







Tensorflow学习笔记:CNN篇(6)——CIFAR-10数据集VGG19实现
前序
— 这是一个基于Tensorflow的VGG19模型在CIFAR-10数据集上的实现,包括图像预处理,VGG19模型搭建和最终训练。
VGG19模型
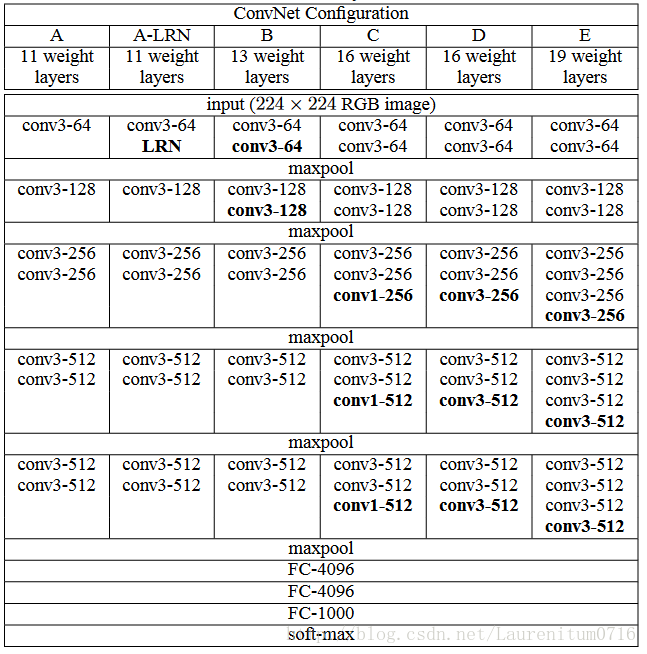
— VGG网络与AlexNet类似,也是一种CNN,VGG在2014年的 ILSVRC localization and classification 两个问题上分别取得了第一名和第二名。VGG网络非常深,通常有16-19层,卷积核大小为 3 x 3,16和19层的区别主要在于后面三个卷积部分卷积层的数量。可以看到VGG的前几层为卷积和maxpool的交替,后面紧跟三个全连接层,激活函数采用Relu,训练采用了dropout。VGG中各模型配置如下, 其中VGG19的top-1的训练精度可达到71.1%,top-5的训练精度可达到89.8%。模型结构示例如下:

代码示例
1、参数设置
# -*- coding:utf-8 -*-
import tensorflow as tf
import numpy as np
import time
import os
import sys
import pickle
import random
class_num = 10
image_size = 32
img_channels = 3
iterations = 200
batch_size = 250
total_epoch = 164
weight_decay = 0.0003
dropout_rate = 0.5
momentum_rate = 0.9
log_save_path = './vgg_logs'
model_save_path = './model/'2、数据准备
这一部分主要为数据准备部分由prepare_data()以及四个子函数download_data()、unpickle()、load_data_one()、load_data()所组成,功能包括下载数据集,读取数据集,将数据分为训练集与测试集两部分并进行Shuffle。
def download_data():
dirname = 'cifar10-dataset'
origin = 'http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz'
fname = './CAFIR-10_data/cifar-10-python.tar.gz'
fpath = './' + dirname
download = False
if os.path.exists(fpath) or os.path.isfile(fname):
download = False
print("DataSet already exist!")
else:
download = True
if download:
print('Downloading data from', origin)
import urllib.request
import tarfile
def reporthook(count, block_size, total_size):
global start_time
if count == 0:
start_time = time.time()
return
duration = time.time() - start_time
progress_size = int(count * block_size)
speed = int(progress_size / (1024 * duration))
percent = min(int(count*block_size*100/total_size),100)
sys.stdout.write("\r...%d%%, %d MB, %d KB/s, %d seconds passed" %
(percent, progress_size / (1024 * 1024), speed, duration))
sys.stdout.flush()
urllib.request.urlretrieve(origin, fname, reporthook)
print('Download finished. Start extract!', origin)
if fname.endswith("tar.gz"):
tar = tarfile.open(fname, "r:gz")
tar.extractall()
tar.close()
elif fname.endswith("tar"):
tar = tarfile.open(fname, "r:")
tar.extractall()
tar.close()
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
def load_data_one(file):
batch = unpickle(file)
data = batch[b'data']
labels = batch[b'labels']
print("Loading %s : %d." % (file, len(data)))
return data, labels
def load_data(files, data_dir, label_count):
global image_size, img_channels
data, labels = load_data_one(data_dir + '/' + files[0])
for f in files[1:]:
data_n, labels_n = load_data_one(data_dir + '/' + f)
data = np.append(data, data_n, axis=0)
labels = np.append(labels, labels_n, axis=0)
labels = np.array([[float(i == label) for i in range(label_count)] for label in labels])
data = data.reshape([-1, img_channels, image_size, image_size])
data = data.transpose([0, 2, 3, 1])
return data, labels
def prepare_data():
print("======Loading data======")
download_data()
data_dir = './cifar10-dataset'
image_dim = image_size * image_size * img_channels
meta = unpickle(data_dir + '/batches.meta')
label_names = meta[b'label_names']
label_count = len(label_names)
train_files = ['data_batch_%d' % d for d in range(1, 6)]
train_data, train_labels = load_data(train_files, data_dir, label_count)
test_data, test_labels = load_data(['test_batch'], data_dir, label_count)
print("Train data:", np.shape(train_data), np.shape(train_labels))
print("Test data :", np.shape(test_data), np.shape(test_labels))
print("======Load finished======")
print("======Shuffling data======")
indices = np.random.permutation(len(train_data))
train_data = train_data[indices]
train_labels = train_labels[indices]
print("======Prepare Finished======")
return train_data, train_labels, test_data, test_labels3、数据预处理(图像增强)
— 任何神经网络在开始训练数据时,都需要数据增强。什么是数据增强呢?我们首先看一个例子,假如我们的训练集有10万图片,如果直接使用这10张图片进行训练,是不是感觉训练集有点小。在假如,训练神经网络的目的是要正确识别猫,而此时呢?你的训练集中含有猫头的图片都是朝着左侧倾斜,那么当你训练好模型之后,你的模型不能准确识别猫头朝着右侧倾斜的图片,因为它没有被训练。而假如你在训练输入时,将训练集合中的所有图片进行水平翻转,就会得到10万新的数据,此时你就有20万张训练集合了。如果在进行随机裁剪、亮度、对比度变化,这又大大增加训练集合的数量,最终训练的集合更加健壮。这就是数据增强的作用:将单幅图片增加多个副本,提高了图片的利用率,并且防止对某一张图片结构的学习过拟合,可以大大增加训练集合,提供模型的健壮性。
— Tensorflow关于图像操作的类别有:编码/解码、缩放、裁剪、翻转和移位、图像调整。
def _random_crop(batch, crop_shape, padding=None):
oshape = np.shape(batch[0])
if padding:
oshape = (oshape[0] + 2*padding, oshape[1] + 2*padding)
new_batch = []
npad = ((padding, padding), (padding, padding), (0, 0))
for i in range(len(batch)):
new_batch.append(batch[i])
if padding:
new_batch[i] = np.lib.pad(batch[i], pad_width=npad,
mode='constant', constant_values=0)
nh = random.randint(0, oshape[0] - crop_shape[0])
nw = random.randint(0, oshape[1] - crop_shape[1])
new_batch[i] = new_batch[i][nh:nh + crop_shape[0],
nw:nw + crop_shape[1]]
return new_batch
def _random_flip_leftright(batch):
for i in range(len(batch)):
if bool(random.getrandbits(1)):
batch[i] = np.fliplr(batch[i])
return batch
def data_preprocessing(x_train,x_test):
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train[:, :, :, 0] = (x_train[:, :, :, 0] - np.mean(x_train[:, :, :, 0])) / np.std(x_tr 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2874
2874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









