






机器学习 | 稳定学习 | DGBR
深度学习 | 迁移学习 | 因果学习
众所周知,深度学习研究是机器学习领域中一个重要研究方向,主要采用数据分析、数据挖掘、高性能计算等技术,其对服务器的要求极其严格,传统的风冷散热方式已经不足以满足散热需要,这就需要新兴的液冷散热技术以此满足节能减排、静音高效的需求。机器学习除了在深度学习研究领域有其很大的发展,在因果学习、虚拟仿真、医药研发等领域也有很大的提高。尽管机器学习在很多领域都取得了成功,但是虚假相关带来的潜在风险还是限制了这些模型在不少风险敏感领域的应用。这时稳定学习被提出来应对这个挑战,它试图在不影响模型性能的情况下构建更加可信的机器学习模型。
今年2月23日,清华大学计算机系崔鹏副教授与斯坦福大学Susan Athey(美国科学院院士,因果领域国际权威)合作,在世界顶级期刊Nature Machine Intelligence(影响因子IF=15.51,2020)上发表了一篇题为“Stable Learning Establishes Some Common Ground Between Causal Inference and Machine Learning”(稳定学习:建立因果推理和机器学习的共识)的观点论文,深入探讨和总结了因果推理在机器学习和人工智能领域的关注,提出机器学习和因果推理之间应该形成共识,稳定学习正在向这个目标迈进。基于上述学术观点,本文总结了稳定学习的一系列进展。
人工智能当前面临的挑战
纵观人工智能(AI)技术的发展史,在过去的20年中,人工智能的进步紧密伴随着互联网经济的发展,在诸如网上搜索、推荐商品等众多场景中都有人工智能技术的运用。在这些场景中,AI做出错误决策的危害较小(比如推荐了用户不感兴趣的商品),使用者对AI模型算法的稳定性和可靠性要求相对较低。如今,AI技术逐渐渗透进了包括医疗、司法、运输等与民众生活紧密相关,对人类的生存和发展有重大影响的领域中。在这样的背景下,AI模型的可靠性和稳定性问题变得日益重要,也很大程度上决定了我们能在多大程度上利用和依赖人工智能技术帮助决策。
我们认为,当前人工智能模型在实践利用中存在两个重要问题。一是模型缺乏可解释性;也即人们无法理解模型做出判断的逻辑和原因。这就导致人们面对模型的决策时,只能无条件地完全肯定或否定其提供的答案,我们认为可以通过建立人机协作(human in the loop)的机制合作决策解决这个问题。第二个问题则是模型缺乏在位置环境下性能的稳定性;目前大多数人工智能模型依赖于iid假设(Independent and identically distributed), 即训练数据集和测试数据集的数据分布是相似的;而在实际运用中,无法完全预见可能出现的数据分布(无法了解测试数据集的分布),此时模型的性能无法保证。本文将重点解决模型在未知环境下的性能稳定性问题。
以识别图片中是否存在狗的人工智能应用为例。图中的左图是训练集中包含狗的图片集,其中大多数图片的背景是草地。而在测试集中,模型对同样为草地背景的图片有良好的判断力(右图上);对非草地背景的图片判断准确度下降(右图中、下)。
因果学习新进展深度稳定学习
目前深度学习在很多研究领域特别是计算机视觉领域(如图像识别、物体检测等技术领域)取得了前所未有的进展,而深度模型性能依赖于模型对训练数据的拟合。当训练数据(应用前可获取的数据)与测试数据(实际应用中遇到的实例)分布不同时,传统深度模型对训练数据的充分拟合会造成其在测试数据上的预测失败,进而导致模型应用于不同环境时的可信度降低。为了解决模型在分布迁移下的泛化问题,崔鹏老师团队提出深度稳定学习,提高模型在任意未知应用环境中的准确率和稳定性。
上图给出了常见的独立同分布模型、迁移学习模型和稳定学习模型的异同。独立同分布模型的训练和测试都在相同分布的数据下完成,测试目标是提升模型在测试集上的准确度,对测试集环境有较高的要求;迁移学习同样期望提升模型在测试集上的准确度,但是允许测试集的样本分布与训练集不同。独立同分布学习和迁移学习都要求测试集样本分布已知。而稳定学习则希望在保证模型平均准确度的前提下,降低模型性能在各种不同样本分布下的准确率方差。理论上稳定学习可以在不同分布的测试集下都有较好的性能表现。
一、基于本质特征的稳定学习
现有深度学习模型试图利用所有可观测到的特征与数据标签的相关性进行学习和预测,而在训练数据中与标签相关的特征并不一定是其对应类别的本质特征。深度稳定学习的基本思路是提取不同类别的本质特征,去除无关特征与虚假关联,并仅基于本质特征(与标签存在因果关联的特征)作出预测。如下图所示,当训练数据的环境较为复杂且与样本标签存在强关联时,ResNet等传统卷积网络无法将本质特征与环境特征区分开来,所以同时利用所有特征进行预测,而StbleNet则可将本质特征与环境特征区分开来,并仅关注本质特征而忽略环境特征,从而无论环境(域)如何变化,StableNet均能做出稳定的预测。
传统深度模型与深度稳定学习模型的saliency map,其中亮度越高的点对预测结果的贡献越大,可以看到两者特征的显著不同,StableNet更关注与物体本身而传统深度模型也会关注环境特征
目前已有的稳定学习方法多针对线性模型,通过干扰变量平衡(Confounder Balancing)的方法来使得神经网络模型能够推测因果关系。具体而言,如果要推断变量A对变量B的因果关系(存在干扰变量C),以变量A是离散的二元变量(取值为0或1)为例,根据A的值将总体样本分为两组(A=0或A=1),并给每个样本赋予不同的权重,使得在A=0和A=1时干扰变量C的分布相同(即D(C|A=0) = D(C|A=1),其中D代表变量分布),此时判断D(B|A=0) 和D(B|A=1)是否相同可以得出A是否与B有因果关系。
而在计算机视觉相关的场景中,由于经卷积网络后的各维特征为连续值且存在复杂的非线性依赖关系,无法通过直接应用上述干扰变量平衡方法来消除特征间的相关性;另外由于用于深度学习的训练数据集通常尺寸较大,深度特征的维度也较大,所以无法直接计算出全局的样本权重。本文要解决的问题,就是如何在深度学习网络中找到一组样本权重,使得所有变量之间都可以做到互相独立,即任意选取一个变量为目标变量,目标变量的分布不随其它变量的值的改变而改变。
二、基于随机傅立叶特征的深度特征去相关
而深度网络的各维特征间存在复杂的依赖关系,仅去除变量间的线形相关性并不足以完全消除无关特征与标签之间的虚假关联,所以一个直接的想法就是通过kernel(核方法)将映射到高维空间,但是经过kernel映射后原始特征的特征图维度被扩大到无穷维,使得各维变量间的相关性无法计算。鉴于随机傅立叶特征(Random Fourier Feature, RFF)在近似核函数以及衡量特征独立性方面的优良性质,本文采用RFF将原始特征映射到高维空间中(可以理解为在样本维度进行扩充),消除新特征间的线形相关性即可保证原始特征严格独立,如下图所示。
三、全局优化样本权重
上述公式要求在训练过程中为每个训练样本都学习一个特定的权重,但在实践中,尤其对于深度学习任务,要想利用全部样本全局地学习样本权重需要巨大的计算和存储开销。此外,使用SGD对网络进行优化时,每轮迭代中仅有部分样本对模型可见,因此无法获取全部样本的特征向量。本文提出了一种存储、重加载样本特征与样本权重的方法,在每个训练迭代的结束融合并保存当前的样本特征与权重,在下一个训练迭代开始时重加载,作为训练数据的全局先验知识优化新一轮的样本权重,如下图所示。
StableNet的结构图如下图所示,输入图片经过卷积网络后提取得视觉特征,后经过两个分支。其中上方分支为样本权重学习子网络,下方分支为常规分类网络。最终训练损失为分类网络预测损失与样本权重的加权求和。其中LSWD为去相关样本权重学习模块(Learning Sample Weights for Decorrelation),利用RFF学习使特征各维独立的样本权重。
以识别狗的应用为例,如果训练样本中大部分的狗在草地上,少部分的狗在沙滩上,图片相应的视觉特征经样本重加权后各维独立,即狗对应的特征与草地、沙滩对应的特征在统计上不相关,所以分类器在预测狗是否存在时更容易关注与狗相关的特征(若关注草地、沙滩等特征会造成预测损失激增),所以测试时无论狗在草地上或沙滩上与否,StableNet均能依据本质特征给出较准确的预测,实现模型在OOD数据上的泛化。
四、含义更广泛的域泛化任务
在常规的域泛化(DG)任务中,训练集的不同源域容量相近且异质性清晰,然而在实际应用中,绝大部分数据集都是若干潜在源域的组合,当源域异质性不清晰或未被显式标注时,我们很难假定来自于各源域的数据数量大致相同。为了更加全面地验证StableNet的泛化性能,本文提出三种新的域泛化任务来仿真更加普适且挑战性更强的分布迁移泛化场景。
1、不均衡的域泛化
对于源域不明确的域泛化问题,假定源域容量相近过于理想化,一个更普适的假设为来自不同源域的数据量可能不同且可能差异巨大。在这种情况下,模型对于未知目标域的泛化能力更满足实际应用的需求。例如在识别狗的例子中,我们很难假定背景为草地、沙滩或水里的图片数量相同,实际情况下狗较多地出现在草地上而较少出现在水里。这就要求模型的预测不能被经常与狗一起出现的背景草地误导,所以本任务的普适性和难度显著高于均衡的域泛化。
使用ResNet18作为特征提取网络的实验结果如下表,在PACS和VLCS数据集上StableNet取得了最优性能。
2、部分类别缺失的域泛化
我们考虑一种挑战性更大且在现实场景中经常存在的情况,某些源域中有部分类别的数据缺失,而在测试集中模型需要识别所有类别。例如,鸟经常出现在树上而几乎不会出现在水里,鱼经常出现鱼缸里而几乎不会出现在树上,所以并不是所有源域都一定包含全部类别。这种场景要求更高的模型泛化能力,由于每个源域中仅有部分类别,所以域相关的特征与标签间的虚假关联更强且更易误导分类器。
下表为实验结果,由于对域异质性及类别完整性的要求,很多现有域泛化方法无法显著优于ResNet,而StableNet在PCAS,VLCS及NICO上均取得了最优结果。
3、存在对抗的域泛化
一种难度更大的场景是任一给定类别的主导源域与主导目标域不同。例如,训练数据中的狗大多在草地上而猫大多在室内,而测试数据中的狗大多在室内而猫大多在草地上,这就导致如果模型不能区分本质特征与域相关特征,就会被域信息所误导而做出错误预测。下表为在MNIST-M数据集上的实验结果,StableNet仍显著优于其他方法,且可见随主导域比例升高,ResNet的表现显著下降,StableNet的优势也越发明显。
稳定学习的主要方法
DGBR算法首次解决了二元预测变量(特征)和二元离散响应变量设定下的稳定预测问题。此后,人们提出一系列稳定学习方法以解决不同设置下更稳定的预测问题。但后续设计的稳定学习方法不仅仅局限于因果推理的角度,包括统计学习、优化过程等不同视角,本部分将一一介绍。
一、基于样本加权的变量去相关
崔鹏团队进一步探讨了模型错估(即模型与数据生成机制不一致)的稳定预测问题。Zheyan Shen等人研究了线性模型中变量间的共线性如何影响预测稳定性,提出了一种通用的数据预处理方法,通过对训练集样本重新加权来去除预测变量(特征)间的相关性,以减少共线性影响。况琨等人的工作进一步改进了DGBR算法,提出了去相关加权回归(DWR),将变量去相关正则化与加权回归模型相结合,解决了连续预测变量(特征)设置下模型的稳定预测问题。
去除所有变量之间的相关性固然是找到因果相关,平衡协变量并实现稳定预测的好主意,它的代价是大大降低了有效样本量,而这在机器学习训练中是灾难性的。Zheyan Shen等人通过使用来自不同环境的未标注数据,提出了一种基于变量聚类的变量分解的算法,称为区分性变量去相关(Differentiated Variable Decorrelation, DVD)。这个方法是注意到保留因果性变量之间的相关性未必会导致模型在未知环境中的性能不稳定。以特征间相关性的在训练集数据和未标注之间的数据稳定性作为聚类的指标,可以将预测变量(特征)进行聚类并为不同的聚类簇,其中一些聚类簇代表了对相应变量具有因果效应的特征集合。在平衡混淆变量时只需要隔离这些聚类簇即可。由于聚类簇的数量远低于特征的维度,因此DVD与样本加权方法DWR相比,保持了更高的有效样本量。
与不加区分地去除所有变量的相关性的方法(DWR)相比,区分性变量去相关方法(DVD)在相同设定下具有更大的有效样本量
二、对抗稳定学习
由于人们总是想最大化地利用训练数据中发现的所有相关性,具有经验风险最小化的机器学习算法在分布变化下很容易受到攻击。崔鹏老师团队提出了稳定对抗学习 (Stable Adversarial Learning, SAL) 算法,以一种更有原则和统一的方式来解决这个问题,该算法利用异构数据源构建更实用的不确定性集并进行差异化鲁棒性优化,其中协变量根据其与目标相关性的稳定性进行区分。
具体来说,该方法就是采用了Wasserstein分布式鲁棒学习(Wasserstein distributionally robust learning, WDRL)的框架。根据协变量在多个环境中的稳定性,进一步将不确定性集表征为各向异性,这会给不稳定协变量带来比稳定协变量更强的对抗性扰动。并且设计了一种协同算法来联合优化协变量的微分过程以及模型参数的对抗训练过程。
在实验中,将SAL算法与经验风险最小化 (Empirical Risk Minimization, ERM) 框架、Wasserstein分布式鲁棒学习 (Wasserstein distributionally robust learning, WDRL) 框架、不变风险最小化 (Invariant Risk Minimization, IRM) 框架进行比较:
(a)各环境下的测试性能 (b) 关于半径的测试性能 (c) S和V相对于半径的学习系数值
实验结果表明,SAL算法各向异性地考虑每个协变量以获得更真实的鲁棒性。此外,构造了一个更好的不确定集,在不同的分布的数据上取得了一致更好的表现,验证了算法的有效性。
三、异质性风险最小化
同样,如果要充分利用训练数据中发现的所有相关性,经验风险最小化的机器学习算法通常泛化性能很差,而且这些相关性在分布的变化下是不稳定的。崔鹏老师的团队提出了异质性风险最小化(HRM)的框架,以实现对数据之间潜在的异质性和不变关系的联合学习,从而实现在分布变化的情况下的稳定预测。
HRM框架
整体框架如图所示。该框架包含两个模块,用于异质性识别的前端和用于不变预测的后端Mp。给定异质性数据,从异质性识别模块Mc出发,用学习变量ψ (x)表示异质性环境εlearn。然后,分布外一般化预测模块Mp使用所学习的环境来学习MIP φ (x)和不变预测模型F (φ (x))。之后,我们推导出变型ψ (x)来进一步增强模Mc。至于“转换”步骤,基于我们的设置,我们在这项工作中采用了特征选择,通过它可以在学习更多不变特征时获得更多的变异特征。
HRM是一种优化框架,可实现数据和不变预测器之间潜在异质性的联合学习。尽管分布发生变化,在该框架下仍具有更好的泛化能力。
为了验证该框架的有效性,崔鹏老师团队将HRM框架与经验风险最小化 (Empirical Risk Minimization, ERM) 框架、分布鲁棒优化 (Distributionally Robust Optimization, DRO) 框架、不变学习的环境推理 (Environment Inference for Invariant Learning, EIIL) 框架、具有环境εtr标签的不变风险最小化 (IRM) 框架进行比较。
实验表明,与基线方法相比,HRM在平均性能和稳定性方面取得了近乎完美的表现,尤其是跨环境损失的方差接近于0。此外,HRM不需要环境标签,这验证了我们的聚类算法可以挖掘数据内部潜在的异质性。
继续进行了三个真实场景的预测,包括汽车保险预测、人们收入预测和房价预测。
真实场景的预测结果(a) 汽车保险预测的训练和测试准确性。左子图显示了5种设置的训练结果,右子图显示了它们对应的测试结果。(b) 收入预测的误分类率。(c) 房价预测的预测误差。
从实验结果可以看出,在所有任务和几乎所有测试环境中,HRM始终保持最佳性能。HRM可以有效地揭示和充分利用训练数据的内在异质性进行不变学习。HRM放宽了对环境标签的要求,为不变学习开辟了新的方向。它能够涵盖广泛的应用,例如医疗保健、金融、营销等。
四、稳定学习的理论解释
协变量偏移泛化是分布外泛化 (OOD) 中的典型案例,它要求在未知测试分布上具有良好的性能,并且该测试分布与训练分布差距体现在协变量迁移上。在涉及回归算法和深度神经网络的几种学习模型上,稳定的学习算法在处理协变量移位泛化方面已经显示出一定的有效性。崔鹏老师团队通过将稳定学习算法解释为特征选择的过程,向理论分析迈进了一步。
具体是这样的,首先定义一组变量,称为最小稳定变量集(minimal stable variable set),它是处理常见损失函数(包括均方损失和二元交叉熵损失)下的协变量迁移泛化的最小且最优的变量集合。然后证明了在理想条件下,稳定的学习算法可以识别出这个集合中的变量。这些理论阐明了为什么稳定学习适用于协变量迁移泛化。
典型稳定学习算法的框架如图所示。该算法通常包括两个步骤,分别是重要性采样和加权最小二乘。在理想条件下,稳定学习算法可以识别最小稳定变量集,这是可以在协变量偏移下提供良好预测的最小变量集。
最小稳定变量集与马尔可夫边界密切相关,稳定学习在一定程度上有助于识别马尔可夫边界。此外,如果以协变量移位泛化为目标,马尔可夫边界不是必需的,而最小稳定变量集是充分且最优的。
与马尔可夫边界相比,最小稳定变量集可以带来两个优势:
① 条件独立性检验是精确发现马尔可夫边界的关键。
② 在几个常见的机器学习任务中,包括回归和二元分类,并不是所有的变量都在马尔可夫边界。最小稳定变量集被证明是马尔可夫边界的子集,它排除了马尔可夫边界中无用的变量,用于协变量移位泛化。
稳定学习的应用
一、图上的稳定学习
1、具有选择性偏差的多个环境中学习稳定图
如今,图已成为一种通用且强大的表示,通过其结构中编码的底层模式来描述不同类型实体之间的丰富关系。然而,图生成的数据收集过程充满了已知或未知的样本选择性偏差,尤其是在非平稳和异构的环境中,实体之间会存在虚假关联。针对从具有选择性偏差的多个环境中学习稳定图的问题,崔鹏老师团队设计了一个无监督的稳定图学习 (Stable Graph Learning, SGL) 框架,用于从集合数据中学习稳定图,该框架由GCN (Graph Convolutional Networks) 模块和针对高维稀疏集合数据的E-VAE (element-wise VAE) 模块组成。
稳定图学习的任务是学习一个表示无偏连接结构的图Gs,因为环境中的图是从数据生成的,如果数据的收集过程来自具有选择性偏差的环境,则元素之间的虚假相关性会导致图在其他环境中表现不佳。SGL框架能很好地解决这个问题,SGL框架可以分解为两个步骤,包括基于图的集合生成和稳定图学习。稳定图学习过程图解如下图所示。
在模拟实验中,如图所示,在几乎所有的实验中,SGL框架的性能要稳定得多,特别是当两个环境之间的差异更显着时,它比所有基线方法都达到更高的平均准确度。
模拟实验结果。每个子图对应一个实验,紫色曲线表示SGL框架生成的图Gs的实验表现
而相应地,在真实实验里,崔鹏老师团队研究了商品推荐的常见实际应用中的稳定图结构问题。
从下表可以看出,SGL框架生成的图Gs可以平衡两种环境下的相关性,更稳定地达到最高平均预测率。
使用从商品网络中学习的项目嵌入进行带有曝光偏差的购买行为预测
如下表所示。SGL框架可以很好地弥补单一环境下的信息损失,通过学习商品之间的本质关系,生成整体性能最佳的图Gs。
使用从商品网络中学习到的项目嵌入来预测不同性别群体的购买行为
图生成的数据选择性偏差可能导致有偏差的图结构在Non-I.I.D.场景中性能不佳。针对该问题提出的SGL框架可以提高学习图的泛化能力,并能很好地适应不同类型的图表和收集的数据。
2、具有不可知分布偏移的图的稳定预测
图神经网络 (Graph Neural Networks, GNNs) 已被证明在具有随机分离的训练和测试数据的各种图任务上是有效的。然而,在实际应用中,训练图的分布可能与测试图的分布不同。此外,在训练GNNs时,测试数据的分布始终是不可知的。因此,大家面临着图学习训练和测试之间的不可知分布转变,这将导致传统GNNs在不同测试环境中的推理不稳定。
为了解决这个问题,浙江大学况琨老师团队提出了一种新的GNNs稳定预测框架,它允许在图上进行局部和全局稳定的学习和预测,可以减少异构环境中的训练损失,从而使GNNs能够很好地泛化。换句话说,是为GNNs设计了一种新的稳定预测框架,该框架能捕获每个节点的稳定属性,在此基础上学习节点表示并进行预测(局部稳定),并规范GNNs在异构环境中的训练(全局稳定)。该方法的本质如图所示。
整体架构
由两个基本组成部分组成,即在每个目标节点的表示学习中捕获跨环境稳定的属性的局部稳定学习,以及显式平衡不同训练的全局稳定学习环境。
在图基准实验中,浙江大学况琨老师团队使用OGB数据集和传统基准Citeseer数据集,构建两层GCN和GAT。所有其他方法(包括我们的方法)也包含两个图形层以进行公平比较。OGBarxiv的所有方法的隐藏层神经节点个数为250,Citeseer的隐藏层神经节点个数为64,学习率为0.002。
稳定预测框架有着更稳定的实验结果。当测试分布与训练分布的差异更大时,大多数GNNs会遭受分布变化并且产生较差的性能(例如,图a的右侧)。尽管稳定预测框架在分布更接近训练的测试环境中牺牲了一些性能(例如,图a的左侧),但获得了显着更高的 Average_Score 和更低的 Stability_Error。
为了证明稳定预测框架在实际应用中的有效性,浙江大学况琨老师团队收集真实世界的嘈杂数据集,对推荐系统的用户-项目二分图进行了实验。实验结果表明,稳定预测框架比其他基线方法取得了明显更稳定的结果。
具有由节点属性引起的分布偏移的真实世界推荐数据集的结果
二、深度神经网络中的稳定学习
基于深度神经网络的方法在测试数据和训练数据共享相似分布时取得了惊人的性能,但有时可能会失败。因此,消除训练和测试数据之间分布变化的影响对于构建性能有希望的深度模型至关重要。崔鹏老师团队建议通过学习训练样本的权重来消除特征之间的依赖关系来解决这个问题,这有助于深度模型摆脱虚假关联,进而更多地关注判别特征和标签之间的真正联系。
崔鹏老师团队提出了一种称为StableNet的方法。该方法通过全局加权样本来解决分布偏移问题,以直接对每个输入样本的所有特征进行去相关,从而消除相关和不相关特征之间的统计相关性。这是一种基于随机傅立叶特征 (Random Fourier Features, RFF) 的新型非线性特征去相关方法,具有线性计算复杂度。同时,它也是有效的优化机制,通过迭代保存和重新加载模型的特征和权重来全局感知和消除相关性,还能在训练数据量大时减少存储的使用和计算成本。此外,如图16所示,StableNet可以有效地剔除不相关的特征(例如,水)并利用真正相关的特征进行预测,从而在野外非平稳环境中获得更稳定的性能。
当识别狗的训练图像包含很多水时,StableNet模型主要关注于狗
StableNet的整体架构
为了涵盖更普遍和更具挑战性的分布变化案例,崔鹏老师团队在实验中采用如下四种设置:非平衡、灵活、对抗、经典。在不同的实验设置下,StableNet都能不同程度得优于其他方法。
在消融研究中,通过随机选择用于计算具有不同比率的依赖关系的特征来进一步降低特征维度。下图显示了具有不同维度随机傅里叶特征的实验结果。
消融研究的结果
图像分类模型的一种直观解释是识别对最终决策有很大影响的像素。所以,在显着性图像上,为了演示模型在进行预测时是关注对象还是上下文(域),对类别得分函数相对于输入像素的梯度进行了可视化。可视化结果如图所示。
StableNet的显着性图像。像素越亮,它对预测的贡献就越大
各种实验结果表明,StableNet方法可以通过样本加权消除相关和不相关特征之间的统计相关性,进而有效剔除不相关的特征并利用真正相关的特征进行预测。
三、稳定学习与公平性
如今,公平问题已经成为了决策系统中的重要问题。已经有很多学者提出了各种公平的概念来衡量算法的不公平程度。珀尔研究了伯克利大学研究生入学性别偏见的案例。数据显示,总体而言,男性申请人的入学率较高,但在研究院系选择时,结果有所不同。由院系选择引起的偏差应该被认为是公平的,但传统的群体公平观念由于没有考虑院系选择而无法判断公平。受此启发,基于因果关系的公平理念应运而生。在这些论文中,作者首先假设了特征之间的因果图,然后,他们可以将敏感属性对结果的不公平因果效应定义为一个度量。然而,这些公平性概念需要非常有力的假设,而且它们不可扩展。在实践中,经常存在一组我们称之为公平变量的变量,它们是决策前的协变量,例如用户的选择。
公平变量并不会影响评估决策支持算法的公平性。因此,崔鹏老师团队通过设置公平变量将条件公平定义为更合理的公平度量。通过选取不同的公平变量,崔鹏老师团队证明了传统的公平概念,例如统计公平和机会均等,是条件公平符号的特例。并且提出了一种可求导的条件公平正则化器(Derivable Conditional Fairness Regularizer, DCFR),它可以集成到任何决策模型中,以跟踪算法决策的精度和公平性之间的权衡。
DCFR的框架
为了公平比较,在实验中,选择也使用对抗性表示学习的方法来解决问题的公平优化算法作对照。有UNFAIR、ALFR、CFAIR和LAFTR,以及它的变体LAFTR-DP和LAFTR-EO。
各种数据集(从上到下依次为收入数据集、荷兰人口普查数据集、COMPAS数据集)上不同公平性指标(从左到右依次为Δ 、Δ 、Δ )的准确性-公平性权衡曲线。DCFR以粗线显示。
很明显,在实验中DCFR更有优势,在准确性和公平性上达到更好的权衡效果。对于统计公平和机会均等任务,DCFR的退化变体能有与专为这些任务设计的最先进基线方法相当的性能,有时甚至还能有更好的结果。综上所述,DCFR在真实数据集上非常有效,并在条件公平目标上取得了良好的性能。并且随着公平变量的数量增加,其表现会更好。
四、稳定学习与领域自适应
稳定学习最初的定义是不需要目标域信息的,这里的领域自适应是一种利用了目标域信息的做法,可以理解为拓展了最初的稳定学习的含义。
研究表明,深度神经网络学习到的表征可以转移到我们没有充足标记数据的其他领域中,并进行类似的预测任务。然而,当我们过渡到模型中的更高神经层时,表征变得更加适用于特定任务而不通用。关于这个问题,深度域适应的研究提出通过强制深度模型学习更多跨域可迁移的表征来缓解。这其实是通过将域适应方法整合到深度学习管道中来实现的。然而,相关性并不总是可转移的。亚利桑那州立大学(Arizona State University,ASU)刘欢老师团队提出了一个用于无监督域适应 (Deep Causal Representation learning framework for unsupervised Domain Adaptation, DCDAN) 的深度因果表示学习框架,以学习用于目标域预测的可迁移特征表示,如图22所示。其实就是使用来自源域的重新加权样本来模拟虚拟目标域,并估计特征对结果的因果影响。
DCDAN由一个正则化项组成,该正则化项通过平衡从数据中学习到的特征表示的分布来学习源数据的平衡权重。这些权重的设计有助于模型捕捉特征对目标变量的因果影响,而不是它们的相关性。此外,我们的模型包括深度神经网络的加权损失函数,其中每个样本的权重来自正则化项,损失函数负责学习预测域不变特征,以及将学习到的表征映射到输出的分类器或因果机制。将学习组件的样本权重嵌入到模型的管道中,并将这些权重与表征联合学习,这样不仅可以从深度模型中受益,还能学习对目标具有可转移性和良好预测效果的因果特征。
DCDAN生成的数据集中样本示例(EQ2)和热图。(a)显示了来自数据的示例图像,图23(b)显示了从VQA-X数据集中提取的图23(a)的因果特征的基本事实,图23(c) 显示了DCDAN为因果表征生成的热图
为了验证该框架的有效性,亚利桑那州立大学(Arizona State University,ASU)刘欢老师团队将ResNet-50、DDC、DAN、Deep CORAL、DANN、HAFN设置为对照方法来进行实验。
在实验中,DCDAN在许多情况下优于基线方法,结果表明DCDAN可以执行无监督的域自适应,显示了它在学习因果表示方面的有效性。而且这还验证了因果特征表示有助于学习跨域的可迁移特征,进一步证实了因果损失和分类损失之间的良好权衡可以导致学习更多可转移的特征。
因果启发的稳定学习研究进展
一、清华大学崔鹏:关于分部外泛化和稳定学习的一些思考
近年来,分布外(OOD)泛化问题广泛引起了机器学习和计算机视觉等领域研究者的兴趣。以监督学习为例,我们希望找到一个模型 f 以及其参数 θ,使得我们能够在测试数据分布上最小化
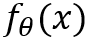
和y之间损失的期望。
原则上说,我们测试时的数据分布是未知的,为了对其进行优化,传统的机器学习方法认为训练数据和测试数据满足独立同分布假设,从而对问题进行简化,使我们可以在训练数据分布下搜索带有参数 θ 的函数 f。
然而,这种简化的问题设定无法满足许多实际应用场景的要求,我们往往很难保证测试时和训练时的数据分布一致。通过上述方式学习到的
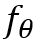
缺乏理论保障,模型在真实的测试环境下的性能与实验室中训练时的性能可能相差甚远。为此,一些研究人员开始研究分布外场景下的学习问题。
根据测试时数据分布的不同,分布外学习问题衍生出了两条技术路径:
(1)分布外域自适应:测试数据(目标域)部分已知,基于域自适应/迁移学习技术,将利用训练数据(源域)得到的模型适配到不同的数据分布(目标域)下
(2)分布外泛化:测试数据分布完全未知。
在传统的独立同分布学习场景下,模型泛化是一种内插(Interpolation)泛化,在分布外学习场景下,模型泛化则指的是外推(Extrapolation)。
如上图所示,在独立同分布场景下,如果 参数量太少,则模型对数据欠拟合;若参数量过多,则模型可能对数据过拟合。论文「Direct Fit to Nature:An EvolutionaryPerspective on Biological and Artificial Neural Networks」的作者认为,过参数化的深度学习网络之所以具有较好的泛化能力,可能是由于模型用类似折线的形式直接对数据点进行了拟合。
如果我们直观测到整体中很小的一部分数据,就需要对未观测到的数据进行外推。传统上,我们需要进行精巧的实验设计,基于小量的观测数据推理出分布外的情况。在这一过程中,我们会引入大量人类总结出的一些通用规律,从而实现数据的外推。
正所谓「以不变应万变」,「不变性」(invariance)是实现外推的基础。例如:牛顿观察到苹果从树上落下,从而推导出万有引力定律,进而可以将这一规律外推到其它物体的运动上。
在独立同分布场景下,由于我们认为训练数据和测试数据分布相同,我们的目标是数据拟合,此时「相关性」自然成为了一个很好的统计指标。在 OOD 场景下,我们旨在通过以下两条路径寻找「不变性」:
(1)因果推理
(2)从变化中寻找不变性
1、因果推理
因果推理是一种与不变性相关的科学。在经典的因果模型中,我们试图控制X,寻找 T 的变化对 Y 的影响。具体而言,利用观测数据,我们会通过样本重加权(Sample Reweighting)将 T=1 和 T=0 时的样本具有相似的 X 分布,如果这两种情况下的 Y 有显著变化,则 T 对 Y 有因果效应。此时,我们估计出的 T 对 Y 的因果效应平均而言对于 X的变化是具有不变性的。
为了将不变性适配到学习框架中,我们要研究多个输入变量对输出变量预测性的影响。在稳定学习框架下,我们试图找到一组合适的样本权重,进行样本重加权后再通过输入变量对输出变量进行回归,此时的回归系数即为满足因果关系的回归系数。通过上述方式训练出的模型具有 OOD 的泛化能力。
2、从变化中寻找不变性
变化与不变性是对立统一的。在机器学习场景下,数据中的「变化」指的是训练数据中存在的异质性(例如,图像背景的不同、物体品类的不同)。然而,我们无法手动定义这种数据的异质性,因为我们无法保证数据在所有的特征维度上都满足不变性约束。
因此,一种可行的方式是从潜在的异质性中寻找不变性。我们假设环境是未知的,存在一定的异质性。在这种情况下,我们首先需要发现数据中的异质性,再根据数据的异质性发现其中的不变性,接着我们还可以反过来利用不变性提升对变化部分(异质性)的学习效果,这一过程将一直迭代下去。
3、稳定学习的定位
在稳定学习框架下,我们利用一个异质的数据分布学习模型,希望将学习到的模型应用到一系列未知数据集上时具有一定的性能保证。除了通过实验证明此类模型的有效性,我们还希望为其发展出理论的支撑。
二、清华大学张兴璇:StableNet——用于分布外泛化的深度稳定学习
我们具体来讨论深度稳定学习,比如我的训练图片中是很多狗都在草地上,然后少量的狗在其他背景上时,那么它需要能及及时分辨出草地上的狗,通常这个模型可以给出比较准确的预测。但是当给到一个他建的比较少的背景,他可能就会不一定给出一个准确的预测,但大部分可能还可以给出类似的预测,但是当它出现了一个他完全没有见过的背景的时候,这个模型很有可能就给出一个错误的预测。所以说这种分布偏移的问题,会给现在的深度网络带来很大的挑战。
对于当下基于独立同分布假设开发的深度学习网络而言,若训练数据和测试数据分布不一致时,模型的泛化性能将会较差。如上图所示,假设训练集包含大量背景为草地的狗,如果在测试时面对一张站在草地上的狗的图片,网络一般可以准确地对图片进行预测;然而,如果测试图片中的背景在训练集中出现地较少或从未出现,则网络的预测效果很可能较差。这种分布偏移问题是当前的深度学习网络面临的重大挑战之一。
之所以会出现上述问题,是因为网络学习到的很可能是数据之间的相关性。在上图中,由于训练集中大量存在「狗站在草地上」的样本,因此草地的特征和狗的图像特征之间建立了关联,进而在草地的特征和狗的标签之间建立了关联,导致在测试集上对其它背景图片的预测性能有所下降。
为了解决上述问题,我们试图转而抽取因果特征(例如,部分和整体的因果关系)。在稳定学习框架下,我们重点关注的是物体本身的因果特征,而非环境的特征。
如上图所示,ResNet18(第二行)网络不仅关注狗的特征,也关注到了背景的无关特征,而 Stable Net 则主要关注狗本身的特征。
具体而言,我们采用全局平衡(Global Balancing)方法提取因果特征。给定任意的干预(treatment),我们对训练样本进行加权,从而消除各类特征之间的统计关联性,断开背景与因果特征之间的关联,最终找到更加具有因果关系的特征,实现更加稳定的预测。
先前的稳定学习方法主要针对较简单的模型(例如,线性模型)开发,考虑的问题主要是消除特征之间的线性相关性。然而,在深度网络中,各类特征之间的相关性通常是非常复杂的非线性相关性。因此,StableNet 首先将所有的特征映射到其随机傅里叶特征的空间中,该步骤将较低维度空间中的特征映射到较高维度的空间中;接着,我们在较高维度的空间中去掉各类特征的线性相关性;这样以来,我们就可以去掉原始的特征空间中特征之间的线性相关性以及非线性相关性,保证特征的严格独立。
此外,原始的全局重加权方法需要对所有的样本进行操作。然而,在深度学习场景下,训练样本量一般非常大,我们无法对全局样本进行加权。为此,我们提出了一种预存储的方式,将网络之前见过的特征和样本权重存储下来,进而在新的一轮训练中结合当前的特征进行重加权。
StableNet 的网络架构如上图如所示。网络架构有两个分支,下面的分支为基本的图像分类网络,上面的分支是对样本进行 RFF 映射后再进行重加权的过程。我们可以将两个分支分离开来,从而将StableNet 插入到任何深度学习架构中。
目前,在计算机视觉领域的域泛化任务中,我们往往假设训练数据中的异质性十分显著,且各个域的样本容量相当。这在一定程度上限制了在 CV 领域中对 OOD 泛化方法进行验证。
本文作者基于 PACS 和 VLCS 两个数据集构建了各个图片域数量不平衡的实验环境,有一些图片域占据主导地位,具有更强的虚假关联。在该设定下,StableNet 相较于对比基线具有最佳的泛化性能。
在更加灵活的 OOD 泛化场景下,不同类别的图像所处的域可能不同。在该场景下,StableNet 的性能仍优于所有的对比基线。
在对抗性 OOD 泛化场景下,域和标签的虚假关联很强(例如,训练集中的大部分数字 1 的颜色为绿色,数字 2 为黄色;在测试时两种数字的颜色与训练集中相反)。StableNet 在几乎所有的实验设定下都超过了现有的方法。
三、浙江大学况琨:通过工具变量回归实现因果泛化
1、因果关系与稳定学习
如前文所述,现有的基于关联关系的机器学习算法存在一定的不稳定性。为此,研究者们提出了稳定预测/学习的框架,重点关注对未知的测试数据进行准确、稳定的预测。
现有的机器学习算法之所以不稳定,是因为这些算法是关联驱动的,而数据中存在大量的偏差,可能会导致模型提取出一些非因果关系的特征(虚假关联),从而导致模型不可解释、不稳定。为此,我们试图恢复出每个特征变量和标签 Y 之间的因果关系,从而找出因果特征。
2018 年,崔鹏老师、况琨老师等人提出了因果正则化技术,通过学习到全局权重使得变量之间相互独立,通过将该技术应用到逻辑回归、浅层深度网络等模型上,可以取得一定的性能提升。这种寻找因果关系的过程要求我们能够观测到所有的特征,然而有时一些因果特征是我们无法观测到的。
2、工具变量回归
在因果科学领域,研究者们以往通过工具变量(InstrumentalVariable)处理未观测到的变量。如上图所示,假设我们需要估计 T(干预)和 Y(结果)之间的因果效应,U 为未观测到的变量。工具变量 Z 必须满足以下三个条件:(1)Z 与 T 相关(2)Z 与 U 相互独立(3)Z 需要通过 T 影响 Y。
找到合适的工具变量 Z 后,我们可以通过二阶段最小二乘方法估计 T 与 Y 之间的因果效应。在第一阶段,我们根据 Z 回归 T,从而得到
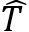
;在第二阶段,我们根据回归 Y,从而估计出T 与 Y 之间的因果函数。在上图左下角的例子中,黄色的曲线代表直接用神经网络回归的结果,红色的曲线代表引入工具变量后通过二阶段最小二乘回归得到的结果。实验结果表明,红色的曲线对原函数的拟合程度更好。
原始的工具变量回归方法以来于一些较强的线性假设。为此,近年来一些计算机研究人员提出了非线性的工具变量回归算法(例如,DeepIV、KernelIV 等)。从理论上说,在第一阶段,我们通过 Z 和 X 回归 T,得到
;在第二阶段,我们通过和 X 回归 Y。此时,回归函数是非线性的。
然而,在实验中,DeepIV、KernelIV 等方法的效果并没有达到预期,这是因为第一阶段的回归为第二阶段引入了混淆偏差。在这里,我们考虑将混淆因子均衡引入工具变量回归中,从而解决这种混淆偏差问题。具体而言,在第一阶段的回归之后,我们会学习一种均衡的混淆因子表征
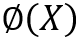
,使得与无关。接着,在第二阶段,我们通过和回归 Y。
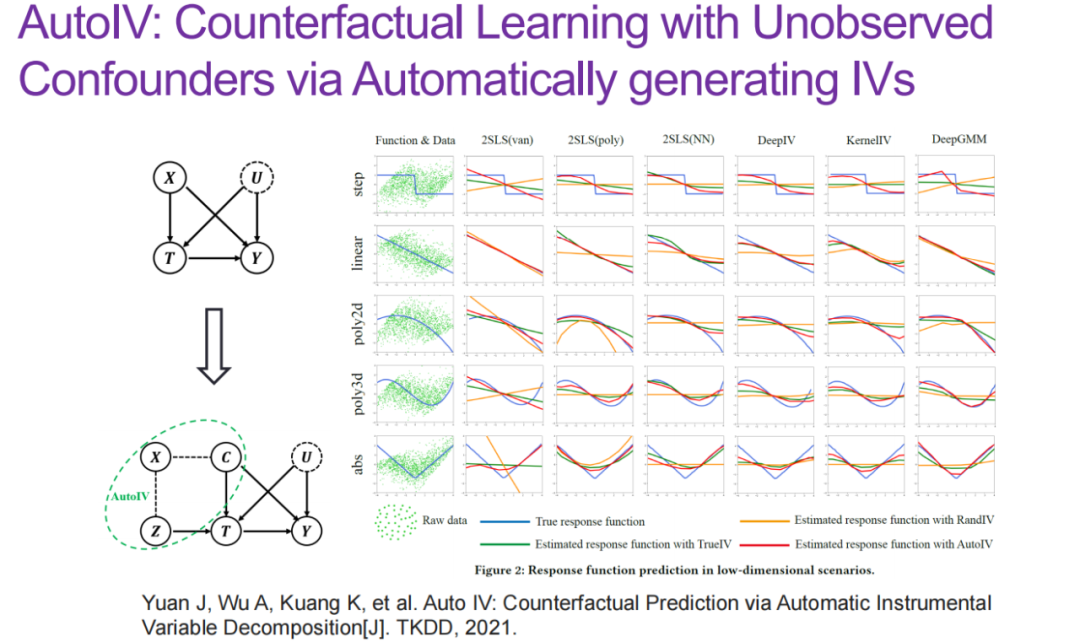
在使用原始的工具变量回归方法时,我们往往需要预先定义一个工具变量。在论文「Auto IV:Counterfactual Prediction viaAutomatic Instrumental Variable Decomposition」中,况琨博士等人在给定干预 T,输出结果 Y,观测到的混淆因子 X,未观测到的混淆因子 U 的情况下,从观测到的混淆因子 X 中解耦出工具变量。尽管分理出的工具变量可能不具备明确的物理意义,但是它满足前文提到的工具变量所需要满足的三个属性。这样生成的工具变量可以帮助我们估计 T 和 Y 之间的关系。具体而言,我们通过互信息判断特征之间的条件独立性,以及表征学习实现解耦操作。
3、通过工具变量回归实现因果泛化
工具变量回归可以被用于域泛化、不变因果预测、因果迁移学习等任务中。以域泛化为例,给定来自不同观测环境中的数据,该任务旨在利用给定的 X 预测 Y。我们希望从多个数据域(环境)中学习不变性,使得预测模型对于所有可能的环境都鲁棒。
在通过工具变量回归解决域泛化问题时,首先,我们通过因果图刻画各个域中数据的生成过程(DGP)。对于域 m,在生成样本数据 X时,除了样本的域不变性特征之外,还可能受到域特定特征(例如,光照、天气)的影响;在为样本打标签时,标注者除了会考虑图片样本特征,也会受到域特定特征的影响。
在这里,我们假设各个域间具有不变性特征,且 X 和 Y 之间的关系是不变的。纵观多个域中的数据生成过程,域 n 中的样本
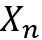
恰好是域 m 中样本的工具变量,满足上述工具变量的三个特性。因此,我们可以通过工具变量回归的方式学习 X 和Y 之间的因果效应 f。
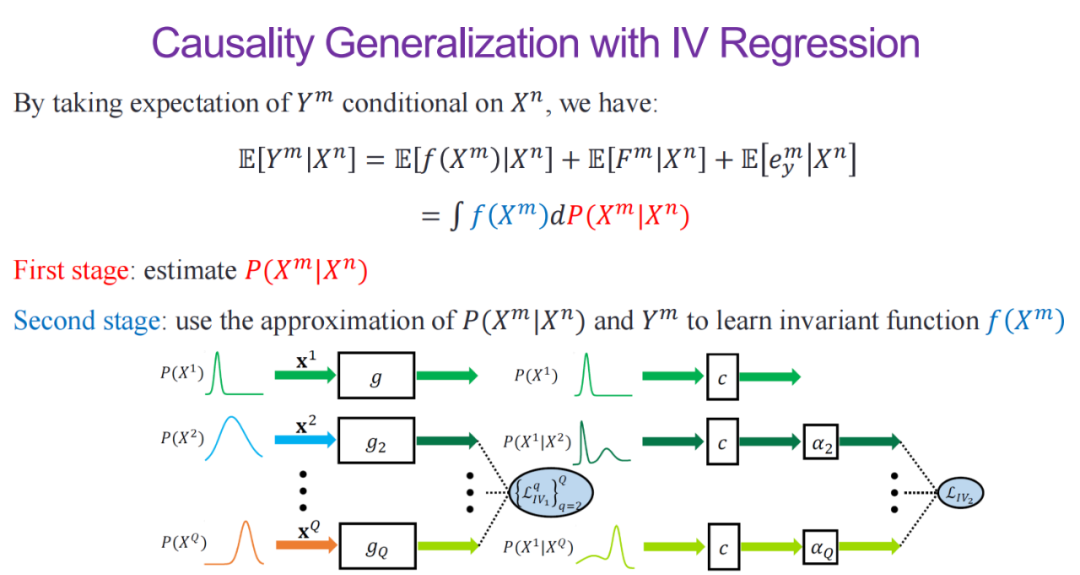
在具体的求解过程中,我们首先通过工具变量回归,即估计。接着,我们利用近似出的和学习不变性函数。值得注意的是,在通过工具变量进行域泛化时,我们只需要一个域中的标签Y,以及其它域中的无标签数据 X。
四、清华大学刘家硕:从异质性数据到分布外泛化
1、分布外泛化的背景
经验损失风险最小化(ERM)是目前最常用的优化算法,该算法优化的是所有数据点的平均损失,所有样本的权重都是1/N。如上图所示,当数据中存在异质性时,数据集中的样本分布并不均衡。因此,通过 ERM 算法进行优化可能会更加关注出现较多的群体,而忽视出现较少的群体对损失的影响。
具体而言,在真实场景中,我们采集到的不同来源的数据分布可能不均衡,存在一定的异质性。通过 ERM 对模型进行优化时,尽管可以在整体上获得较高的准确率,但这可能是由于模型对数据集中多数群体的预测性能很完美,而在少数群体上的预测效果并不一定很好。
如上图所示,当训练数据分布与测试数据分布一致时,若使用 ERM 算法进行优化,模型的泛化性能是有理论保证的。然而,如果数据的分布出现了偏移,则 ERM 算法的得到的模型的泛化性能可能较差。
因此,我们应该充分考虑数据的异质性,设计更加合理的风险最小化方法,为不同的样本点施加合适的权重,使得模型对多数群体和少数群体都有较好的预测能力,从而提升模型的泛化性能。
如上图所示,OOD 泛化问题旨在保证模型在发生分布偏移时的泛化能力,即通过「min-max」优化找到一组参数
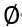
,使得模型在最差的环境下的表现性能能够接受。考虑到分布偏移的情况,在不同环境下采集到的数据的 X 和 Y 的联合分布也有所区别。
2、异质性风险最小化
我们从不变性学习的角度试图解决 OOD 泛化问题。在此,我们假设随机变量
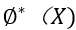
满足以下假设:(1)不变性假设:在不同的环境下,特征与标签 Y 的关系是稳定不变的(2)充分性假设:标签 Y 可以完全由产生。基于以上两点假设,使用特征做预测可以以较高的准确率实现跨环境的稳定预测,是一种具有因果效应的不变特征。
要想找到上述不变特征,我们需要对环境有很强的约束。现有的许多不变性学习方法都会针对从多个环境中寻找符合上述性质的特征。然而,在真实情况下,许多数据集是收集自多个不同数据源的混合数据,我们往往很难为环境保留明确且对模型学习真正有效的标签
针对混杂环境下数据存在异质性的现象,刘家硕博士等人提出了异质性风险最小化框架(HRM)。首先,我们假设数据中存在跨环境变化十分剧烈的部分
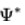
,不同环境下的 与 Y 的关系存在差异。
接着,我们将异质性风险最小化问题定义为:给定存在异质性的混合数据集D,在缺乏环境标签的条件下,旨在学习到不变性特征的集合,使模型具有更好的 OOD 泛化能力
如上图所示,HRM 算法框架包含以下两个模块:
(1)异质性识别模块
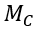
(2)不变性预测模块

。在不断的迭代中,上述两个模块会相互促进。
具体而言,我们首先通过模块
学习混合数据集中不稳定的特征,识别出数据中具有异质性的环境,得到具有强异质性的环境。接着,我们通过不变性学习模块学习中不变的特征。
数据中存在相互依赖的变化的部分和不变的部分,我们对学到的不变特征

进行转化,可以得到变化的特征,二者相互促进。为了得到较好的理论性质,作者在本文中重点关注较为简单的数据,通过上图中的简单特征选择过程得到和。
3、核异质风险最小化
HRM 算法无法处理复杂的数据(例如,图片、文本)。在 KerHRM 中,刘家硕博士等人将 HRM 算法拓展至更加复杂的数据类型上。
在 HRM 算法流程的基础之上,刘家硕博士等人在 KerHRM 中引入了神经正切核(NTK)。根据 NTK 理论,神经网络(例如,MLP)的操作等价于在复杂的特征空间中进行线性回归。
如上图中的公式(5)所示,假设神经网络的参数为 w,输入数据为 X。对

在的位置的做泰勒展开,根据模型参数的一阶泰勒展开式可以发现的作用相当于在梯度项上做线性操作。因此,通过 NTK 技术,我们可以将复杂的神经网络操作转变为在神经正切特征上进行线性回归。
通过上述方式,我们可以将 HRM 应用到较为复杂的数据上,同时保留 HRM 框架的特性。KerHRM通过构造一组正交的核区分数据中稳定和不稳定的部分。
4、仿真实验:Colored MNIST
本文作者采用与论文「Invariant RiskMinimization」中相同的实验设定,测试了 KerHRM 方法在 Colored MNIST 数据集上的性能。在该实验环境下,作者将 MNIST 中 0-4 的数字标记为「0」类,将「5-9」的数字标记为「1」类,从而将十分类问题改造为了二分类问题。接着,作者将「0」类中大部分的图片染成某种颜色,将「1」类中大部分的图片染成另一种颜色,从而构建了数字标签和颜色之间的虚假关联。在测试时,我们将图片的染色情况翻转过来,此时传统的机器学习模型的性能往往会大幅下降。
实验结果如上图所示,随着迭代轮数的增加,KerHRM 框架学习到的环境的异质性逐渐变大,测试时的预测准确率也递增。同时,训练时和测试时准确率的差距在逐渐缩小。可见,OOD 泛化的性能和我们构造的环境的异质性程度呈十分强的正相关,异质性对于 OOD 泛化性能十分重要。因此,环境标签的质量(异质性)对于泛化性能也会有很大的影响。
五、清华大学何玥:分布外泛化图像数据集——NICO
1、非独立同分布图像分类
图像分类是计算机视觉领域中最基础、最重要的任务之一。在传统的独立同分布假设下,通过最小化训练集上的经验损失,现有的深度学习模型已经可以在测试时达到很好的预测性能。然而,在真实情况下采集到的数据集很难满足独立同分布假设,训练集几乎不可能覆盖所有的测试样本中的数据分布情况。此时,如果我们依然通过最小化模型在训练集上的经验损失来优化模型,往往会导致模型在测试时的性能严重下降。
如上图所示,训练数据和测试数据中猫和狗所处的背景差异很大,并不满足独立同分布假设,深度学习模型可能会错误地将背景当做对图片进行分类的标准。而人类对此类分类问题则天然地具有很强的泛化能力,好的分类模型也应该对这种背景分布的变化不敏感。

我们将该问题称为非独立同分布的图像分类问题,其中训练集和测试集中的数据分布不同。此类问题包含两种子任务:
(1)Targeted Non-I.I.D 图像分类:测试集中的部分信息已知,我们可以借助迁移学习等方法将当前训练好的模型迁移到目标域的数据分布上,实现较好的预测性能
(2)General Non-I.I.D 图像分类:利用不变性等机制,将学习到的模型以较高准确率泛化到任意未知数据分布上。
实际上,非独立同分布场景下的学习问题对计算机视觉任务十分重要。在自动驾驶、自动救援等场景下,我们希望模型能够迅速识别不常见但非常危险的情况。
2、衡量数据分布差异

为了刻画分布之间的差异,我们定义了一种名为「NI」的指标。在计算 NI 的过程中,我们利用预训练好的通用视觉模型提取图像特征,然后在特征层面上计算两个分布之间的一阶矩距离,并采用分布的方差进行归一化。大量实验证明,NI 对图像分布差异的描述是较为鲁棒的。此外,在有限采样的情况下,数据分布偏差无处不在,随着数据分布偏差变强,分类模型的错误率也不断提升。
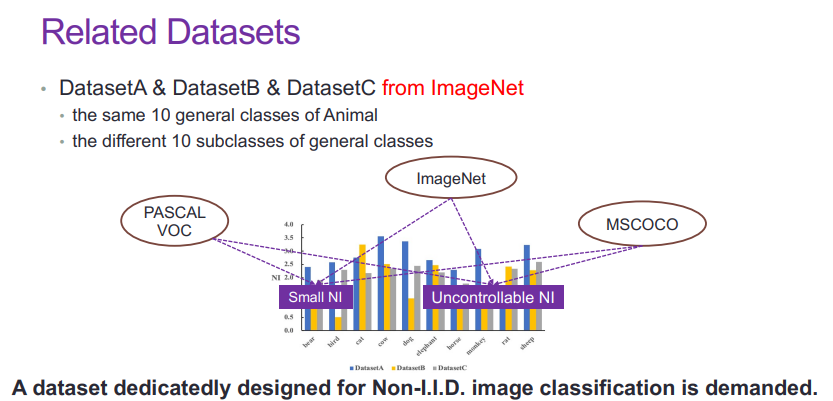
实际上,分布偏移现象广泛的存在PASCAL VOC、ImageNet、MSCOCO 等标杆数据集中。以 ImageNet 为例,我们首先选取了 10 个常见的动物类别,然后针对每类动物选取不同的子类,形成了不同的三个数据集 A、B、C。
接着,我们采集了一些固定的测试样本。通过测量 NI,我们发现不同的数据集存在数据分布偏差,但是这种偏差较弱,且这种数据偏差不可控,分布偏差的大小随机。为了推动 OOD 泛化在视觉领域的研究,我们构建了存在明显的数据分布偏差,且偏差可调节的视觉数据集——NICO。
3、NICO数据集
首先,我们考虑从图片中分解出主体和上下文的视觉概念。如上图所示,主体可能为猫或狗,上下文可能为主体的姿态、背景、颜色等概念。通过在训练和测试中组合不同的主体和上下文,我们可以形成数据分布的差异。
上下文概念来自于真实世界,我们可以从很多角度描述上下文,进而描述一种有偏的数据分布。当上下文和主体的组合有意义时,我们可以很容易地收集到足够多的图像。
目前公开的 NICO 数据集具有如上图所示的层次结构。动物和交通工具两个超类包含 9-10 个主体类别,每个主体类别拥有一系列上下文概念。我们希望上下文尽可能多样,且主体与上下文的组合有意义,各个上下文之间有一定的重叠。此外,我们要求每类主体和上下文组合的样本数量尽可能均衡,不同上下文之间的差异尽可能大。
和独立同分布的经典数据集相比,由于 NICO 引入了上下文概念,且图像是非中心化、非规则的,所以 NICO 数据集上的图像分类任务更加具有挑战性。
面对有限样本,无论如何采样都会产生一定程度的数据分布偏差,这是由图像本身的性质,以及采样规模的差异造成的。在 NICO 数据集中,我们通过随机采样的方式模拟近似独立同分布的场景。与ImageNet 数据集相比,确实 NICO 引入了非中心化性质/上下文概念,其识别任务更加困难。
4、OOD 泛化——比例偏差
当测试数据和训练数据分布存在「比例偏差」时,我们要求训练集和测试集数据都包含所有类别上下文,但是我们在训练和测试中选择不同的上下文作为主导上下文(在整采集的图像中占比较高)。通过在训练和测试中设置不同的主导上下文,我们可以自然地形成数据分布的差异。
在这里,我们还定义了「主导率」(Dominant Ratio)指标来刻画具有主导上下文的样本量具有其它上下文的样本量的比例。如上图所示,随着主导率的提升,训练和测试数据之间的分布差异越来越大,对模型准确率的影响也越来越大,
5、OOD 泛化——成分偏差
「成分偏差」模拟了我们在训练数据、测试数据采样时的时空限制。在该设定下,训练集并不包含所有类别的上下文,有一些测试集中的上下文是训练中未曾见过的。随着训练集包含上下文的种类减少,测试集和训练集的数据分布差异递增,模型学习的效果也越来越差。
为了实现更大的数据分布偏差,我们还可以组合成分偏差和比例偏差。我们可以要求某些类别上下文在训练集包含的上下文中占据主导地位,即通过同时调节训练集可见上下文的数量和主导率控制数据分布偏差的程度,进而观察模型在不同数据偏差场景下表现出的性能。
6、OOD 泛化——对抗攻击
在「对抗偏差」场景下,我们选择某些类样本作为正类,其它类别的样本作为负类。接着,我们定义某种上下文只出现在训练集的正类中,以及测试集的负类中。此时,模型就会错误地将该上下文与正类联系到一起,从而在测试时取得较差的性能。我们将这种上下文称为混淆上下文,随着混淆上下文比例的增加,模型对正类的学习越来越容易受到虚假关联的影响。
蓝海大脑深度学习解决方案
机器学习模型已经在许多面向互联网的场景取得成功。在诸如预测点击量或对图像进行分类等应用场景中,模型做出错误决策的代价似乎并不高,因此从业者采用“性能驱动”的模式优化人工智能技术,即只关注该模型在完成目标任务时体现出的性能而不太关注技术发生错误时的风险。当任务环境发生变化,预测出现错误的时候,人们通过频繁地更新黑盒模型以保证预测的性能。
然而,在诸如医疗保健、工业制造、金融和司法等与社会生活息息相关的领域,机器学习模型做出的错误预测的后果往往是难以接受的,这些场景也因此被称为风险敏感的场景。由于数据获取困难以及伦理问题,在风险敏感的场景中因为环境变化而重新训练机器学习模型的代价会比较昂贵,因此模型的短期预测性能之外的特性也十分重要。为了促进机器学习模型在更多风险敏感场景的应用,我们需要仔细分析机器学习模型面临的技术性风险,并采取办法克服这些风险。
蓝海大脑面向广大深度学习、机器学习、因果学习研究者、AI开发者和数据科学家提出稳定学习液冷解决方案,通过软硬件一体式交付,提供数据标注、模型生成、模型训练、模型推理服务部署的端到端能力,降低使用AI的技术门槛,让客户更聚焦业务本身,使AI业务能快速开发与上线。
该方案提供一站式深度学习平台服务,内置大量优化的网络模型算法,以便捷、高效的方式帮助用户轻松使用深度学习技术,通过灵活调度按需服务化方式提供模型训练、评估与预测。
一、优势特点
1、节能性更优
整体机房空调系统能耗降低70%;服务器风扇功耗降低70%~80%;液冷系统可实现全年自然冷却,PUE<1.1,整体机房风液混合冷却系统PUE<1.2
2、器件可靠性更高
CPU满载运行核温约40-50℃,比风冷降低约 30℃;服务器系统温度比风冷降低约 20℃
3、性能更优
CPU和内存工作温度大幅降低,可实现超频运行,计算集群性能可提高5%
4、噪声更低
液冷散热部分水循环噪音极低,风冷部分风扇转速降低,噪音减小,降低约30dB,满载运行噪音<60dB
5、率密度提升
单机柜功率密度可达25kW以上,相比风冷散热方式大幅提升
二、液冷服务器架构
超融合架构承担着计算资源池和分布式存储资源池的作用,极大地简化了数据中心的基础架构,通过软件定义的计算资源虚拟化和分布式存储架构实现无单点故障、无单点瓶颈、弹性扩展、性能线性增长等能力。通过简单方便的统一管理界面,实现对数据中心计算、存储、网络、虚拟化等资源的统一监控、管理和运维。
超融合基础架构形成的计算资源池和存储资源池直接可以被云计算平台进行调配,服务于OpenStack、EDP、Docker、Hadoop、HPC等IaaS、PaaS、SaaS平台,对上层的应用系统或应用集群等进行支撑。同时,分布式存储架构简化容灾方式,实现同城数据双活和异地容灾。现有的超融合基础架构可以延伸到公有云,可以轻松将私有云业务迁到公有云服务。
三、客户收益
1、节约能源
原有数电力使用成本在总体拥有成本TCO中占比最大。实现IT设备按需供电与制冷,让供电和制冷系统的容量与负载需求更为匹配,从而提高了工作效率并减少过度配置。
2、运维监管
帮助客户实现数据中心多层级、精细化能耗管理,通过多种报表确定能源额外损耗点 ,实现节能降耗。资产管理帮助用户制定资产维护计划,实现主动预警,动态调整维护计划,按照实际情况输出优化方案,构建最佳资产管理功能。














 2513
2513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









