







具体的软硬件实现点击 MCU-AI技术网页_MCU-AI人工智能
概要
手势识别是智能教育领域的关键技术,毫米波信号具有分辨率高、穿透能力强等优点。本文介绍了一种基于毫米波雷达的高精度、鲁棒的手势识别方法。该方法包括用毫米波雷达模块捕获手部运动的原始信号,并对接收到的雷达信号进行预处理,包括傅立叶变换、距离压缩、多普勒处理和通过运动目标指示(MTI)降噪。然后,将预处理后的信号输入卷积神经网络时域卷积网络(CNNTCN)模型,提取时空特征,并通过分类评估识别性能。实验结果表明,该方法在特定领域的识别中实现了98.2%的准确率,并在不同的神经网络中保持了一致的高识别率,表现出了卓越的识别性能和鲁棒性。
随着人工智能物联网的不断发展,人机交互变得越来越重要。手势交互由于其自然高效的特点,已成为研究的热点。它在各个领域都有广泛的应用,包括自动驾驶[1-2]和智能家居设备[3-4]。用户可以通过手势与数字设备进行无接触交互,从而增强用户体验。有各种传感器能够实现与数字设备的无接触手势交互,包括相机[5]、WiFi[6]和毫米波雷达[7-9]。尽管基于摄像头的手势识别提供了出色的识别性能,但由于照明条件和隐私问题,实际应用场景仍然面临重大挑战。基于WiFi的手势识别方法受到波长的限制,难以识别细粒度的手势,限制了其实用性。相比之下,毫米波手势交互技术具有精度高、鲁棒性强、隐私保护和低功耗等优点。为了利用这些优势,人们对使用毫米波雷达的手势识别进行了广泛的研究,通常将传统的机器学习技术与深度学习方法相结合。例如,张等人[10]利用了支持向量机(SVM)
对微多普勒信息进行分类,在0.3米的距离内对四个手势进行分类时达到了88.56%的令人印象深刻的准确率。然而,他们的方法涉及复杂的手动特征提取过程,导致识别精度有限。Dekker等人[11]试图使用3D-CNN对三种手势进行分类,结果表明识别率为91%。然而,3D-CNN在数据分辨率灵敏度和数据要求方面存在局限性。Ref等人的另一项研究[12]介绍了一种定制的多分支卷积神经网络(CNN),用于从连续手势中自动提取运动特征,在手势分类中实现了95%的准确率。然而,在他们的方法中使用单个卷积核限制了其完全捕获和集成手势的时间和空间信息的能力。为了克服这些限制,Chen等人[13]采用了CNN长短期记忆(LSTM)架构来捕获时间和空间信息,有效地增强了手势识别。然而,CNNLSTM模型通常需要大量的内存使用,具有较高的计算复杂性,并且高度依赖于环境因素。为了应对这些挑战,提高识别的准确性和鲁棒性,本文介绍了一种基于神经网络的手势识别方法。我们使用毫米波雷达来捕捉手势运动的原始信号,随后,通过预处理和神经网络技术,我们可以捕捉时间和空间变化,同时减少噪声干扰。这导致了手势识别的准确性和鲁棒性的提高。实验结果证实了我们提出的方法的有效性,展示了其在各种手势识别应用中的潜力。
FMCW 雷达原理
该实验使用了IWR1642,这是一种由德州仪器公司制造的商用低成本MIMO雷达模块。该雷达系统配备2根发射天线和4根接收天线,天线水平排列。为了实现8天线均匀线性阵列(ULA)的等效配置,雷达采用时分复用(TDM)模式。调频连续波(FMCW)雷达的处理流程图如图1所示。

数据预处理
本文提出了一种雷达信号预处理工作流程,旨在有效分析和处理接收到的雷达信号。该过程包括进行傅立叶变换、多普勒处理、降噪和其他技术,以将原始雷达信号转换为干净的距离频率多普勒图(RFDM)。该预处理过程便于后续的特征提取和分类。
一、傅里叶变换,雷达的原始接收信号是时域信号,因此很难观察到信号的频谱信息。快速傅立叶变换(FFT)是一种将时域信号转换为频域信号并有效计算离散傅立叶变换(DFT)的快速算法。在雷达信号处理中,接收到的回波信号从时域转换到频域。傅立叶变换将信号分解为一系列正弦和余弦函数的复合形式,使我们能够获得不同频率的信号分量,并获取有关信号的频谱信息。通过分析信号的频谱分布,可以提取出更好的目标距离和速度信息。因此,信号从时域到频域的转换是雷达信号处理中至关重要的一步,使我们能够更好地了解信号特性并识别目标。快速傅立叶变换的公式如下:

二、多普勒处理,在雷达信号处理中,经过距离压缩后,后续步骤包括获取目标的速度信息。当目标运动时,其回波信号会发生多普勒频移。因此,多普勒处理的目的是分析这种频移并估计目标的速度。多普勒处理通常使用称为快速时频分析(FTFA)的基于FFT的方法来实现。在FTFA方法中,首先使用快速傅立叶变换将距离压缩信号从时域变换到频域。随后,将多普勒变换应用于每个距离仓的频域信号,从而能够提取目标的速度信息。多普勒处理的目的是校正频率轴上的回波信号,有效地补偿目标运动引起的多普勒频移。这种校正是通过将信号乘以基于目标速度计算的相位因子来实现的。通过采用这种方法,可以恢复原始回波信号,便于后续的目标识别和跟踪任务。
三、MTI处理,在雷达探测中,杂波目标的回波信号往往比目标回波信号表现出更强的幅度,从而对目标探测产生干扰。为了减轻这种干扰并提高雷达在目标检测中的灵敏度,采用了运动目标指示(MTI)信号处理技术。MTI技术利用差分运算来比较来自多个时间实例的回波数据。通过减去在不同时间间隔接收到的回波信号,MTI技术有效地抑制了来自静止物体的信号,并减轻了杂波回波信号的影响。结果,提高了雷达系统在探测目标时的灵敏度。数学上,MTI处理可以由以下等式表示:
![]()
其中,S(k,l,m)表示第k个距离单位、第l个时间单位和第m个脉冲回波信号的幅度;S4(k,l,m)表示在执行四阶MTI处理之后获得的幅度。
神经网络
为了有效地识别运动手势,本研究提出了一种基于CNN-TCN的时空建模方法,用于时空数据的建模和分类。该模型将输入的RFDM分为两部分:空间特征和时间特征。具体而言,该模型由两个部分组成:1。帧模型:CNN组件从RFDM的每个帧中提取空间特征。序列模型:TCN组件从RFDM的时间序列数据中提取时间特征。帧模型和序列模型的输出通过完全连接的层,然后合并以进行最终分类。这种集成允许CNN-TCN模型同时考虑空间和时间特征,从而提高了分类精度。该模型的网络架构如图3所示。

特别地,该框架模型由三个卷积层、一个批量归一化层和两个改进的线性单元层(LeakyReLU)组成。这些组件被设计为从连续的RFDM帧中提取空间特征。卷积层使用不同大小的核来捕获不同尺度的特征。随后,使用最大池化层对特征图进行下采样,减少了训练时间,提高了模型的泛化能力。最后,使用一维细胞神经网络将信道数量减少到原始信道的1/12,显著降低了模型的复杂性。对于连续帧,使用TCN(时间卷积网络)框架从RFDM序列中提取时间特征。拟议的TCN不同于传统结构,因为它采用了具有柔性残余连接的流线型设计,如图4左侧所示。每个TCN由三个时间块组成,如图4右侧所示。这些块包括扩张卷积、因果卷积、LeakyReLU激活和Dropout。扩展卷积填充输入数据,将卷积核与边界像素对齐,而因果卷积仅使用过去的数据,以确保输出仅取决于当前和过去的输入。该架构有效地捕获了序列中的长期依赖关系,并允许轻松调整网络的深度和宽度,以适应不同的数据集和任务。LeakyReLU激活缓解了与传统ReLU相关的“神经元死亡”问题,提高了模型的泛化能力和稳定性。Dropout减少了神经元之间过度的相互依赖,增强了模型的泛化能力,降低了过度拟合的风险。总之,这种TCN结构有效地从RFDM序列中提取时间特征,同时保持较低的网络复杂度和训练负担。

数据
手势识别在智能大屏控制中发挥着至关重要的作用,实现了无接触、自然、直观的交互。然而,手势识别在各种环境和位置中遇到了许多挑战,包括照明变化、背景干扰和多路径反射。为了应对这些挑战,我们提出了一种基于深度学习的手势识别网络,该网络利用多维特征来提高识别的准确性和稳健性。为了展示我们提出的网络的性能和优势,我们精心设计和策划了一个手势数据集,该数据集包括在三个不同的环境和五个位置中执行的七个不同手势,如所示

结果
在这项研究中,我们采用Leave One Out Cross Validation(LOOCV)方法来评估我们的神经网络在手势识别任务中的性能。我们通过选择一个人的样本作为测试集,同时使用剩余的样本作为训练集,将数据集划分为训练集和测试集。在相同的环境和位置对每个人重复这个过程,使我们能够全面训练和测试模型。LOOCV的结果被编译成一个混淆矩阵,如图6所示。平均识别率高达98.4%,令人印象深刻。这些发现证明了我们的神经网络在识别所有研究手势方面的高精度。这一成功可以归因于训练数据和测试数据之间的特征相似性。总之,这些结果证实了我们提出的神经网络模型在提取相关运动特征以进行鲁棒手势识别方面的有效性。

不同神经网络性能比较
为了进一步验证所提出的网络的有效性,我们将其与其他四种常用于动作识别的深度学习网络进行了比较:CNN、3D-CNN、CNNLSTM和CNN-GRU。我们在收集的手势数据集上评估了它们的性能,结果总结在表3中。
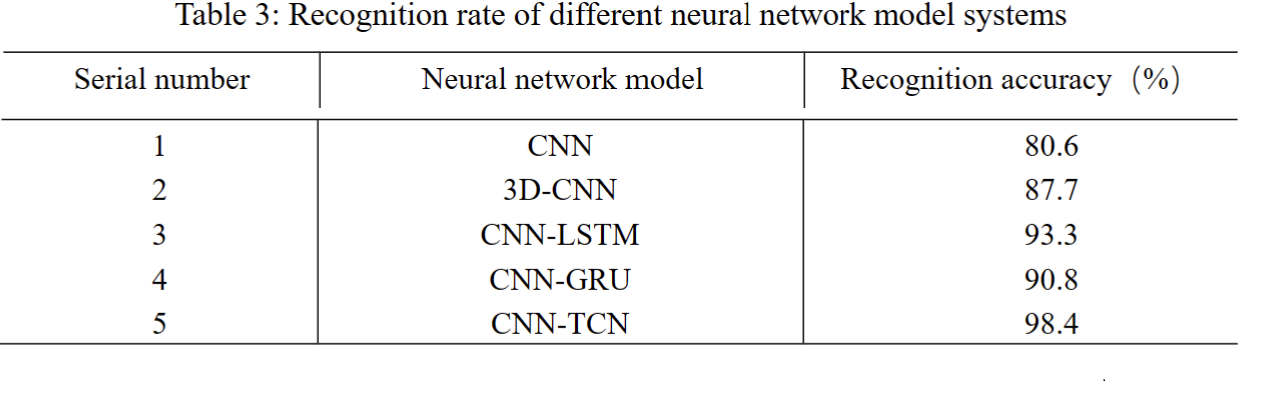
CNN-TCN网络在每个动作类别的识别率方面都优于其他网络,证明了其提取空间和时间特征的卓越能力。虽然CNN只能捕捉空间特征,但3D-CNN在处理时间维度方面存在较大的参数数量和有限的灵活性。CNN-LSTM和CNN-GRU网络虽然结合了用于时间特征提取的递归层,但具有更高的计算复杂性和有限的长期依赖性建模能力。相反,CNN-TCN网络采用了多尺度时空卷积层和融合层,使其能够自适应地提取不同尺度和阶段的特征。它还动态融合了来自多个分支的信息,从而在不同的动作识别任务中获得卓越的性能。















 616
616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









