






加班把数据库重构完毕
本文的数据库重构是基于 clickhouse 时序非关系型的数据库。该数据库适合存储股票数据,速度快,一般查询都是 ms 级别,不需要异步查询更新界面 ui。
达到目标效果:数据表随便删除,重新拉数据以及指标计算,十多年的数据,整一个过程 5-6 分钟即可,速度远超通达信。因为每个季度数据回除权,所以旧的数据是有问题的,现在再也不怕删数据重新拉取重新计算了。
为啥要重构?
-
以前日行情数据和指标数值是分开两个表的,后面继续研究 clickhouse 数据库,发现根本不需要多表存储,因为 clickhouse 是列存储方式,所以宽表并不会影响查询速度。
-
以前数据经常出现不完整情况,指标数据计算会发生日级别的断层。
-
以前数据重复插入的时候,查出来经常需要去重,增加了消耗。
-
以前很害怕数据重新拉取和计算,因为经常出现数据不完整问题,都不敢删重新来过,不然又要停机查问题了,现在随便删随便重新计算,彻底解决了这个问题。
关键设计
把所有的股票的日行情数据和指标数据存储在一个表
理由:
-
可以多个股票同时查询。 -
可以多个股票同一个时间段同时查询。 -
可以选择性查询某部分字段,不需要跨表,从而提高效率。 -
可以完成数据的完整性和自动去重。
疑问:
-
有的同学疑惑,所有日行情数据和指标数据放一个表会不会增加查询速度。
答案:不会,这是因为 clickhouse 为快速处理这大数据问题效率慢设计好了。 -
如何设置排序值?
答案:因为我们把所有股票数据以及指标放在了同一个表中,所以需要把 date 和 code 两个字段作为键值。
如何避免重复插入,查询数据是使用最新的数据?
-
clickhouse 数据库并不擅长单列更新的,所以我们要更新某列的时候,原则是:先把要更新的行查出来,然后计算指标数据,填充完后,直接插回去即可,所以每一行需要添加一个 version 版本号,数据库会自动去重保存最新的版本号数据,旧数据数据库会自动删除。
-
由于采取的策略是查询数据出来,计算指标填充完重新插回去,所以我们使用的引擎策略是,ReplacingMergeTree,这个的意思是 clickhouse 数据库会自动去重。
-
查询,由于插入新的行的时候,如果有重复行 clickhouse 数据库是在后台不知何时才会自动触发去掉旧数据的,所以查询的使用要加个小技巧,要以版本号进行排序,然后取最新的一条, ORDER BY version DESC,LIMIT 1 BY code,date。具体的见代码。
-
创建表的关键。 引擎: ENGINE=ReplacingMergeTree(version) 以版本号作为去重标准,保留最新版本号的数据
主键: PRIMARY KEY(javaHash(code), date) ,由于所有日行情数据放一个表,所以以 code,date 两个字段确定一行数据。
排序值: ORDER BY(javaHash(code), date),以 code 和 date 作为排序,有了解过 clickhouse 数据库的同学就会知道,这两个字段决定了 clickhouse 的数据存储方式。
福利
如何同学也使用 clickhouse 数据库用来存储股票数据,或者还未建立数据库来存储数据的,建议你使用 clickhouse 用来存储,别用 MySql,场景不一样,MySql 适合业务型的,clickhouse 天生就是为数据分析而产生的。所以在查询速度上,clickhouse 是碾压 MySql 的。
可以直接使用我的代码,是经过不断测试趋于完善的了,没 bug 了。
我的重构代码:
import time
import pandahouse as ph
import pandas as pd
from clickhouse_driver import Client
'''
pandahouse 是通过http url 链接,端口号是8123
'''
connection = dict(database="stock",
host="http://localhost:8123",
user='default',
password='sykent')
'''
clickhouse_driver 是通过TCP链接,端口号是9000
'''
DB = 'stock'
# settings = {'max_threads': 5}
client = Client(database=f'{DB}',
host='127.0.0.1',
port='9000',
user='default',
password='sykent',
# settings=settings
)
sql = 'SET max_partitions_per_insert_block = 200'
client.execute(sql)
"""
表名
"""
STOCK_DAILY_TABLE = 'stock_daily_price_v2'
INDUSTRY_DAILY_TABLE = 'industry_daily_v2'
INDUSTRY_CONSTITUENT_STOCK_TABLE = 'industry_constituent_stock_v2'
MARKET_DAILY_TABLE = 'market_daily_v2'
def stock_daily(
pool_code,
start_time,
end_time,
use_col=None
) -> pd.DataFrame:
"""
查询股票某个时间段日线数据
:param pool_code: 股票代码池 list() ['000001', '000002'] 或者 '000001'
:param start_time: 开始时间
:param end_time: 结束时间
:param use_col: 使用的列 list() ['open', 'close'],不传则使用全部列
"""
return __query_daily_related(
STOCK_DAILY_TABLE,
pool_code,
start_time,
end_time,
use_col
)
def stock_daily_http(
pool_code,
start_time,
end_time,
use_col=None
) -> pd.DataFrame:
"""
查询股票某个时间段日线数据
:param pool_code: 股票代码池 list() ['000001', '000002'] 或者 '000001'
:param start_time: 开始时间
:param end_time: 结束时间
:param use_col: 使用的列 list() ['open', 'close'],不传则使用全部列
"""
return __query_daily_related_http(
STOCK_DAILY_TABLE,
pool_code,
start_time,
end_time,
use_col
)
def stock_daily_on_date(
pool_code,
date_time,
use_col=None
) -> pd.DataFrame:
"""
查询股票某日日线数据
:param pool_code: 股票代码池 list() ['000001', '000002'] 或者 '000001'
:param date_time: 日期
:param use_col: 使用的列 list() ['open', 'close'],不传则使用全部列
"""
return stock_daily(
pool_code,
date_time,
date_time,
use_col
)
def industry_daily(
pool_code,
start_time,
end_time,
use_col=None
) -> pd.DataFrame:
"""
查询行业某个时间段日线数据
:param 参照stock_daily
"""
return __query_daily_related(
INDUSTRY_DAILY_TABLE,
pool_code,
start_time,
end_time,
use_col
)
def industry_daily_on_date(
pool_code,
date_time,
use_col=None
) -> pd.DataFrame:
"""
查询行业某日日线数据
:param 参照stock_daily_on_date
"""
return industry_daily(
pool_code,
date_time,
date_time,
use_col
)
def all_industry_daily_on_date(
date_time,
use_col=None
) -> pd.DataFrame:
"""
查询所有板块的某个日期的rps
:param date_time:
:param use_col:
:return:
"""
if use_col is None:
sql = f"""
SELECT *
FROM {DB}.{INDUSTRY_DAILY_TABLE}
WHERE date == '{date_time}'
ORDER BY version DESC
LIMIT 1 BY code,date
"""
else:
columns = 'date,code,' + ','.join(use_col) + ',version'
sql = f"""
SELECT {columns}
FROM {DB}.{INDUSTRY_DAILY_TABLE}
WHERE date == '{date_time}'
ORDER BY version DESC
LIMIT 1 BY code,date
"""
df = from_table(sql)
if df.empty:
return df
else:
df.drop(columns='date', inplace=True)
return df
def market_daily(
pool_code,
start_time,
end_time,
use_col=None
) -> pd.DataFrame:
"""
查询大盘指数某个时间段日线数据
:param 参照stock_daily
"""
return __query_daily_related(
MARKET_DAILY_TABLE,
pool_code,
start_time,
end_time,
use_col
)
def market_daily_on_date(
pool_code,
date_time,
use_col=None
) -> pd.DataFrame:
"""
查询大盘指数某日日线数据
:param 参照stock_daily_on_date
"""
return market_daily(
pool_code,
date_time,
date_time,
use_col
)
def board_constituent_stock(
code
) -> pd.DataFrame:
"""
板块成分股
:param code: 板块代码
:return:
"""
sql = f"""
SELECT *
FROM {DB}.{INDUSTRY_CONSTITUENT_STOCK_TABLE}
WHERE industry_code == '{code}'
"""
return from_table(sql)
# @timing_decorator
def to_table(data, table):
if data.empty:
return 0
# 获取columns 如果不包含 'date',重置index
if 'date' not in data.columns:
data.reset_index(inplace=True)
data.insert(data.shape[1], 'version', int(time.time()))
columns = ', '.join(data.columns)
sql = f'INSERT INTO {table} ({columns}) VALUES'
client.execute(sql, data.values.tolist())
return data.shape[0]
# @timing_decorator
def to_table_common(data, table):
columns = ', '.join(data.columns)
sql = f'INSERT INTO {table} ({columns}) VALUES'
client.execute(sql, data.values.tolist())
return data.shape[0]
# @timing_decorator
def from_table(sql) -> pd.DataFrame:
last_time = time.time()
try:
result = client.query_dataframe(sql)
except Exception as e:
print(e)
result = pd.DataFrame()
print("db-> 耗时: {} sql: {}".format((time.time() - last_time) * 1000, sql))
return result
def from_table_http(sql):
"""
查询表
:param sql:
:return: dataframe
"""
last_time = time.time()
df = ph.read_clickhouse(sql, connection=connection)
print("db-> 耗时: {} sql: {}".format((time.time() - last_time) * 1000, sql))
return df
def __creat_daily_related_table(table_name, **kwargs):
"""
创建日行情相关的表
注意:一定需要date,code这两列,作为排序值
:param table_name: 表名
:param kwargs: 列名
:return:
"""
columns_str = ''
for key, value in kwargs.items():
columns_str = columns_str + f'{key} {value},'
columns_str = columns_str[:len(columns_str) - 1]
# 自动添加列名 version 用于插入更新数据
columns_str = columns_str + ',version Int64'
if 'code' not in columns_str or 'date' not in columns_str:
raise Exception('not column code date!!')
sql = f"""
CREATE TABLE if NOT EXISTS {table_name}({columns_str})
ENGINE=ReplacingMergeTree(version)
PRIMARY KEY(javaHash(code), date)
ORDER BY(javaHash(code), date)
"""
print('创建表sql:', sql)
client.execute(sql)
def __creat_common_table(table_name, order_by=None, **kwargs):
"""
创建通用的表,默认使用 ReplacingMergeTree,并自动添加列 version 用于插入更新数据,
而且去重的时候,只会保留version最大的数据
:param table_name: 表名
:param order_by: 排序字段
:param kwargs: 列名
"""
columns_str = ''
for key, value in kwargs.items():
columns_str = columns_str + f'{key} {value},'
columns_str = columns_str[:len(columns_str) - 1]
# 自动添加列名 version 用于插入更新数据
columns_str = columns_str + ',version Int64'
sql = f"""
CREATE TABLE if NOT EXISTS {table_name}({columns_str})
ENGINE=ReplacingMergeTree(version)
"""
if order_by is not None:
sql = sql + f' ORDER BY{order_by}'
print('创建表sql:', sql)
client.execute(sql)
def __drop_table(table_name):
"""
删除表
:param table_name:
:return:
"""
sql = f'DROP TABLE IF EXISTS {table_name}'
client.execute(sql)
print('删除表sql:', sql)
def __query_daily_related(
table,
pool_code,
start_time,
end_time,
use_col=None
) -> pd.DataFrame:
"""
查询股票相关的表
eg:query_daily_related(['000001', '000002'], '2021-01-01', '2022-09-30')
:param pool_code: 股票池 数据类型 list eg:'[000001', '000002']
:param start_time: 开始时间
:param end_time: 结束时间
:param use_col: list 需要返回的列,默认返回 'date,code' 并设置 date 为 index
:return:
如果 start_time == end_time 则认为是查询某一天的数据
version 为最新的数据,以此来去重
"""
# 如果传入的是单个code,转换成list
if type(pool_code) is not list:
code = pool_code
pool_code = list()
pool_code.append(code)
# 时间不相等,查询时间段的数据
if start_time != end_time:
if use_col is None:
sql = f"""
SELECT *
FROM {DB}.{table}
WHERE date BETWEEN '{start_time}' AND '{end_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
else:
columns = 'date,code,' + ','.join(use_col) + ',version'
sql = f"""
SELECT {columns}
FROM {DB}.{table}
WHERE date BETWEEN '{start_time}' AND '{end_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
df = from_table_http(sql)
if df.empty:
return df
# 设置date为index,并排序
df.set_index('date', inplace=True)
df.sort_index(inplace=True)
# 时间相等,查询某一天的数据
else:
if use_col is None:
sql = f"""
SELECT *
FROM {DB}.{table}
WHERE date == '{start_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
else:
columns = 'date,code,' + ','.join(use_col) + ',version'
sql = f"""
SELECT {columns}
FROM {DB}.{table}
WHERE date == '{start_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
df = from_table_http(sql)
if df.empty:
return df
df.drop(columns=['date'], inplace=True)
# version 为更新插入使用,删除version列
df.drop(columns=['version'], inplace=True)
return df
def __query_daily_related_http(
table,
pool_code,
start_time,
end_time,
use_col=None
) -> pd.DataFrame:
"""
查询股票相关的表
eg:query_daily_related(['000001', '000002'], '2021-01-01', '2022-09-30')
:param pool_code: 股票池 数据类型 list eg:'[000001', '000002']
:param start_time: 开始时间
:param end_time: 结束时间
:param use_col: list 需要返回的列,默认返回 'date,code' 并设置 date 为 index
:return:
如果 start_time == end_time 则认为是查询某一天的数据
version 为最新的数据,以此来去重
"""
# 如果传入的是单个code,转换成list
if type(pool_code) is not list:
code = pool_code
pool_code = list()
pool_code.append(code)
# 时间不相等,查询时间段的数据
if start_time != end_time:
if use_col is None:
sql = f"""
SELECT *
FROM {DB}.{table}
WHERE date BETWEEN '{start_time}' AND '{end_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
else:
columns = 'date,code,' + ','.join(use_col) + ',version'
sql = f"""
SELECT {columns}
FROM {DB}.{table}
WHERE date BETWEEN '{start_time}' AND '{end_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
df = from_table_http(sql)
if df.empty:
return df
df.set_index('date', inplace=True)
df.sort_index(inplace=True)
# 时间相等,查询某一天的数据
else:
if use_col is None:
sql = f"""
SELECT *
FROM {DB}.{table}
WHERE date == '{start_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
else:
columns = 'date,code,' + ','.join(use_col) + ',version'
sql = f"""
SELECT {columns}
FROM {DB}.{table}
WHERE date == '{start_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
df = from_table_http(sql)
if df.empty:
return df
df.drop(columns=['date'], inplace=True)
# version 为更新插入使用,删除version列
df.drop(columns=['version'], inplace=True)
return df
def stock_length(code):
"""
查询股票上市最小日期
:param code:
:return:
"""
sql = f"""
SELECT count()
FROM {DB}.{STOCK_DAILY_TABLE}
WHERE code == \'{code}\'
"""
count = client.execute(sql)[0][0]
print('stock_length sql:', sql, f'result count {count}')
return count
def create_market_daily_table():
"""
大盘数据表
:return:
"""
columns = {
'date': 'Date',
'code': 'String',
'name': 'String',
'open': 'Float32',
'high': 'Float32',
'low': 'Float32',
'close': 'Float32',
'volume': 'Float64',
'amount': 'Float64',
'change': 'Float32',
'change_amount': 'Float32',
'amplitude': 'Float32',
'turnover': 'Float32'}
__creat_daily_related_table(MARKET_DAILY_TABLE, **columns)
def create_stock_daily_table():
"""
创建日行情数据表
:return:
"""
columns = {
'date': 'Date',
'code': 'String',
'name': 'String',
'open': 'Float32',
'high': 'Float32',
'low': 'Float32',
'close': 'Float32',
'change': 'Float32',
'change_amount': 'Float32',
'volume': 'Float64',
'amount': 'Float64',
'amplitude': 'Float32',
'turnover': 'Float32',
'amp05': 'Float32',
'amp10': 'Float32',
'amp20': 'Float32',
'amp50': 'Float32',
'amp120': 'Float32',
'amp250': 'Float32',
'ma05': 'Float32',
'ma10': 'Float32',
'ma20': 'Float32',
'ma50': 'Float32',
'ma120': 'Float32',
'ma250': 'Float32',
'rps05': 'Float32',
'rps10': 'Float32',
'rps20': 'Float32',
'rps50': 'Float32',
'rps120': 'Float32',
'rps250': 'Float32', }
__creat_daily_related_table(STOCK_DAILY_TABLE, **columns)
def create_industry_daily_table():
"""
创建板块日行情
:return:
"""
columns = {
'date': 'Date',
'code': 'String',
'name': 'String',
'open': 'Float32',
'high': 'Float32',
'low': 'Float32',
'close': 'Float32',
'change': 'Float32',
'change_amount': 'Float32',
'volume': 'Float64',
'amount': 'Float64',
'amplitude': 'Float32',
'turnover': 'Float32',
'amp05': 'Float32',
'amp10': 'Float32',
'amp20': 'Float32',
'amp50': 'Float32',
'amp120': 'Float32',
'amp250': 'Float32',
'ma05': 'Float32',
'ma10': 'Float32',
'ma20': 'Float32',
'ma50': 'Float32',
'ma120': 'Float32',
'ma250': 'Float32',
'rps05': 'Float32',
'rps10': 'Float32',
'rps20': 'Float32',
'rps50': 'Float32',
'rps120': 'Float32',
'rps250': 'Float32', }
__creat_daily_related_table(INDUSTRY_DAILY_TABLE, **columns)
def create_industry_constituent_stock_table():
"""
创建板块成分股
:return:
"""
columns = {
'industry_code': 'String',
'stock_code': 'String',
'industry_name': 'String',
'stock_name': 'String'}
__creat_common_table(
table_name=INDUSTRY_CONSTITUENT_STOCK_TABLE,
order_by='(javaHash(industry_code), javaHash(stock_code))',
**columns)
def create_all_table():
# 创建日行情数据表
create_stock_daily_table()
# 创建板块日行情表
create_industry_daily_table()
# 创建板块成分股表
create_industry_constituent_stock_table()
# 创建大盘数据表
create_market_daily_table()
def optimize(table_name):
"""
手动触发数据表去重操作
场景: 在更新表后,由于重复的ReplacingMergeTree是不定时触发的,
所以可以强制调用触发。
:param table_name:
:return:
"""
sql = f'optimize table stock.{table_name}'
client.execute(sql)
def drop_all_table():
__drop_table(STOCK_DAILY_TABLE)
__drop_table(INDUSTRY_DAILY_TABLE)
__drop_table(INDUSTRY_CONSTITUENT_STOCK_TABLE)
__drop_table(MARKET_DAILY_TABLE)
def optimize_all():
optimize(STOCK_DAILY_TABLE)
optimize(INDUSTRY_DAILY_TABLE)
optimize(INDUSTRY_CONSTITUENT_STOCK_TABLE)
optimize(MARKET_DAILY_TABLE)
if __name__ == '__main__':
count = stock_length('000001')
print(count)
效果
-
重构的时候要用新的表,这样在重构的过程中不会影响旧数据的运行,稳定后就可以把新表替换旧表的逻辑了。
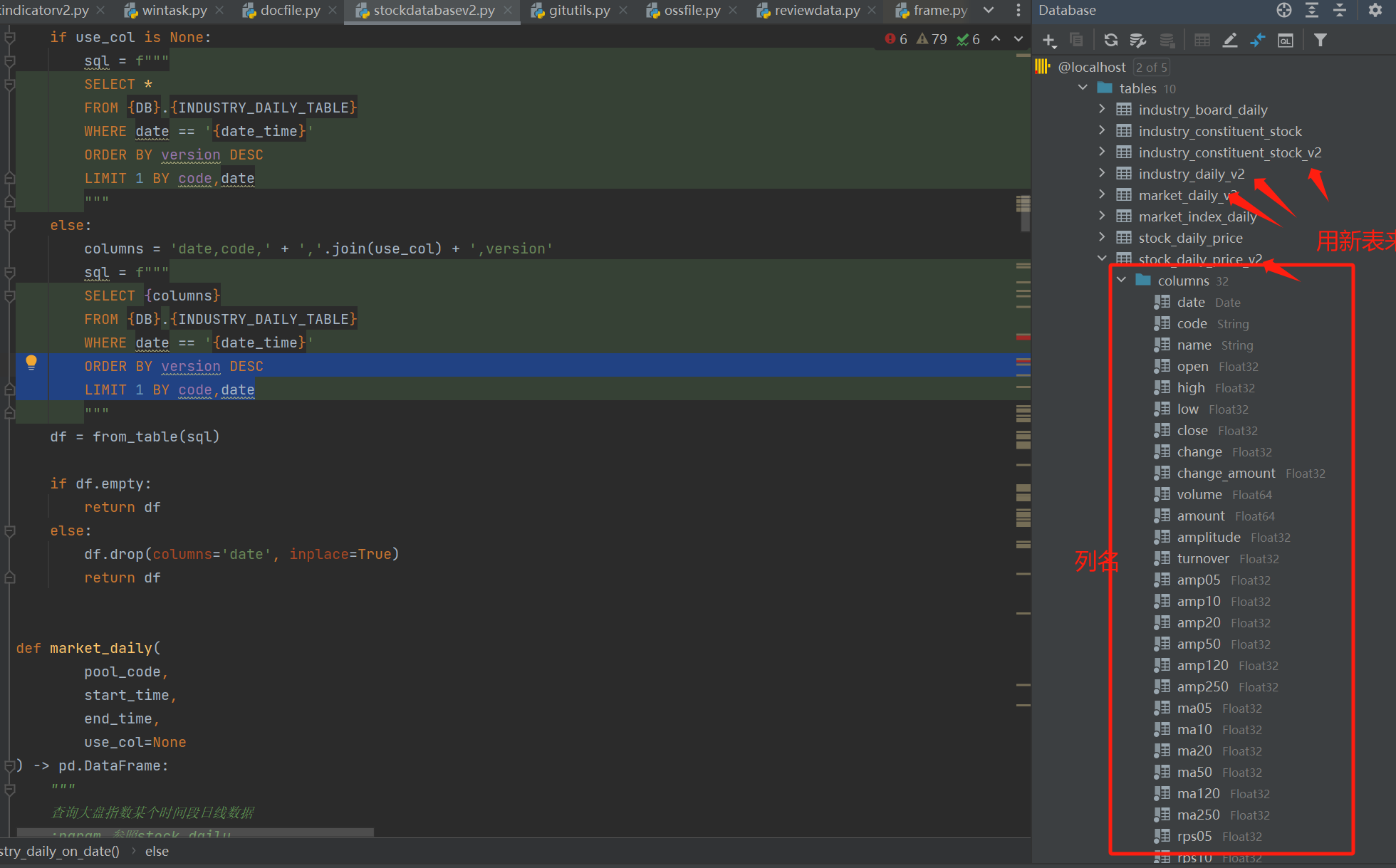
-
新数据替换旧表,接回原来的 ui 使用中,这个过程其实也很简单,替换数据库的查询类即可。
行业板块面板 ui
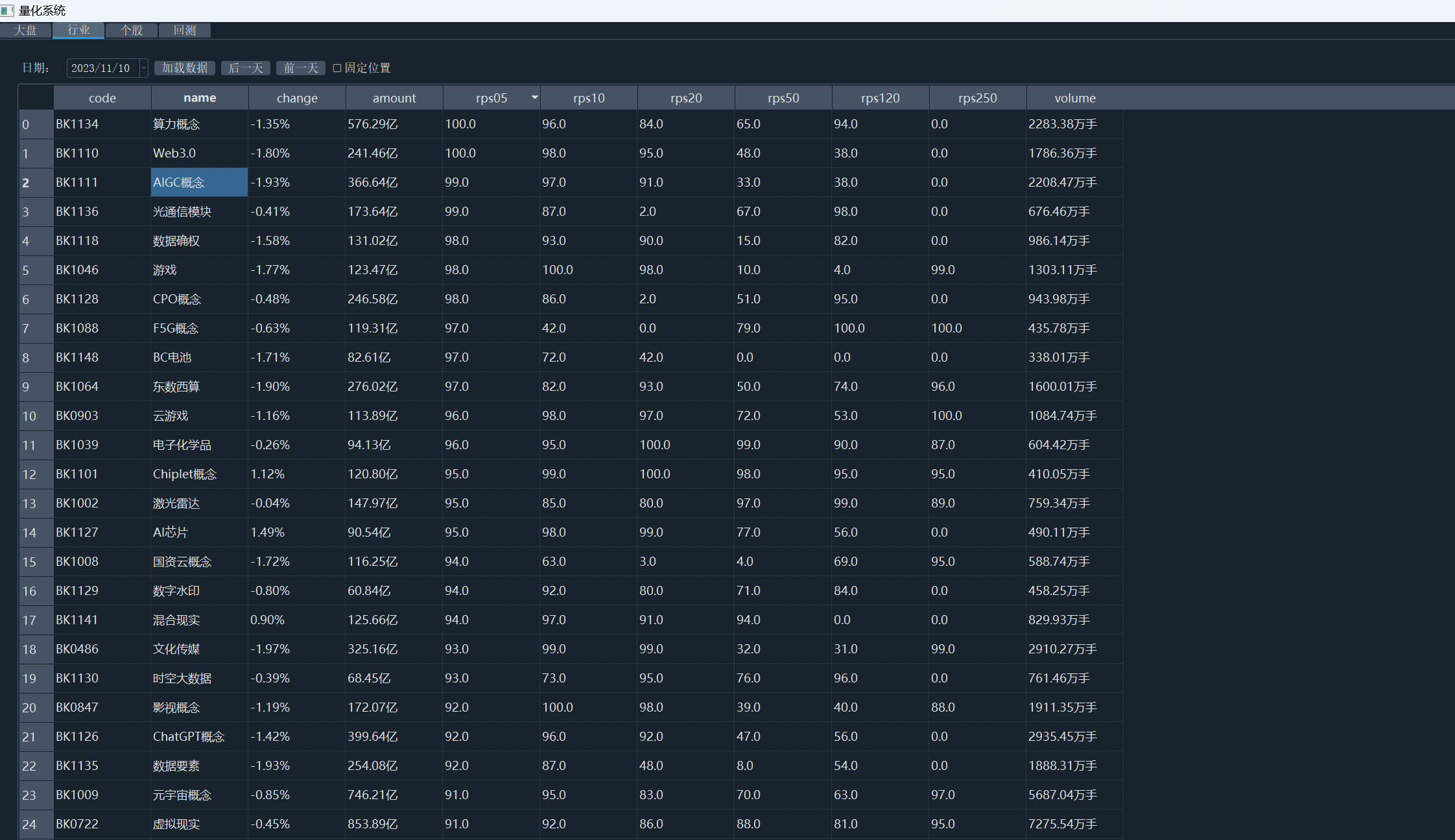
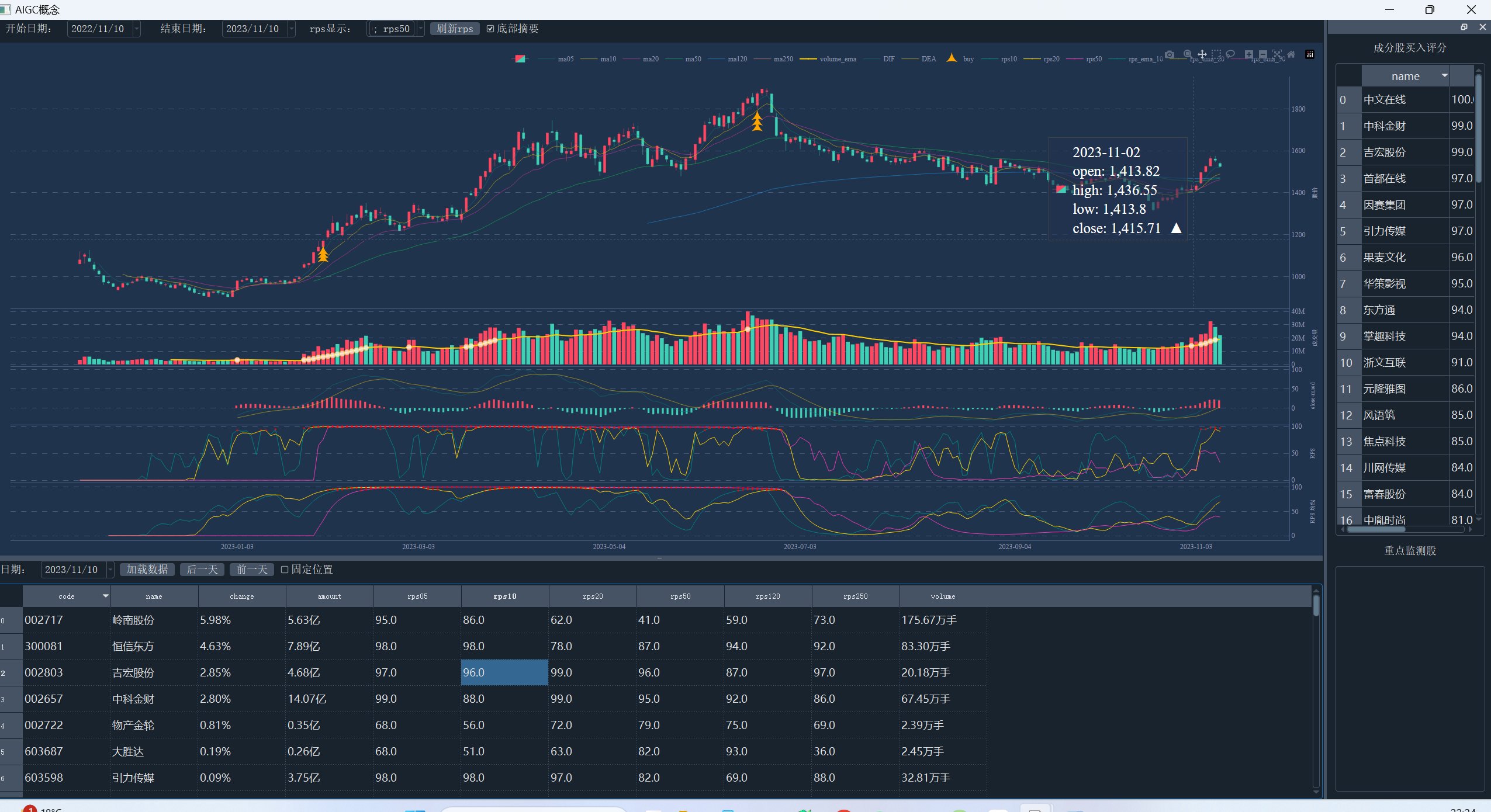
单个板块的可视化,板块成分股 ui
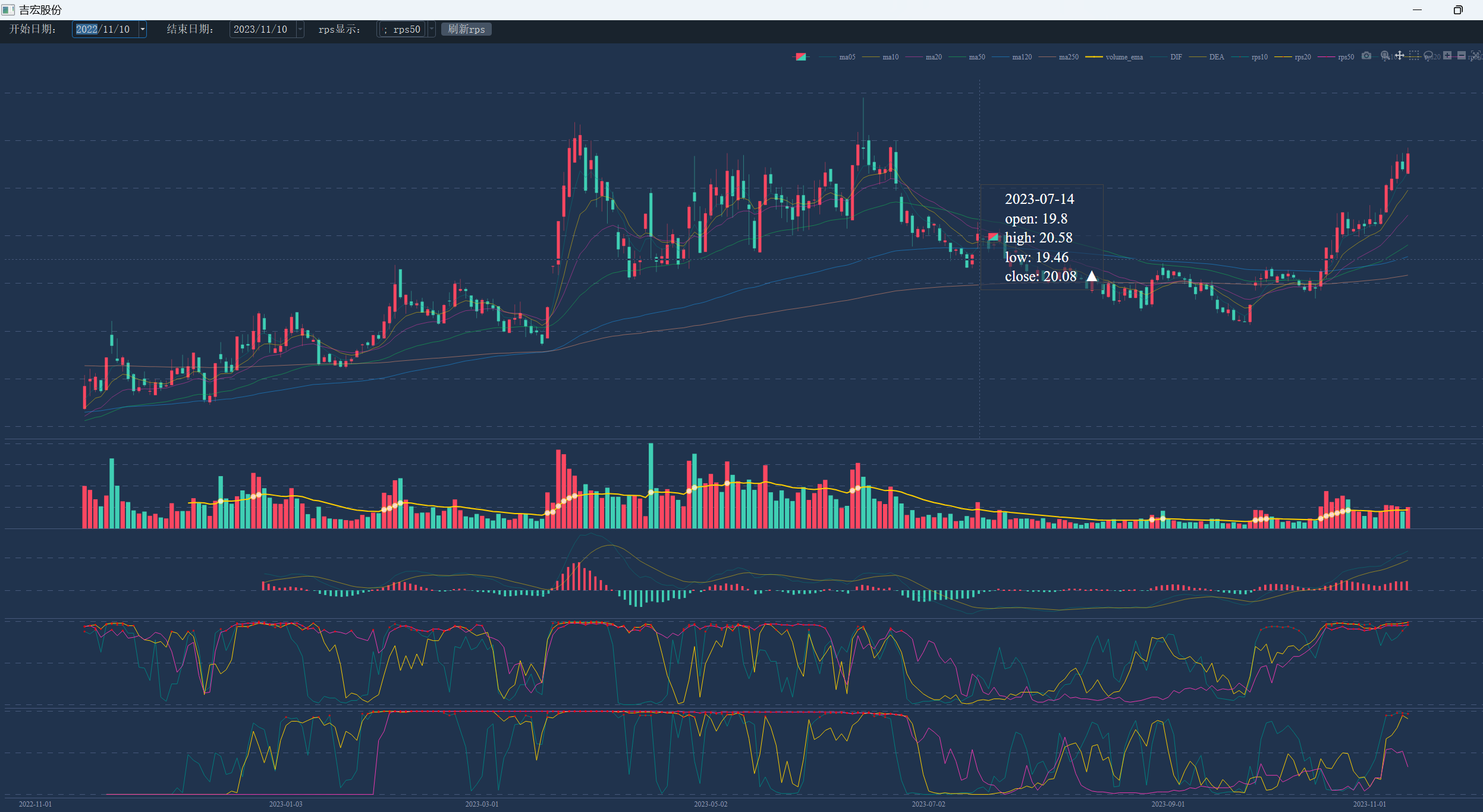
个股的数据 ui
本文由 mdnice 多平台发布















 1262
1262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









