






创新性
文章在MLaaS的场景下表明:先前的工作中专注于服务器会“诚实”地按照用户要求删除其数据,然而缺少用户验证其“诚实性”的具体机制。
本文提出了一个验证系统遗忘的机制:用户中的一小部分隐私爱好者向他们的私有数据样本中添加hidden trigger(后门攻击),然后将他们的(中毒)数据交给 MLaaS 提供商。当模型在后门数据上训练时,后门成功率应该很高。同时,当提供者删除了用户的数据时,后门成功率应该很低。通过这种方式,假设检验可以区分这两种情况。
本篇论文的主要贡献
①提出了一种遗忘学习的验证框架,并通过假设检验量化了衡量指标。
②提出了一种基于后门的机制,用于概率地验证机器学习,并在上述框架中展示其有效性,框图如下:
算法内容
1.前提假设:
①要求用户在提供数据进行模型训练之前可以控制和操作数据,因此可能不适用于用户没有足够能力的某些场景。
②假设隐私爱好者拥有足够的数据来成功下毒。
③MLaaS 提供商无法确定哪个用户正在查询经过训练的机器学习模型。
④本文的方法的范围仅限于验证用户的数据是否从 MLaaS 提供商公开的特定机器学习模型中删除,并且不包括验证从提供商的其他计算或存储资源中删除。
2.算法步骤
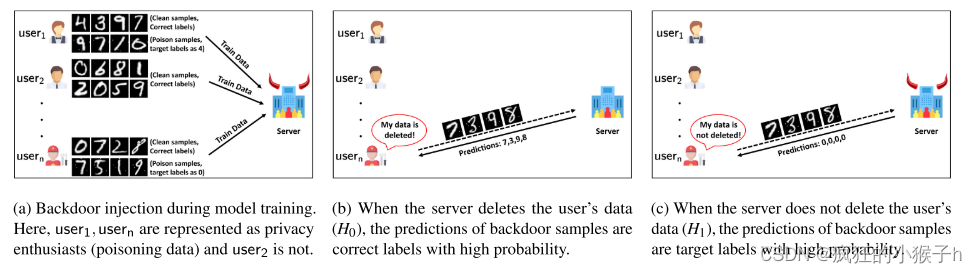
①所有用户中的一小部分隐私爱好者(5%就能正常工作)在本地向他们私有数据中的一小部分 注入了一个hidden trigger,并标注相应的标签,使得MLaaS 提供商在此类数据上训练模型。
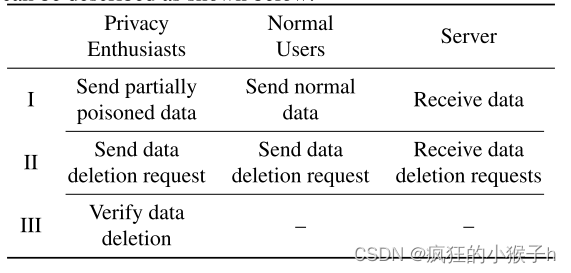
②应用假设检验来确定 MLaaS 提供商是否已从其训练集中删除了请求的用户数据。
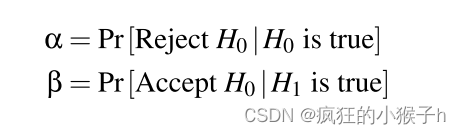
H0 :服务器删除用户数据时的状态, H1 :服务器不删除数据时的状态;
α
\alpha
α:服务器被错误地指控为恶意活动的可接受值,而实际上它是诚实地遵循数据删除的。
β
\beta
β:服务器恶意没有删除用户数据。
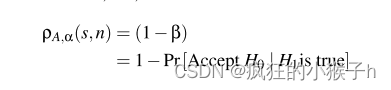
删除置信度 (1-β),即假设检验的功效。为了将这种置信度作为系统参数的函数来衡量,引入了以下变量:

s
a
m
p
l
e
i
sample_{i}
samplei表示后门样本;
r
^
\hat{r}
r^表示后门攻击准确率。
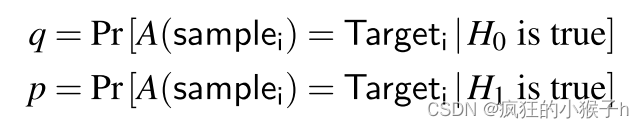
服务器删除数据和未删除数据情况下的后门攻击准确率对应的两个概率分别称为 q(较低)和 p(较高)。
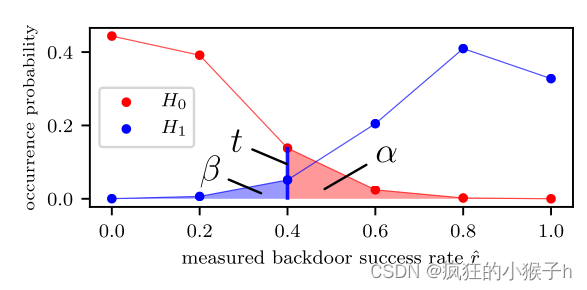
如果原假设 H0(数据已删除)为真,则度量
r
^
\hat{r}
r^接近 q,如果备择假设 H1(数据未删除)为真,则
r
^
\hat{r}
r^接近 p。为了决定我们是在 H0 还是 H1,我们定义了一个阈值 t,如果 r^ ≤ t 我们输出 H0,否则输出 H1。经过证明推导出了验证置信度的解析表达式:
对于给定的 ML 机制 A 和给定的可接受的 I 类错误概率 α,删除置信度 ρA,α(s,n) 由以下表达式给出:
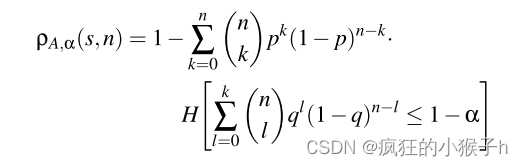
其中,H(·) 是重阶阶跃函数,即,如果 x 为真,则 H(x) = 1,否则为 0。
③在两种不同类型服务器上对验证机制进行评估:第一个是非自适应的:不会删除用户数据但预计不会被检测到,而第二个是自适应的:采用最先进的防御机制来缓解用户查询策略(同时也不会删除用户数据),从而积极地逃避检测。
实验结果
实验数据集和模型架构
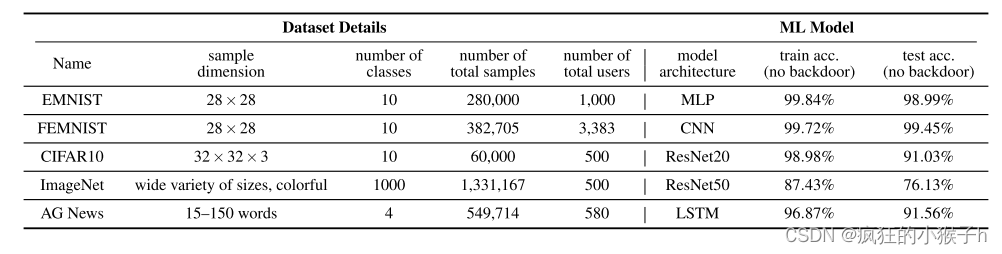
实验结果
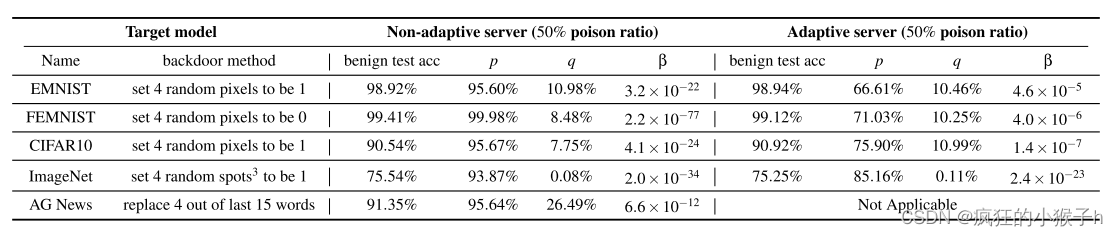
其中,隐私爱好者占用户总数的5%,一类错误
α
\alpha
α设置为10-3.
实验结果以高置信度(1-β)证明了验证机制的有效性。
可能存在的问题
①不适用于隐私爱好者在发送前无法修改其数据的系统,即使允许隐私爱好者修改他们的数据,他们也需要至少几十个样本(实验中用了30个)才能使本文的方法在实践中很好地工作。
②当后门相互冲突时(当后门相似时可能发生这种情况),本文的方法可能对某些用户失败。















 687
687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









