







目录
使用MNNConvert命令将.onnx模型转为.mnn模型(linux上进行)
将pytorch训练好的.pth模型转为.onnx模型
import torch
import torch.onnx
import models
# 读取模型
model = models.crnn(inputdim=64, outputdim=1, pretrained_file= "trainedModels/bs1_epoch1_validloss_0.27896.pth")
# 将模型转为验证模式(这步好像不用也行)
model.eval()
# 随便创建一个临时数据,数据的大小要与网络输入一致。内容无所谓,因为后面只需要它的shape
temp_data = torch.randn(1,10,64) # 1是batch_size
# 定义输入输出的名字,随便定,不过之后的操作好像会用到
input_names = ["input"]
output_names = ["output"]
# 转换模型
torch.onnx.export(model, temp_data, "trainedModels/onnx/test.onnx", verbose=True, training = True, input_names=input_names, output_names=output_names)
# blabla
print("ok")
使用MNNConvert命令将.onnx模型转为.mnn模型(linux上进行)
第一种方法
使用编译好的“MNNConvert”命令
./MNNConvert -f ONNX --modelFile test.onnx --MNNModel test.mnn --bizCode MNN
第二种方法
先安装python上的MNN库
python3 -m MNN.tools.mnnconvert
然后使用这个命令
python3 -m MNN.tools.mnnconvert -f ONNX --modelFile test.onnx --MNNModel test.mnn --bizCode MNN
报错解决
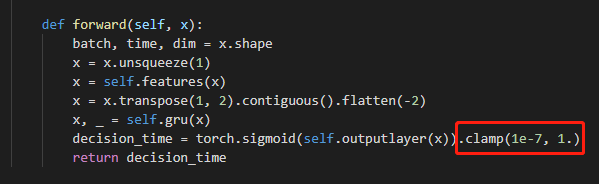
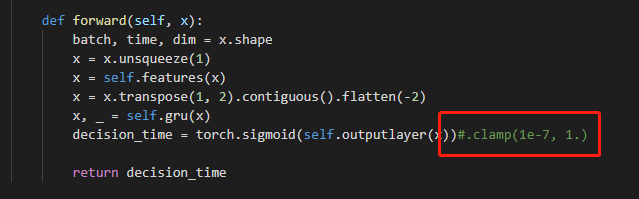
这里容易出现各种各样的错误,比如我原本的模型结构是这样的

转换模型的时候报了这个错误

最开始以为是mnn不支持LeakyReLU或者LPPooling,将二者都换掉以后还是不行,排查了很久最后发现是forward函数中的clamp导致的,果断把这个函数注释掉(对网络影响不大)。
然后重新训练、将模型转为onnx,报错变成了这个
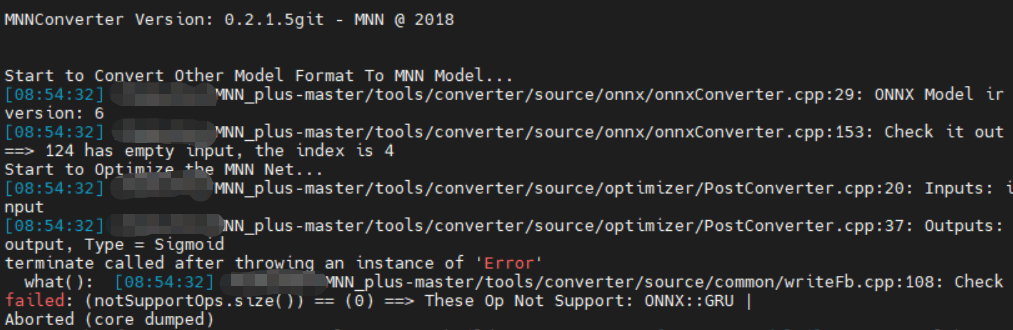
这个报错就很明显了,意思是mnn不支持GRU,无奈只能把GRU换成LSTM。重新训练、将模型转为onnx,就没问题了。
随后我又尝试将LeakyReLU或者LPPooling换回来,发现LeakyReLU可以,但是LPPooling报了这个错
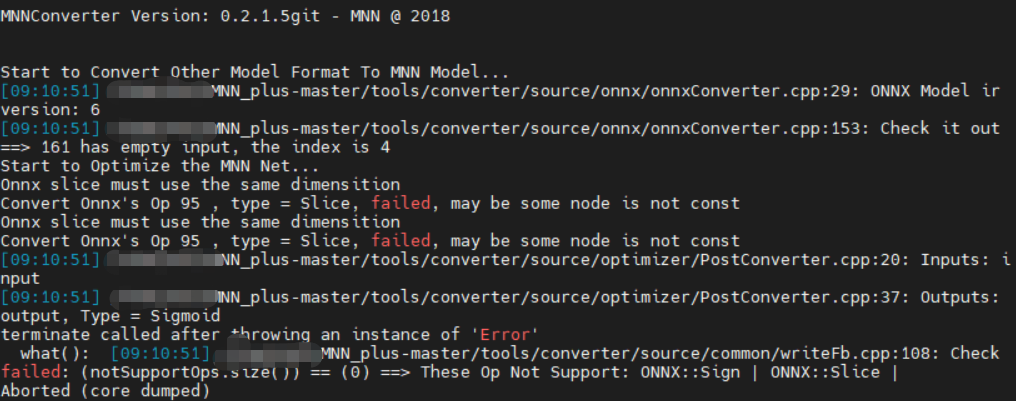
这个错误我没有仔细分析,猜测可能是mnn不支持LeakyReLU的意思。
最后经过若干次改动,模型结构变成了这样
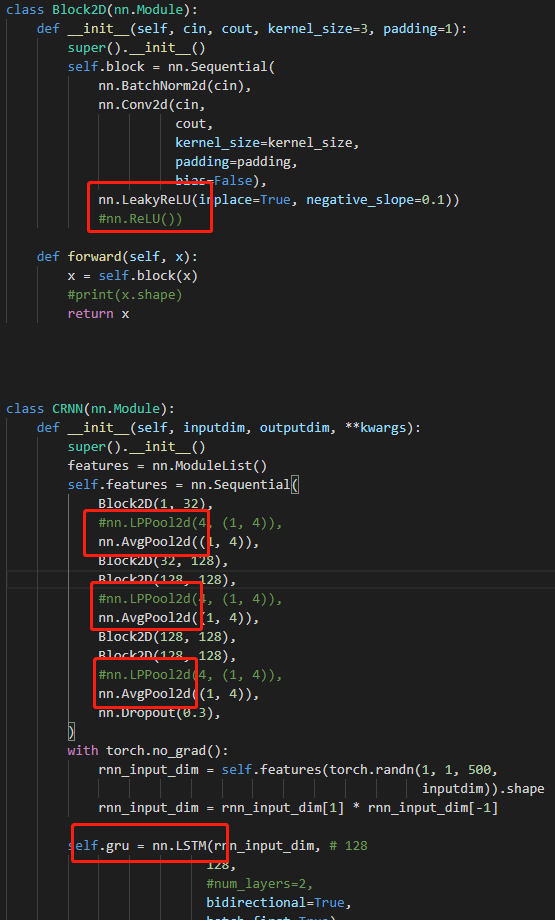
大概过程就是
1、训练模型、将模型转为onnx。
2、有无报错。若有,转到第3步。若无,转到第5步。
3、结合报错和自己的猜测修改网络结构,将导致问题的算子直接替换掉(当然如果c的功底足够强的话也可以去改mnn的源代码)。
4、回到第1步。
5、成功。
训练量化
参考
这两个代码
,实际上过程跟pytorch训练模型差不多。
创建DataLoader
除了父类不同外,创建DataLoader的方法跟pytorch几乎一样,就是注意
__getitem__函数的返回值需要转为c++支持的expr格式
。
class XxxDataset(MNN.data.Dataset):
def __init__(self, xxx):
super(ImagenetDataset, self).__init__()
pass
def __getitem__(self, index):
pass
#最后需要把data和label转换为那个什么expr的格式
#否则后面加载数据的时候会报错“Unable to cast Python instance to C++ type”
data = F.const(data, data.shape, F.data_format.NCHW)
label = F.const(label, label.shape, F.data_format.NCHW)
return data, label
def __len__(self):
pass
train_dataset = ImagenetDataset(xxx)
test_dataset = ImagenetDataset(xxx)
train_dataloader = MNN.data.DataLoader(train_dataset, batch_size=1, num_workers=4, shuffle=True)
test_dataloader = MNN.data.DataLoader(test_dataset, batch_size=1, num_workers=4, shuffle=False)
加载模型
import MNN
nn = MNN.nn
F = MNN.expr
m = F.load_as_dict(model_file_path)
#这里的input_name、output_name跟前面将pth转为onnx时设置的input_name、output_name一样
inputs_outputs = F.get_inputs_and_outputs(m)
for key in inputs_outputs[0].keys():
print('input names:\t', key)
for key in inputs_outputs[1].keys():
print('output names:\t', key)
inputs = [m['input']]
outputs = [m['output']]
net = nn.load_module(inputs, outputs, for_training=True)
将模型设置为训练量化模式
#默认int8
nn.compress.train_quant(net, quant_bits=8)
定义优化器
opt = MNN.optim.SGD(net, 1e-5, 0.9, 0.00004)
训练
net.train(True)
train_dataloader.reset()
for i in range(train_dataloader.iter_number):
data, label = train_dataloader.next()
predict = net.forward(data)
loss = nn.loss.cross_entropy(predict, label)
opt.step(loss)
测试
net.train(False)
test_dataloader.reset()
for i in range(test_dataloader.iter_number):
data, label= test_dataloader.next()
predict = net(data) # 用 net.forwar() 应该也可以,没试过
loss = nn.loss.cross_entropy(predict, label)
predict = np.array(predict.read())
label = np.array(label.read())
correct = (np.sum(label == predict))
保存模型
predict = net.forward(F.placeholder([1, 10, 64], F.NCHW))
F.save([predict], file_name)
量化精度
浮点精度 > 训练量化精度 > 离线量化精度
训练量化的过程中精度会
逐渐降低
并介于浮点精度与离线量化精度之间。















 763
763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









