样, 他不会做妥协, 对应的, 内部的一些细节也只能丢失.
PCA形状拟合
上面说了那么多, 实际仅仅解决了第一个姿态拟合的问题(不过这个也是非常重要和基础的, 后面很多步骤都基于此).接下来就是第二步, 形状拟合.
这个步骤给定第一步得到的相机姿态参数, 进行2D点和3D模型点的拟合.这一步的作用是估计形状参数
α
\bold{\alpha}
α, 采用的方法是最小化2D图像点和3D模型的投影点的距离,损失函数如下:
E = ∑ i = 1 3 L ( y p , i − y i ) 2 2 σ 2 D , i 2 + λ ∣ ∣ α ∣ ∣ 2 (1.2) \mathbb{E} = \sum_{i=1}^{3L} \frac{(y_{p,i} - y_i)^2}{2\sigma_{2D, i}^2} + \lambda||\bold{\alpha}||^2 \tag{1.2} E=i=1∑3L2σ2D,i2(yp,i−yi)2+λ∣∣α∣∣2(1.2)
其中后面部分是对于形状参数的先验知识. L L L是关键点的个数, σ 2 D 2 \sigma_{2D}^2 σ2D2表示关键点的方差(从关键点检测器的训练中得到). y = [ y 1 , y 2 , . . . , y 3 L ] \bold{y} = [y_1, y_2, ...,y_{3L}] y=[y1,y2,...,y3L]表示2D图像点的齐次坐标形成的向量, 而 y p = [ y p , 1 , y p , 2 , . . . , y p , 3 L ] \bold{y_p} = [y_{p,1}, y_{p,2},...,y_{p,3L}] yp=[yp,1,yp,2,...,yp,3L]表示对应于2D点的3DMM模型中的点经过投影形成的2D点的齐次坐标. 这种从3D到2D的对应关系通过相机矩阵 C ∈ R 3 × 4 C \in \mathbb{R}^{3 \times 4} C∈R3×4完成
C = s [ R ~ 1 t x R 2 t y [ 0 , 0 , 0 ] 1 ] \begin{gathered} C= s \begin{bmatrix} \tilde{\bold{R}}_1 & t_x \\ \bold{R}_2 & t_y \\ [0 , 0 , 0]& 1 \end{bmatrix} \quad \end{gathered} C=s⎣⎡R~1R2[0,0,0]txty1⎦⎤
然后我们将 C C C的复制放到块对角矩阵 P ∈ R 3 N × 4 N P \in \mathbb{R}^{3N \times 4N} P∈R3N×4N. 理论上来说, 如果很精确的话, 那么 C C C应该是唯一的吧? 因为是经过同一个摄像机视角拍下的照片.最终的投影之后的2D坐标为:
y p = P ⋅ ( V h ^ α + v ˉ ) \bold{y_p} = P \cdot(\hat{\bold{V_h}}\alpha + \bar{\bold{v}}) yp=P⋅(Vh^α+vˉ), 其中 V h ^ 代 表 对 应 于 关 键 点 的 P C A 形 状 基 矩 阵 . \hat{\bold{V_h}}代表对应于关键点的PCA形状基矩阵. Vh^代表对应于关键点的PCA形状基矩阵..这些基向量会乘以各自的特征值的平方根,并且由于是齐次坐标, 会在每三行之后添加一个全为0的行.
这样1.2中的方程可以表达为标准的正则二次项等式, 并最终可以求解 α \alpha α的闭合解
线性表情拟合
形状拟合完毕之后需要进行表情拟合.最终求解目标是表情参数 ψ \psi ψ… 采用的方法类似形状拟合.这里的表情拟合采用和形状拟合交替求解的方法, 即固定 α \alpha α求解 ψ \psi ψ, 然后固定 ψ \psi ψ求解 α \alpha α, 并且求解过程中不适用平均脸, 而是不断更新脸部基准模型:
S α = v ˉ + ∑ i = 1 m α i σ i v i \bold{S}^\alpha = \bar{\bold{v}} + \sum_{i=1}^{m}\alpha_i\sigma_i \bold{v}_i Sα=vˉ+i=1∑mαiσivi
最终采用和形状拟合类似的方法求解. 注意这里采用的是非负最小平方算法.因为表情基一般都是0~1之间, 负数会造成不可靠的拟合结果
在表情参数
ψ
\psi
ψ求到之后,利用这个参数形成身份中立的形状
S
ψ
\bold{S}^\psi
Sψ:
S ψ = v ˉ + ∑ j = 1 k ψ j B j \bold{S}^\psi = \bar{\bold{v}} + \sum_{j=1}^{k}\psi_j \bold{B}_j Sψ=vˉ+j=1∑kψjBj
轮廓拟合
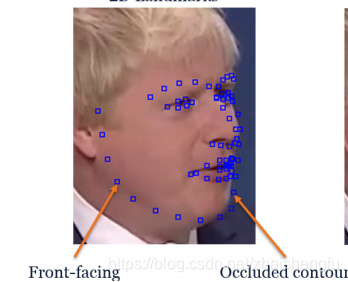
通常来说2D图像的人脸外部轮廓不会唯一对应于3D模型中的轮廓, 但是其对于人脸模型匹配很重要

为了解决人脸轮廓匹配, eos提出了包含两个独立部分的拟合方法(eos给我最大的启发就是, 多过程多步骤, 你干完我再干的迭代). 那么这里有事怎么样用多个步骤的呢?首先, 给定当前的姿态估计(从所有非轮廓点中获取), 当前人脸模型会有正面轮廓和背面轮廓, 如下图. 二者会分开进行拟合.














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









