







Triton 整体架构
Triton的整体架构图如下图所示:

- 首先要准备好一个model repository:保持需要serve的所有模型。
- load 所有模型:triton会根据模型的backend,把它运行在server端的硬件设备上,比如CPU/GPU,这样server端就准备好了
- client端发送请求:client端使用python/c++实现一个client,把请求发送到server端。发送可以通过网络HTTP/gRPC协议,也可以通过C API直接发送,不通过网络协议。
- 请求发回到服务端:triton把请求调度到相应的backend的instance上执行,执行之后的结果会通过同样的路径返回到client端。
详细操作
下面介绍每个步骤的具体操作:
- prepare the model repository:准备model的 repository,所需要的模型都存放在model repository中管理。
model repository必须满足下图的三级模型,triton才会识别。
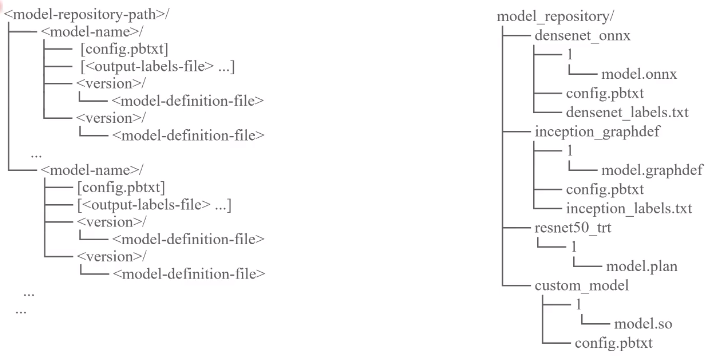
第一级模型目录是模型库的目录,第二级目录是具体要执行的推理模型的名字,第三级目录包含模型版本,模型配置文件,标签文件。 - 模型版本目录存放模型文件,支持tensorrt、onnx、pytorch、tensorflow等不同框架生成的模型。模型的版本必须和目录版本名称保持一致。
- 配置文件:定义模型和服务的配置参数
- 标签文件:分类模型使用,可以将模型输出的概率值直接转换成标签的字符串。
启动triton服务的命令为:
tritonserver --model-repository=/path/to/model/repository
tritonserver 是triton编译好之后生成的二进制文件
下面运行一个命令示例:
tritonserver --model-repository=./model-reop
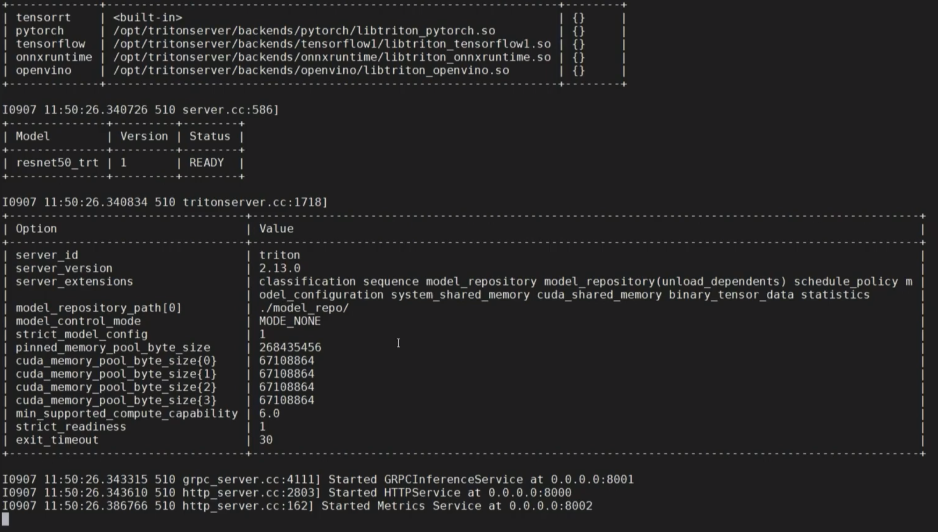
出现上面截图即代表triton服务启动成功
本文是triton教程的学习笔记,详细内容请前往上面链接。
















 2121
2121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











