







具体的软硬件实现点击 MCU-AI技术网页_MCU-AI人工智能
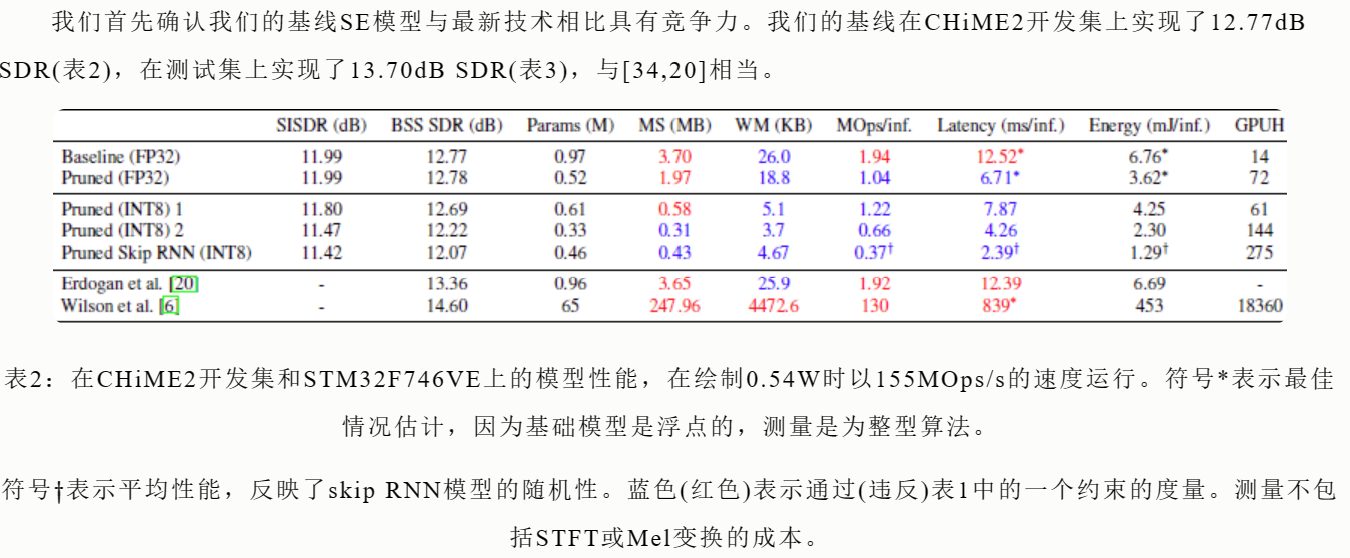
现代语音增强算法利用大量递归神经网络(RNNs)实现了显著的噪声抑制。然而,大型RNN限制了助听器硬件(hearing aid hardware,HW)的实际部署,这些硬件是电池供电的,运行在资源受限的微控制器单元(microcontroller units,MCU)上,内存和计算能力有限。在这项工作中,我们使用模型压缩技术来弥补这一差距。我们在HW上对RNN施加约束,并描述了一种方法来满足它们。虽然模型压缩技术是一个活跃的研究领域,但我们是第一个证明其有效性的RNN语音增强,使用剪裁和权重/激活的整型量化。我们还演示了状态更新跳跃,它可以减少计算负载。最后,我们对压缩模型进行感知评估,人类评分员对语音进行打分。结果显示,与基线相比,压缩模型的模型size和operation(操作)分别减少了11.9和2.9,在听力偏好上没有统计差异,只损失了0.55dB SDR。我们的模型实现了2.39ms的计算延迟,在10 ms的目标范围内,比之前的工作好351倍。
健康的耳朵是一个复杂的非线性系统,能够在大的动态范围内工作。当耳朵受损时,听觉系统可以用助听器(HA)增强,它可以执行一些耳朵不再能做的放大和过滤功能。语音增强(SE)可以缓解嘈杂环境中的听力困难,这是HA用户最关注的问题之一。最近的SE方法通常由循环神经网络(RNN)体现。SE模型必须实现低音频延迟,以确保测听者舒适。音频延迟被定义为噪声到达HA和助听器产生的纯净语音之间的延迟。可以容忍的延迟量取决于HA类型和如何处理用户自己的语音。使用之前的工作作为指导方针,我们的目标是最大音频延迟为30 ms。对于我们使用的基于帧的方法,由于帧和因果模型之间有50%的重叠,处理每帧的计算延迟约束为10ms。
HA形式因素强加了另一组约束,特别是在结合帧处理需求时。由于其体积小,采用了单片机(MCU)硬件平台。MCU实现了廉价、低功耗的计算,但代价是严重的内存和计算约束[10]。MCU Flash内存限制了最大允许模型尺寸(maximum allowed model size,MS),而SRAM内存限制了模型工作内存(upper bounds model working memory,WM),即用于存储中间结果的内存。为了实现高效的计算,SE模型必须量化为整型数据类型,我们必须最小化每秒所需的操作(ops)数量(ops/s),其中op表示单个加法或乘法。本文以STM32F746VE MCU[4]作为典型的HW平台,该MCU包含一个216MHz Arm Cortex-M7 [11],512KB Flash内存,320KB SRAM。我们使用Mbed OS[12]和CMSIS内核[13,14]。表1总结了SE模型约束。

在本工作中,我们提出了一种方法来生成满足表1要求的优化RNN SE模型。首先,我们演示了对SE LSTM进行剪枝,以减少MS、WM和ops,而不会导致SE性能下降。通过扩展[15],我们直接学习优化范围内的剪裁阈值,避免了超参数搜索的开销,与之前的工作[6]相比,减少了255个GPU小时(GPUH)。其次,我们首次证明了标准加权和激活量化技术可以很好地应用于SE RNNs。此外,我们还证明了剪枝和量化可以联合应用于SE RNNs,这也是我们工作的独特之处。最后,我们提出了一个跳过RNN状态更新的方案,以减少平均操作次数。


在我们的模型中执行的所有操作都是矩阵向量乘法,每个参数需要2个操作(乘和加)。尽管操作计数与模型量化无关,但在实际硬件上实现的吞吐量在精度较低的整型数据类型下要高得多。因此,为了减少总体延迟,我们采用了两种优化方法:1)剪枝以减少操作,2)权值/激活量化(weight/activation quantification),从而减少MS,并支持使用低精度整型算法[25]进行部署。



在所有的实验中,我们使用Tensorflow中的随机梯度下降(Stochastic Gradient Descent,SGD)来优化目标。我们使用32ms帧,16ms帧移和16kHz采样率进行基线、剪枝和量化实验。对于skip RNN实验,我们使用的帧长和帧移分别为25ms和6.25ms。所有方法都使用CHiME2 WSJ0数据集[31]进行训练和评估,该数据集分别包含7138个训练词、2560个开发词和1980个测试词。这三个子集都包括信噪比(SNRs)在-6到9dB范围内的话语。噪音数据由记录在客厅环境中的高度不稳定的干扰源组成,包括真空吸尘器、电视和儿童。虽然数据集是在双耳立体声中提供的,但我们通过对通道维数求和来进行预处理,以获得单耳输入和目标,而[6]使用完整的双耳输入来预测双耳掩模。对于最终的客观评估,我们使用信号失真比(SDR)[32]。然而,在训练过程中,我们使用更简单的比例不变信号失真比(SI-SDR),因为它的计算成本更低,并且与SDR[33]很好地相关。

















 146
146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









