







Zero-Shot Machine Unlearning
引言
本文在引言和Related work中将现有的Unlearning方法进行了分类,比较详细。
创新性
在大多数情况下,公司只是应用训练好的模型,而对原始训练数据的访问权限有时会被限制或者是昂贵的,而以往的以往方法都需要掌握一部分原始训练数据的知识,因此能否开发不需要训练样本或与训练过程相关的信息的机器遗忘学习算法(零样本遗忘学习)?
本文在知道以往数据类别而不知道遗忘数据内容,掌握目标模型结构和参数的条件下对深度学习网络中的某一类或某些类数据实现了近似遗忘。
本篇论文的贡献(目的)
①介绍了零样本机器学习的问题设置,提出了两种新方法来实现无数据学习: (i) error-maximizing and error-minimizing noise (ii) gated knowledge transfer in a teacher-student learning frame-work.
②引入了一个新的指标,即回忆指数,以更有效地评估忘却的质量。
③在基准视觉数据集(MNIST、SVHN、CIFAR-10)上的各种深度学习网络上获得了强大的性能。
零样本遗忘学习算法步骤
这篇文章是在作者的另外一篇"FAST YET EFFECTIVE MACHINE UNLEARNING"文章的基础上进行的工作。因此首先介绍"FAST YET EFFECTIVE MACHINE UNLEARNING"中用到的方法。
1.Error-Maximizing Noise based Unlearning
"FAST YET EFFECTIVE MACHINE UNLEARNING"中旨在通过最大化模型损失来学习要遗忘类数据的噪声矩阵(与模型input相同size)。使用此类噪声矩阵对模型进行更新,从而损坏/覆盖先前学习的要遗忘类数据的网络权重,并导致模型遗忘。其优化目标为:
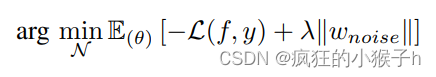
其中,第一项用于最大化模型损失,第二项用于控制噪声不至于过大,导致模型将较大的噪声作为遗忘类别的一部分。具体来说:

①冻结pretrained model的权重,从标准正态分布N(0,1)中随机初始化N,优化上述目标函数得到误差最大噪声矩阵。
②“Impair”:利用一小部分原始数据分布中的数据和噪声矩阵对模型进行参数更新,以此来破坏模型之前学到的关于要遗忘类别数据的信息。
③“Repair”:“Impair”过程可能使模型在剩余数据类别上的预测准确率下降,因此需要在剩余类别数据上进行一个epoch的训练,保持模型对剩余类别数据的预测准确性。
2.Error Minimization-Maximization Noise
本文中在零样本设置下,与1中方法的区别在于,利用生成误差最小化噪声替换剩余类别( C r C_{r} Cr)的信息保留下来。对于每个类别i的误差噪声如下表示:

算法原理图:
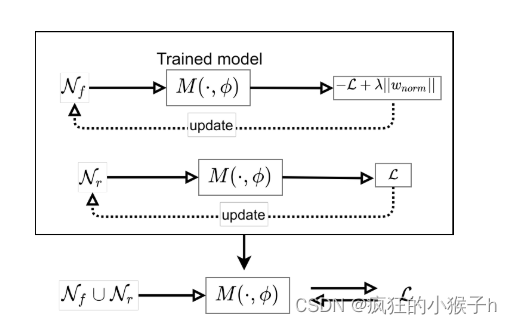
①首先,与1中相同生成误差最大化噪声用于破坏遗忘类(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 666
666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









