







Fluent 中Domain和thread的个人理解
简单理解,Domain的级别要比Thread的级别高。
先看这个汇总
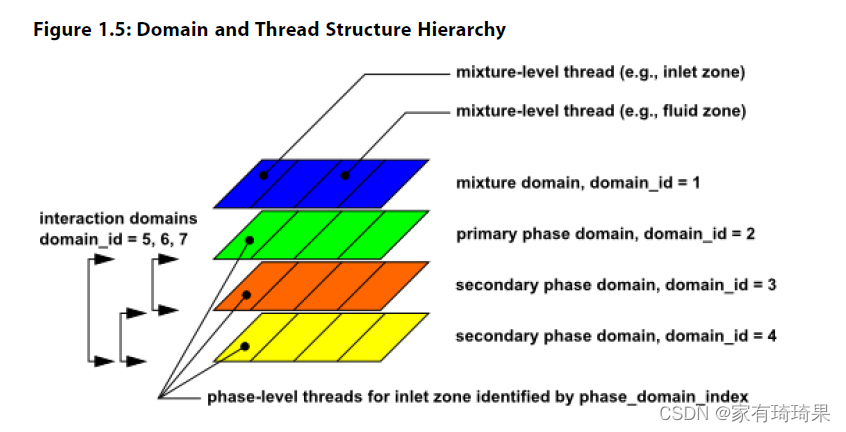
Domain
对于多相流,以焊接过程的两相为列,保护气和金属,空气和铝吧。焊接过程中始终有3个相场,混合相区域,空气相区域和铝相区域。
注意,混合相区域(mix-domain)ID始终为1.在其他的例子力也是一样的。另外的空气区域和铝的区域的ID看界面,如下:
空气相ID
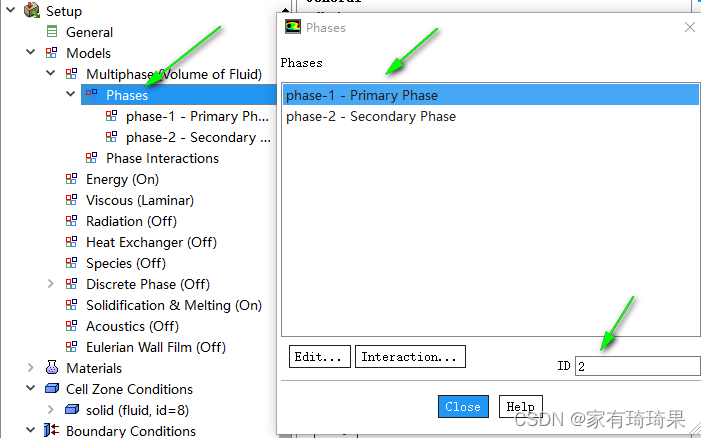 铝相ID
铝相ID
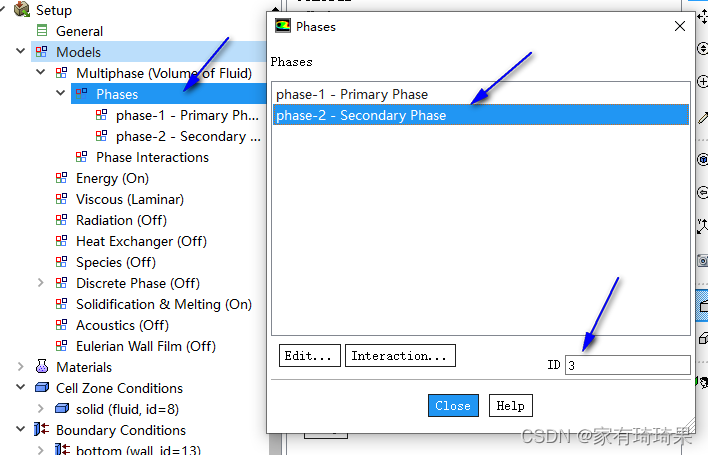
Domain_ID
目前用到的这个功能就在初始化的时候用过。用ID号来区分不同区域中的同一个位置的初始状态。
sub_domain_loop(subdomain,d,phase_domain_index)
{
if (DOMAIN_ID(subdomain) == 2)
thread_loop_c(t,subdomain)
{
begin_c_loop(c,t)
{
//判断
}
end_c_loop(c,t)
}
}
if (DOMAIN_ID(subdomain) == 3)
thread_loop_c(t,subdomain)
{
begin_c_loop(c,t)
{
//判断
}
end_c_loop(c,t)
}
}
DOMAIN_SUB_DOMAIN
DOMAIN_SUB_DOMAIN宏需要两个参数:混合相的domain指针及相索引。
混合相的domain指针由Fluent内核传递进来,相索引需要手工指定。
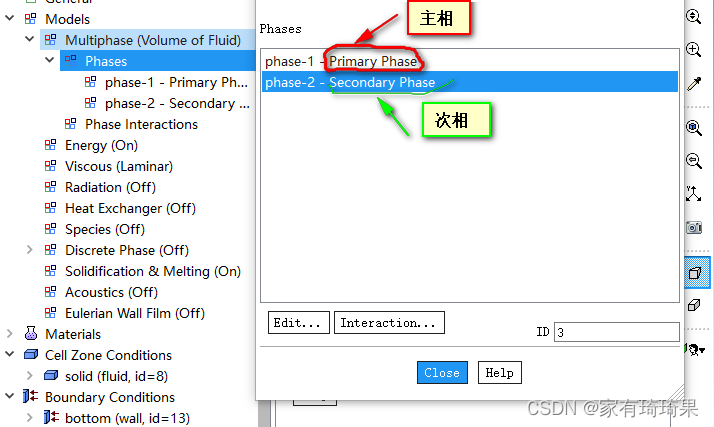
对于主相,其相索引为0,而次相的索引则按照Multiphase Model对话框中各相的排列顺序依次累加。如下图所示,主相的相索引为0,次相的索引为1。如何还有另外的相索引号就依次累加
/**********************************************************
这里要注意:这里的相的索引和ID号要区分!!
再次强调:主相索引为0,不是下面的ID号!!
/**********************************************************
Thread
前面找了区域(domain),接下来对区域中的体或者面操作的时候就要用thread了。
THREAD_SUB_THREAD
这里也要注意,与Domain类似,主相的索引始终为0,次相索引按对话框中相索引依次递加。
若已知主相和次相的Thread指针,也可以通过THREAD_SUPER_THREAD获取混合相的Thread指针。
可以参考这里:Fluent UDF中的Domain与Thread















 7740
7740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









