







具体的软硬件实现点击 MCU-AI技术网页_MCU-AI人工智能
声音事件的分类精度与特征提取有很强的关系。本文将深度特征用于环境声音分类(ESC)问题。深层特征是通过使用新开发的卷积神经网络(CNN)模型的全连接层来提取的,该模型通过频谱图图像以端到端的方式进行训练。特征向量由所提出的 CNN 模型的全连接层串联而成。为了测试所提出方法的性能,将特征集作为输入传送到随机子空间 K 最近邻 (KNN) 集成分类器。在 DCASE-2017 ASC和UrbanSound8K数据集上进行的实验研究表明,所提出的CNN模型的 分类准确率分别为96.23%和86.70%。
智能声音识别(SSR)是一种用于检测现实生活中存在的声音事件的现代技术。 SSR 主要基于分析人类听力系统并将这种感知能力嵌入人工智能应用中 。环境声音分类(ESC)是SSR的基本且必要的步骤。随着 SSR 在音 频监控系统、智能设备应用和医疗保健中的实际应 用 ,ESC 问题近年来引起了人们的广泛关注。ESC由两个主要部分组成:基于音频的特征和分类器。对于特征提取,音频信号首先使用窗函数(例如汉明窗或汉恩窗)划分为 帧。然后,从每帧中提取的这组特征用于训练或测 试处理。基于梅尔滤波器的特征(梅尔频率倒谱系数(MFCC)是 ESC 中常用的特征,其效率可以接受。此外,大量研究表明,在 ESC 任务中,串联 特征比仅使用一组特征表现更好。然而,更多串联 的传统特征无法提高分类性能。因此,适当的特征串联策略是声音分类的重要组成部分。人工神经网 络(ANN)、支持向量机(SVM)、隐马尔可夫 模型(HMM)和高斯混合模型(GMM)是声音 和其他类别中广泛使用的分类器。然而,这些传统 的分类器旨在对缺乏时间和频率不变性的明显变化 进行分类。近年来,深度学习(DL)模型已被证明 比传统分类器更能解决复杂的分类问题。卷积神经 网络(CNN)是最广泛使用的深度学习模型之一,训练CNN模型在几乎所有分类应用中都表现出了良好的性能。此外,由预训练的 CNN 模 型和传统分类器组成的混合方法已被用来提高分类性 能。如使用预训练的CNN模型提取深层特 征, SVM 和 KNN 算法用于高光谱图像分类。利用预先训练的CNN模型(例如AlexNet和 VGG16)从EMG信号中提取深层特征。使用 SVMclassi ̊er 可以实现最佳准确度。然而,流行的用于特征提取的预训练 CNN 模型无法完全表示声音特征,因为它们仅使用图像进 行训练。此外,ESC 问题并不总是需要识别高分辨率 图像所需的大输入量和非常深的网络结构。在这种状 态下,由于可学习参数的减少,获得了较低的计算成 本。本文针对ESC问题提出了一种由深度特征提取和 分类阶段组成的方法。为此,使用频谱图图像构建并 训练了端到端 CNN 模型。这样,我们就得到了自己 的预训练CNN模型。然后,丢弃所构建的 CNN 模型 的全连接层以进行特征提取。因此,获得了灵活的 CNN 架构,其中所有层的大小和数量都可以由作者 自由更改。在本研究的分类阶段,使用随机子空间 KNNensembles 模型,该模型使用子空间特征集中 的许多预测分数的投票。分类精度用于评估我们提出 的方法的性能。我们进一步将所提出的方法与其他预 训练的CNN模型和分类器的分类性能进行比较。与 UrbanSound˷K [5]和DCASE-2017 ASC [6]数据集上 的其他研究相比,所提出的方法的分类精度得到了显 着提高。本文的主要贡献是提出了一种新的 ESC 分 类 CNN 架构。所提出的 CNN 模型不太深,不会需要太多的训练时间。此外,所提出的新 CNN 模型 的成绩与预训练的 CNN 模型相当。
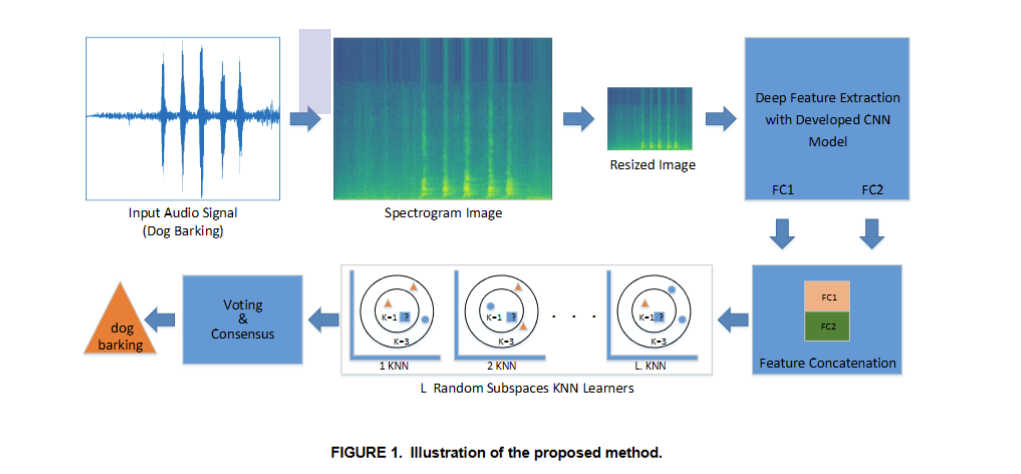
该方法的示意图如图1所示。该方法首先利用频谱图 方法将输入声音信号转换为时频图像。在实验过程中 调整了窗口类型、窗口长度和重叠大小等谱图参数。 随后,使用 viridis 颜色图保存频谱图图像,并调整 其大小以适合所提出的 CNN 模型的输入。所提出的 CNN模型如图2所示,由三个卷积层、三个最大池化 层和归一化层以及三个全连接层组成。 softmax 层 和分类层位于最后一个全连接层之后。所用数据集的 其余部分用于特征提取和测试过程。该特征集是通过 连接所提出的 CNN 的第一和第二全连接层的输出来 实现的。最后,使用鲁棒分类算法的随机子空间 KNN 系综测试了所提出方法的性能。

CNN 旨在处理取自多维数据的数据,即由三个 2D 数据(包括 3D 通道中的像素密度)组成的彩色图像。CNN 包括共享权重、局部连接、池化和其他层。卷积层、ReLU 层和池化层是最常用的 CNN 层。卷积层的基本目的是确定前一层特征的局部连 接,并将其信息映射到特定的特征图。ReLU 是一种非线性激活函数,应用 于使用卷积层创建的特征图。最大池化层的任务是组合 从前一层传递的相似特征。最大池化层通过计算与滤波 器重叠的特征图上的字段的最大值来实现下采样操作。CNN结构,其中从全连接(fc)层到分类层,一 般类似于多层感知器神经网络(MLP)。 fc 层的任务与 MLP 中的隐藏层相同。 fc 层将下一层中的每个神经元连接到前一层中 的每个神经元。Softmax 函数通常在 CNN 中使用,将 前一层的非归一化值与预测类别分数的可能性分布进行 匹配。批归一化层用于减少 CNN 的训练时间和对网 络初始化的敏感性。因此,该层是选择用于所提出 的 CNN 架构中的归一化过程。
随机子空间方法使用随机子空间集合来提高 k 最近 邻 (KNN) 分类器的分类精度。该方法基于随机操 作,在创建每个分类器时随机选择学习模型的多个 组件。该方法将训练数据集细分为随机子空 间,并利用随机子空间构成的训练集上的测试样本 进行欧几里德距离和切比雪夫距离计算。根据最近 邻的数量(K),最合适的子空间类成员由距离和 多数投票决定。然后,每个子空间集合附带的 类成员资格被组装在类向量 (C) 中。在 C 中以最高 平均分数实现分类。
在这项工作中,考虑了两个流行的数据集来评估 ESC 问题。 UrbanSound8K 数据集由十个类别标 签组成,包括空调、汽车喇叭、儿童、狗吠钻孔、 发动机空转、枪声、手提钻、警报器和街头音乐。 该数据集包含8732个音频文件,每个音频文件的录 制时长最长为4秒,音频文件以22.05KHz采样频率 录制。此外,音频文件的记录长度和每个类别中的 文件数量也不相同。 DCASE-2017 ASC数据集由 两部分组成,包括包含4680个音频文件的开发数据 集和包含1620个音频文件的评估数据集。每个音频 文件的持续时间为 10 秒。各类文件数量均衡,所 有音频文件均以44.1 KHz采样频率录制。该数据 集包含十五个类别,其中标签为海滩、公共汽车、 咖啡馆/餐厅、汽车、市中心、森林小路、杂货 店、家庭、图书馆、地铁站、办公室、公园、住宅 区、火车、电车。
DCASE-2017 ASC 数据集上所提出的方法与其他 CNN 模型和分类器的比较

UrbanSound8K数据集上所提出的方法与其他 CNN 模型和分类器的比较
















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









