






BERT: 语言理解深度双向转换器的预训练
0、摘要
我们引入了一种称为 BERT 的新语言表示模型,它代表来自 Transformers 的双向编码器表示。 与最近的语言表示模型(Peters 等人,2018a;Radford 等人,2018)不同,BERT 旨在通过联合调节所有层中的左右上下文来预训练未标记文本的深度双向表示。 因此,预训练的 BERT 模型可以通过一个额外的输出层进行微调,从而为广泛的任务创建最先进的模型,例如问答和语言推理,而无需对特定任务的架构进行大量修改。
BERT 在概念上很简单,在经验上很强大。 它在 11 个自然语言处理任务上获得了新的 state-of-the-art 结果,包括将 GLUE 分数推至 80.5%(7.7% 点绝对提升),MultiNLI 准确率提升至 86.7%(4.6% 绝对提升),SQuAD v1.1 问题回答测试 F1 至 93.2(1.5 分绝对改进)和 SQuAD v2.0 测试 F1 至 83.1(5.1 分绝对改进)。
1、介绍
语言模型预训练已被证明可有效改善许多自然语言处理任务(Dai 和 Le,2015 年;Peters 等人,2018a;Radford 等人,2018 年;Howard 和 Ruder,2018 年)。 这些包括自然语言推理(Bowman 等人,2015 年;Williams 等人,2018 年)和释义(Dolan 和 Brockett,2005 年)等句子级任务,旨在通过整体分析来预测句子之间的关系,如 以及标记级任务,例如命名实体识别和问答,其中模型需要在标记级生成细粒度输出(Tjong Kim Sang 和 De Meulder,2003 年;Rajpurkar 等人,2016 年)。
将预训练语言表示应用于下游任务有两种现有策略:基于特征和微调。 基于特征的方法,例如 ELMo(Peters 等人,2018a),使用特定于任务的架构,其中包括预训练表示作为附加特征。 微调方法,例如生成式预训练转换器 (OpenAI GPT)(Radford 等人,2018 年),引入了最少的任务特定参数,并通过简单地微调所有预训练参数来对下游任务进行训练。 这两种方法在预训练期间共享相同的目标函数,它们使用单向语言模型来学习通用语言表示。
我们认为当前的技术限制了预训练表征的能力,尤其是微调方法。 主要限制是标准语言模型是单向的,这限制了可以在预训练期间使用的体系结构的选择。 例如,在 OpenAI GPT 中,作者使用从左到右的架构,其中每个标记只能关注 Transformer 的self-attention层中的先前标记(Vaswani 等人,2017)。 这样的限制对于句子级任务来说是次优的,并且在将基于微调的方法应用于标记级任务(例如问答)时可能非常有害,因为在这些任务中,从两个方向结合上下文是至关重要的。
在本文中,我们通过提出 BERT:Bidirectional Encoder Representations from Transformers 改进了基于微调的方法。 BERT 通过使用受 Cloze 任务 (Taylor, 1953) 启发的“掩蔽语言模型”(MLM) 预训练目标来缓解前面提到的单向性约束。 屏蔽语言模型从输入中随机屏蔽一些标记,目标是仅根据其上下文预测屏蔽词的原始词汇表 ID。 与从左到右的语言模型预训练不同,MLM 目标使表示能够融合左右上下文,这使我们能够预训练深度双向 Transformer。 除了掩码语言模型,我们还使用了“下一句预测”任务,联合预训练文本对表示。 我们论文的贡献如下:
-
我们证明了双向预训练对语言表征的重要性。 与 Radford (2018)等人不同,它使用单向语言模型进行预训练,BERT 使用掩码语言模型来启用预训练的深度双向表示。 这也与 Peters (2018a)等人形成对比,它使用独立训练的从左到右和从右到左的 LM 的浅层级联。
-
我们表明,预训练表示减少了对许多精心设计的任务特定架构的需求。 BERT 是第一个基于微调的表示模型,它在大量句子级和标记级任务上实现了最先进的性能,优于许多特定于任务的架构。
-
BERT 提升了十一项 NLP 任务的最新技术水平。 代码和预训练模型可在 GitHub - google-research/bert: TensorFlow code and pre-trained models for BERT 获取。
2、相关工作
预训练通用语言表征有着悠久的历史,我们在本节中简要回顾了最广泛使用的方法。
2.1、无监督的基于特征的方法
几十年来,学习广泛适用的单词表示一直是一个活跃的研究领域,包括非神经网络(Brown 等人,1992 年;Ando 和 Zhang,2005 年;Blitzer 等人,2006 年)和神经网络(Mikolov 等人,2013 年) ; Pennington 等人,2014)方法。 预训练词嵌入是现代 NLP 系统不可或缺的一部分,与从头开始学习的嵌入相比有了显着改进(Turian 等人,2010 年)。 为了预训练词嵌入向量,使用了从左到右的语言建模目标(Mnih 和 Hinton,2009),以及在左右语境中区分正确词和错误词的目标(Mikolov 等人,2013 年)。
这些方法已被推广到更粗粒度,例如句子嵌入(Kiros 等人,2015 年;Logeswaran 和 Lee,2018 年)或段落嵌入(Le 和 Mikolov,2014 年)。 为了训练句子表示,之前的工作使用目标对候选的下一个句子进行排名(Jernite 等人,2017 年;Logeswaran 和 Lee,2018 年),在给定前一个句子的表示的情况下从左到右生成下一个句子单词(Kiros 等人) al., 2015),或去噪自动编码器派生目标 (Hill et al., 2016)。
ELMo 及其前身 (Peters et al., 2017, 2018a) 从不同的维度概括了传统的词嵌入研究。 他们从从左到右和从右到左的语言模型中提取上下文相关的特征。 每个标记的上下文表示是从左到右和从右到左表示的串联。 当将上下文词嵌入与现有的特定于任务的架构相结合时,ELMo 提高了几个主要 NLP 基准(Peters 等人,2018a)的技术水平,包括问答(Rajpurkar 等人,2016)、情感分析(Socher 等人) ., 2013) 和命名实体识别 (Tjong Kim Sang 和 De Meulder, 2003)。 Melamud 等人。 (2016) 提出通过使用 LSTM 从左右上下文预测单个单词的任务来学习上下文表示。 与 ELMo 类似,他们的模型是基于特征的,而不是深度双向的。 费杜斯等人(2018) 表明完形填空任务可用于提高文本生成模型的稳健性。
2.2、无监督微调方法
与基于特征的方法一样,第一种方法在这个方向上只使用来自未标记文本的预训练词嵌入参数(Collobert 和 Weston,2008)。
最近,生成上下文标记表示的句子或文档编码器已经从未标记的文本中进行了预训练,并针对受监督的下游任务进行了微调(Dai 和 Le,2015 年;Howard 和 Ruder,2018 年;Radford 等人,2018 年)。 这些方法的优点是需要从头开始学习的参数很少。 至少部分由于这一优势,OpenAI GPT(Radford 等人,2018 年)在 GLUE 基准测试(Wang 等人,2018a)的许多句子级任务上取得了先前最先进的结果。 从左到右的语言建模和自动编码器目标已用于预训练此类模型(Howard 和 Ruder,2018 年;Radford 等人,2018 年;Dai 和 Le,2015 年)。
2.3、从监督数据中迁移学习
还有一些工作表明,从具有大型数据集的监督任务中可以有效迁移,例如自然语言推理 (Conneau et al., 2017) 和机器翻译 (McCann et al., 2017)。 计算机视觉研究还证明了从大型预训练模型进行迁移学习的重要性,其中一个有效的方法是微调使用 ImageNet 预训练的模型(Deng 等人,2009 年;Yosinski 等人,2014 年)。
3、BERT
我们在本节中介绍 BERT 及其详细实现。 我们的框架有两个步骤:预训练和微调。 在预训练期间,模型在不同的预训练任务上使用未标记的数据进行训练。 对于微调,BERT 模型首先使用预训练参数进行初始化,然后使用来自下游任务的标记数据对所有参数进行微调。 每个下游任务都有单独的微调模型,即使它们是使用相同的预训练参数初始化的。 图 1 中的问答示例将作为本节的运行示例。 BERT 的一个显着特点是其跨不同任务的统一架构。 预训练架构和最终下游架构之间的差异很小。

图 1:BERT 的整体预训练和微调程序。 除了输出层之外,相同的架构还用于预训练和微调。 相同的预训练模型参数用于为不同的下游任务初始化模型。 在微调期间,对所有参数进行微调。 [CLS] 是在每个输入示例前面添加的特殊符号,[SEP] 是特殊的分隔符(例如分隔问题/答案)。
模型架构 BERT 的模型架构是基于 Vaswani 等人描述的原始实现的多层双向 Transformer 编码器。 (2017) 并在 tensor2tensor 库中发布[1]。由于 Transformer 的使用变得普遍,我们的实现与原始实现几乎相同,因此我们将省略对模型架构的详尽背景描述,并将读者推荐给 Vaswani 等人。 (2017) 以及优秀的指南,例如“The Annotated Transformer”[2]。
在这项工作中,我们将层数(即 Transformer 块)表示为 L,将隐藏大小表示为 H,并将自注意力头的数量表示为 作为 A[3]。我们主要报告两种模型大小的结果:BERTBASE(L=12,H=768,A=12,总参数=110M)和 BERTLARGE(L=24,H=1024,A=16,总参数= 340M)。 出于比较目的,选择 BERTBASE 使其具有与 OpenAI GPT 相同的模型大小。 然而,至关重要的是,BERT Transformer 使用双向自注意力,而 GPT Transformer 使用受限自注意力,其中每个标记只能关注其左侧的上下文[4]。
[3]In all cases we set the feed-forward/filter size to be 4H, i.e., 3072 for the H = 768 and 4096 for the H = 1024.
[4]We note that in the literature the bidirectional Transformer is often referred to as a “Transformer encoder” while the left-context-only version is referred to as a “Transformer decoder” since it can be used for text generation.
输入/输出表示为了使 BERT 处理各种下游任务,我们的输入表示能够在一个标记序列中明确表示单个句子和一对句子(例如,<问题,答案>)。 在这项工作中,一个“句子”可以是任意一段连续的文本,而不是一个实际的语言句子。 “序列”是指输入给 BERT 的 token 序列,它可以是单个句子,也可以是两个句子打包在一起。 我们使用具有 30,000 个标记词汇表的 WordPiece 嵌入(Wu 等人,2016 年)。 每个序列的第一个标记总是一个特殊的分类标记([CLS])。 该标记对应的最终隐藏状态用作分类任务的聚合序列表示。 句子对被打包成一个序列。 我们以两种方式区分句子。 首先,我们用特殊标记 ([SEP]) 将它们分开。 其次,我们向每个标记添加一个学习嵌入,指示它是属于句子 A 还是句子 B。如图 1 所示,我们将输入嵌入表示为 E,特殊 [CLS] 标记的最终隐藏向量为 C ∈ RH, 第 i 个输入标记的最终隐藏向量为 Ti ∈ RH。 对于给定的标记,其输入表示是通过对相应的标记、段和位置嵌入求和来构建的。 这种结构的可视化可以在图 2 中看到。
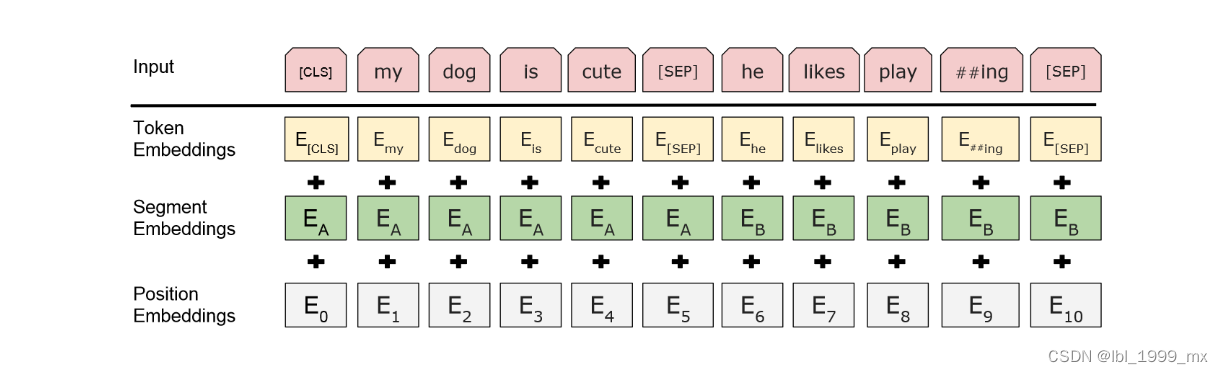
图 2:BERT 输入表示。 输入嵌入是标记嵌入、分割嵌入和位置嵌入的总和。
3.1、预训练BERT
与彼得斯等人不同。 (2018a) 和 Radford 等人。 (2018),我们不使用传统的从左到右或从右到左的语言模型来预训练 BERT。 相反,我们使用本节中描述的两个无监督任务对 BERT 进行预训练。 此步骤显示在图 1 的左侧部分。
任务 #1:Masked LM 直觉上,有理由相信深度双向模型比从左到右模型或从左到右和从右到左模型的浅层级联更强大。 不幸的是,标准的条件语言模型只能从左到右或从右到左进行训练,因为双向条件会让每个词间接地“看到自己”,并且模型可以简单地预测多层中的目标词 语境。
为了训练深度双向表示,我们只是随机屏蔽一定比例的输入标记,然后预测这些屏蔽的标记。 我们将此过程称为“掩蔽 LM”(MLM),尽管它在文献中通常被称为完形填空任务 (Taylor, 1953)。 在这种情况下,与掩码标记对应的最终隐藏向量被馈送到词汇表上的输出 softmax,就像在标准 LM 中一样。 在我们所有的实验中,我们随机屏蔽每个序列中所有 WordPiece 标记的 15%。 与去噪自动编码器 (Vincent et al., 2008) 相比,我们只预测屏蔽词而不是重建整个输入。
虽然这使我们能够获得双向预训练模型,但缺点是我们在预训练和微调之间造成了不匹配,因为 [MASK] 令牌在微调期间不会出现。 为了缓解这种情况,我们并不总是用实际的 [MASK] 标记替换“掩码”词。 训练数据生成器随机选择 15% 的标记位置进行预测。 如果选择了第 i 个标记,我们将第 i 个标记替换为 (1) [MASK] 标记 80% 的时间 (2) 随机标记 10% 的时间 (3) 未更改的第 i 个标记 10% 的时间。 然后,Ti 将用于预测具有交叉熵损失的原始标记。 我们在附录 C.2 中比较了此过程的变体。
任务 2:下一句预测 (NSP) 许多重要的下游任务,例如问答 (QA) 和自然语言推理 (NLI),都是基于理解两个句子之间的关系,而语言建模并没有直接捕捉到这种关系。 为了训练一个理解句子关系的模型,我们预训练了一个二值化的下一句预测任务,该任务可以从任何单语语料库中简单地生成。 具体来说,当为每个预训练示例选择句子 A 和 B 时,50% 的时间 B 是 A 之后的实际下一个句子(标记为 IsNext),50% 的时间是语料库中的随机句子(标记为 IsNext) 作为 NotNext)。 正如我们在图 1 中所示,C 用于下一句预测 (NSP)[5]。尽管它很简单,但我们在第 5.1 节中证明了针对此任务的预训练对 QA 和 NLI 都非常有益[6]。NSP 任务与 Jernite 等人使用的表征学习目标密切相关。 (2017) 以及 Logeswaran 和 Lee (2018)。 然而,在之前的工作中,只有句子嵌入被转移到下游任务,其中 BERT 转移所有参数以初始化结束任务模型参数。
[5]The final model achieves 97%-98% accuracy on NSP.
[6]The vector C is not a meaningful sentence representation without fine-tuning, since it was trained with NSP.
预训练数据预训练过程在很大程度上遵循了关于语言模型预训练的现有文献。 对于预训练语料库,我们使用 BooksCorpus(800M 词)(Zhu et al., 2015)和英语维基百科(2,500M 词)。 对于维基百科,我们只提取文本段落并忽略列表、表格和标题。 为了提取长的连续序列,使用文档级语料库而不是像 Billion Word Benchmark (Chelba et al., 2013) 这样的打乱句子级语料库至关重要。
3.2、微调BERT
微调很简单,因为 Transformer 中的自注意力机制允许 BERT 通过交换适当的输入和输出来模拟许多下游任务,无论它们涉及单个文本还是文本对。 对于涉及文本对的应用程序,一种常见的模式是在应用双向交叉注意力之前独立编码文本对,例如 Parikh 等人。 (2016); 徐等。 (2017)。 BERT 使用自注意力机制来统一这两个阶段,因为使用自注意力编码串联文本对有效地包括两个句子之间的双向交叉注意力。
对于每项任务,我们只需将任务特定的输入和输出插入 BERT,然后端到端地微调所有参数。 在输入端,来自预训练的句子 A 和句子 B 类似于 (1) 释义中的句子对,(2) 蕴涵中的假设-前提对,(3) 问答中的问题-段落对,以及 (4) a 文本分类或序列标记中的退化文本-∅对。 在输出端,令牌表示被馈送到令牌级任务的输出层,例如序列标记或问题回答,[CLS] 表示被馈送到输出层以进行分类,例如蕴含或情感分析。
与预训练相比,微调相对便宜。 从完全相同的预训练模型开始,在单个 Cloud TPU 上最多可在 1 小时内或在 GPU 上几小时内复制本文中的所有结果[7]。我们在相应的任务中描述了特定于任务的详细信息 第 4 节的小节。更多详细信息可以在附录 A.5 中找到。
[7]For example, the BERT SQuAD model can be trained in around 30 minutes on a single Cloud TPU to achieve a Dev F1 score of 91.0%.
4、实验
在本节中,我们将展示 BERT 在 11 个 NLP 任务上的微调结果。
4.1、GLUE
通用语言理解评估 (GLUE) 基准 (Wang et al., 2018a) 是多种自然语言理解任务的集合。 GLUE 数据集的详细描述包含在附录 B.1 中。 为了在 GLUE 上进行微调,我们如第 3 节所述表示输入序列(对于单个句子或句子对),并使用对应于第一个输入标记 ([CLS]) 的最终隐藏向量 C ∈ RH 作为聚合表示 . 在微调期间引入的唯一新参数是分类层权重 W ∈ RK×H ,其中 K 是标签的数量。 我们使用 C 和 W 计算标准分类损失,即 log(softmax(CW T ))。
[8]See (10) in GLUE Benchmark.

表 1:GLUE 测试结果,由评估服务器 (GLUE Benchmark) 评分。 每个任务下方的数字表示训练示例的数量。 “平均”列与官方 GLUE 分数略有不同,因为我们排除了有问题的 WNLI 集。8 BERT 和 OpenAI GPT 是单一模型、单一任务。 QQP 和 MRPC 报告了 F1 分数,STS-B 报告了 Spearman 相关性,其他任务报告了准确性分数。 我们排除了使用 BERT 作为其组件之一的条目。
我们使用 32 的批量大小,并对所有 GLUE 任务的数据进行 3 个周期的微调。 对于每个任务,我们在开发集上选择了最佳微调学习率(在 5e-5、4e-5、3e-5 和 2e-5 之间)。 此外,对于 BERTLARGE,我们发现微调有时在小型数据集上不稳定,因此我们运行了几次随机重启并选择了开发集上的最佳模型。 通过随机重启,我们使用相同的预训练检查点,但执行不同的微调数据洗牌和分类器层初始化[9]。
[9]The GLUE data set distribution does not include the Test labels, and we only made a single GLUE evaluation server submission for each of BERTBASE and BERTLARGE.
结果如表 1 所示。BERTBASE 和 BERTLARGE 在所有任务上的表现都大大优于所有系统,获得 4.5 % 和 7.0% 的平均准确度分别比现有技术水平提高。 请注意,除了注意掩蔽之外,BERTBASE 和 OpenAI GPT 在模型架构方面几乎相同。 对于最大和最广泛报道的 GLUE 任务 MNLI,BERT 获得了 4.6% 的绝对精度提升。 在官方 GLUE 排行榜[10] 上,BERTLARGE 获得 80.5 分,而 OpenAI GPT 在撰写本文时获得 72.8 分。 我们发现 BERTLARGE 在所有任务上都明显优于 BERTBASE,尤其是那些训练数据很少的任务。 模型大小的影响在 5.2 节中进行了更彻底的探讨。
[10]GLUE Benchmark
4.2、SQuAD v1.1
斯坦福问答数据集 (SQuAD v1.1) 是 10 万个众包问答对的集合(Rajpurkar 等人,2016 年)。 给定一个问题和一段来自维基百科的包含答案的文章,任务是预测文章中的答案文本跨度。
如图 1 所示,在问答任务中,我们将输入问题和文章表示为单个打包序列,问题使用 A 嵌入,文章使用 B 嵌入。 我们只在微调期间引入起始向量 S ∈ RH 和结束向量 E ∈ RH。 单词 i 作为答案跨度开始的概率计算为 Ti 和 S 之间的点积,后跟段落中所有单词的 softmax:。类似的公式用于答案跨度的结尾。 从位置i到位置j的候选跨度的得分定义为S·Ti + E·Tj,并使用j ≥ i的最大得分跨度作为预测。 训练目标是正确开始和结束位置的对数似然之和。 我们以 5e-5 的学习率和 32 的批量大小对 3 个 epoch 进行微调。
表 2 显示了顶级排行榜条目以及顶级已发布系统的结果(Seo 等人,2017 年;Clark 和 Gardner,2018 年;Peters 等人,2018a;Hu 等人,2018 年)。 SQuAD 排行榜的顶级结果没有可用的最新公共系统描述[11],并且在训练他们的系统时允许使用任何公共数据。 因此,我们通过首先对 TriviaQA(Joshi 等人,2017)进行微调,然后再对 SQuAD 进行微调,在我们的系统中使用适度的数据增强。
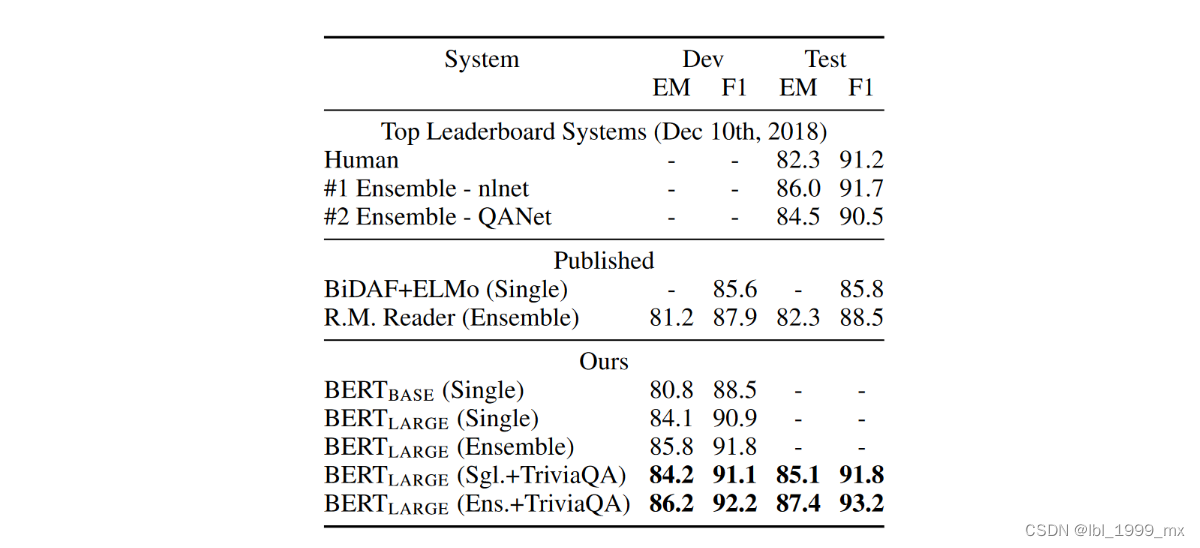
表 2:SQuAD 1.1 结果。 BERT 集成是 7x 系统,它使用不同的预训练检查点和微调种子。
[11]QANet is described in Yu et al. (2018), but the system has improved substantially after publication.
我们表现最好的系统在集成方面比顶级排行榜系统高出 +1.5 F1,在单个系统中高出 +1.3 F1。 事实上,我们的单一 BERT 模型在 F1 分数方面优于顶级集成系统。 如果没有 TriviaQA 微调数据,我们仅损失 0.1-0.4 F1,仍然大大优于所有现有系统[12]。
[12]The TriviaQA data we used consists of paragraphs from TriviaQA-Wiki formed of the first 400 tokens in documents, that contain at least one of the provided possible answers.
4.3、SQuAD v2.0
SQuAD 2.0 任务扩展了 SQuAD 1.1 问题定义,允许在提供的段落中不存在简短答案的可能性,从而使问题更加现实。 我们使用一种简单的方法来扩展 SQuAD v1.1 BERT 模型来完成这项任务。 我们将没有答案的问题视为具有以 [CLS] 标记开始和结束的答案范围。 开始和结束答案跨度位置的概率空间被扩展到包括 [CLS] 标记的位置。 对于预测,我们将无答案跨度的分数:Snull = SC + EC 与最佳非空跨度 s_hat i,j = max{S·Ti + E·Tj,j>=i} 的分数进行比较。 当 s_hat i,j > Snull + τ(tau) 时,我们预测一个非空答案,其中在开发集上选择阈值 τ 以最大化 F1。 我们没有为这个模型使用 TriviaQA 数据。 我们微调了 2 个 epoch,学习率为 5e-5,batch size 为 48。
表 3 显示了与之前的排行榜条目和发表的最佳作品(Sun 等人,2018 年;Wang 等人,2018b)相比的结果,不包括使用 BERT 作为其组件之一的系统。 我们观察到 F1 比之前的最佳系统提高了 +5.1。

表 3:SQuAD 2.0 结果。 我们排除了使用 BERT 作为其组件之一的条目。
4.4、SWAG
Adversarial Generations (SWAG) 数据集包含 113k 个句子对完成示例,用于评估基于常识的推理(Zellers 等人,2018 年)。 给定一个句子,任务是在四个选项中选择最合理的延续。
在对 SWAG 数据集进行微调时,我们构建了四个输入序列,每个序列都包含给定句子(句子 A)和可能的延续(句子 B)的串联。 唯一引入的特定于任务的参数是一个向量,其与 [CLS] 标记表示 C 的点积表示每个选择的分数,该分数用 softmax 层归一化。
我们用 2e-5 的学习率和 16 的批量大小对模型进行了 3 个周期的微调。结果如表 4 所示。BERTLARGE 比作者的基线 ESIM+ELMo 系统高 27.1%,比 OpenAI GPT 高 8.3% %。
表 4:SWAG 开发和测试精度。 †如 SWAG 论文中所报告的,人类表现是通过 100 个样本来衡量的。
5、消融实验
在本节中,我们对 BERT 的多个方面进行消融实验,以更好地了解它们的相对重要性。 其他消融研究可以在附录 C 中找到。
5.1、预训练任务的效果
我们通过使用与 BERTBASE 完全相同的预训练数据、微调方案和超参数评估两个预训练目标,证明了 BERT 深度双向性的重要性:
No NSP:使用“masked LM”(MLM)训练但没有“下一句预测”(NSP)任务的双向模型。
LTR & No NSP:使用标准的从左到右 (LTR) LM 而不是 MLM 训练的左上下文模型。 仅左约束也适用于微调,因为移除它会引入预训练/微调不匹配,从而降低下游性能。 此外,该模型是在没有 NSP 任务的情况下进行预训练的。 这可以直接与 OpenAI GPT 相媲美,但使用我们更大的训练数据集、我们的输入表示和我们的微调方案。
我们首先检查 NSP 任务带来的影响。 在表 5 中,我们表明移除 NSP 会显着影响 QNLI、MNLI 和 SQuAD 1.1 的性能。 接下来,我们通过较“No NSP”和“LTR & No NSP”来评估训练双向表示的影响。 LTR 模型在所有任务上的表现都比 MLM 模型差,在 MRPC 和 SQuAD 上有较大下降。
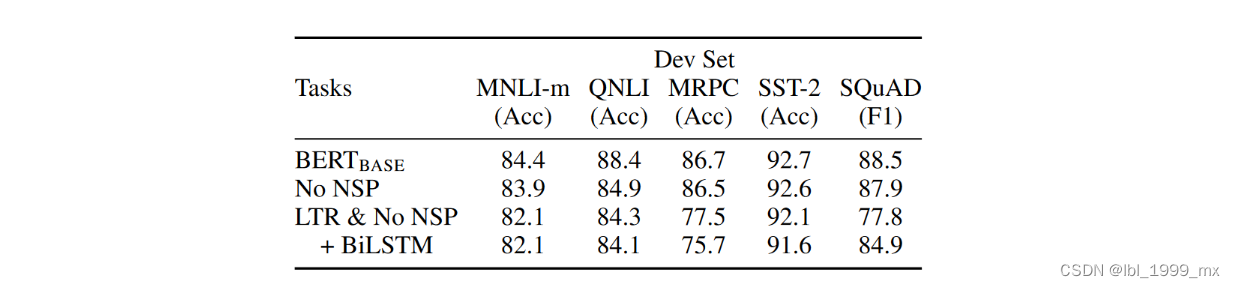
表 5:使用 BERTBASE 架构对预训练任务进行消融。 “No NSP”是在没有下一句预测任务的情况下训练的。 “LTR & No NSP”被训练为一个从左到右的 LM,没有下一句预测,就像 OpenAI GPT。 “+ BiLSTM”在微调期间在“LTR + No NSP”模型之上添加了一个随机初始化的 BiLSTM。
对于 SQuAD,直觉上很明显 LTR 模型在令牌预测方面表现不佳,因为令牌级隐藏状态没有右侧上下文。 为了真诚地尝试加强 LTR 系统,我们在顶部添加了一个随机初始化的 BiLSTM。 这确实显着改善了 SQuAD 的结果,但结果仍然比预训练的双向模型差得多。 BiLSTM 会损害 GLUE 任务的性能。
我们认识到,也可以训练单独的 LTR 和 RTL 模型,并将每个标记表示为两个模型的串联,就像 ELMo 所做的那样。 但是:(a) 这比单个双向模型贵两倍; (b) 这对于 QA 之类的任务来说是不直观的,因为 RTL 模型无法将问题的答案作为条件; (c) 它严格来说不如深度双向模型强大,因为它可以在每一层同时使用左右上下文。
5.2、模型尺寸的影响
在本节中,我们探讨了模型大小对微调任务准确性的影响。 我们训练了许多具有不同层数、隐藏单元和注意力头的 BERT 模型,同时使用与之前描述的相同的超参数和训练过程。
所选 GLUE 任务的结果如表 6 所示。在此表中,我们报告了 5 次随机重新启动微调的平均开发集准确度。 我们可以看到,较大的模型导致所有四个数据集的精确度都得到了严格的提高,即使对于只有 3,600 个标记训练示例且与预训练任务有很大不同的 MRPC 也是如此。 同样令人惊讶的是,我们能够在相对于现有文献已经相当大的模型之上实现如此显着的改进。 例如,Vaswani 等人探索的最大的变形金刚。 (2017)是(L=6, H=1024, A=16) encoder参数100M,我们在文献中找到的最大Transformer是(L=64, H=512, A=2) 235M 参数(Al-Rfou 等人,2018 年)。 相比之下,BERTBASE 包含 110M 个参数,BERTLARGE 包含 340M 个参数。
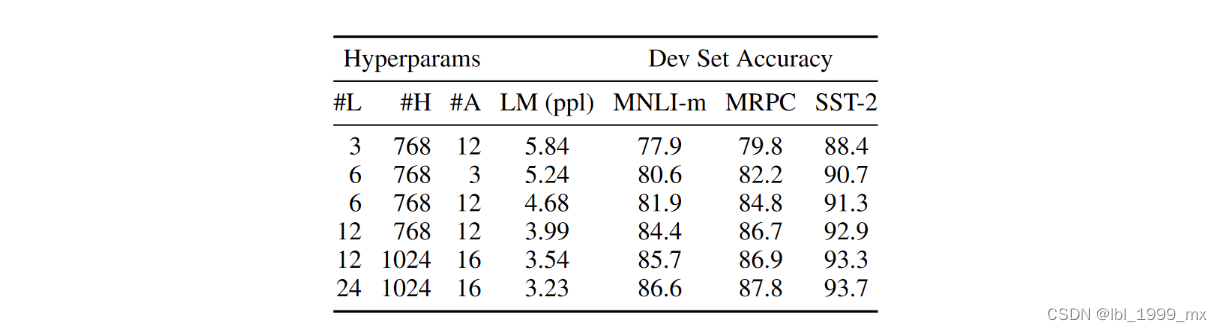
表 6:BERT 模型大小的消融。 #L = 层数; #H = 隐藏尺寸; #A = 注意力头的数量。 “LM (ppl)”是保留训练数据的掩蔽 LM 困惑度。
人们早就知道,增加模型大小将导致机器翻译和语言建模等大规模任务的持续改进,表 6 中显示的保留训练数据的 LM 困惑证明了这一点。但是,我们相信 这是第一项令人信服地证明扩展到极端模型大小也会导致非常小规模任务的大幅改进的工作,前提是模型已经过充分的预训练。 彼得斯等人。 (2018b) 提出了将预训练的双 LM 大小从两层增加到四层对下游任务影响的混合结果,Melamud 等人。 (2016) 顺便提到将隐藏维度大小从 200 增加到 600 有所帮助,但进一步增加到 1,000 并没有带来进一步的改进。 这两项先前的工作都使用了基于特征的方法——我们假设当模型直接在下游任务上进行微调并且只使用非常少量的随机初始化的附加参数时,特定于任务的模型可以受益于更大、更具表现力的 pre -训练有素的表示,即使下游任务数据非常小。
5.3、基于特征的 BERT 方法
到目前为止呈现的所有 BERT 结果都使用了微调方法,即在预训练模型中添加一个简单的分类层,并在下游任务上联合微调所有参数。 然而,从预训练模型中提取固定特征的基于特征的方法具有一定的优势。 首先,并非所有任务都可以轻松地由 Transformer 编码器架构表示,因此需要添加特定于任务的模型架构。 其次,预先计算训练数据的昂贵表示一次,然后在该表示之上使用更便宜的模型运行许多实验,有很大的计算优势。
在本节中,我们通过将 BERT 应用于 CoNLL-2003 命名实体识别 (NER) 任务(Tjong Kim Sang 和 De Meulder,2003)来比较这两种方法。 在 BERT 的输入中,我们使用了一个保留大小写的 WordPiece 模型,并且我们包含了数据提供的最大文档上下文。 按照标准做法,我们将其制定为标记任务,但不在输出中使用 CRF 层。 我们使用第一个子标记的表示作为 NER 标签集上标记级分类器的输入。
为了消除微调方法,我们通过从一个或多个层中提取激活来应用基于特征的方法,而无需微调 BERT 的任何参数。 这些上下文嵌入用作分类层之前随机初始化的两层 768 维 BiLSTM 的输入。
结果如表 7 所示。BERTLARGE 的表现与最先进的方法相比具有竞争力。 性能最好的方法连接来自预训练 Transformer 前四个隐藏层的标记表示,这仅比微调整个模型落后 0.3 F1。 这表明 BERT 对于微调和基于特征的方法都是有效的。
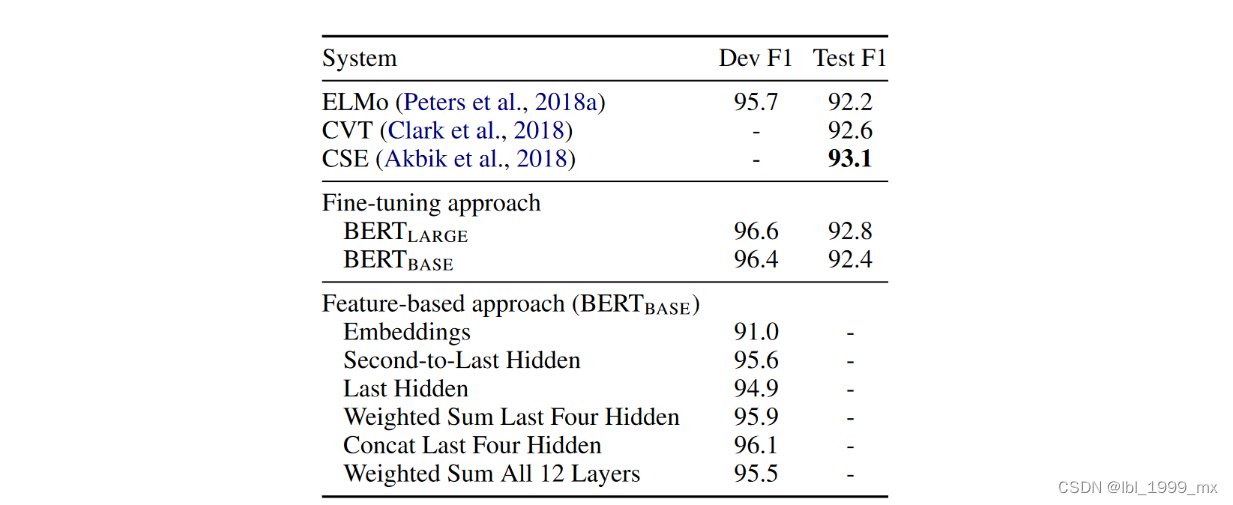
表 7:CoNLL-2003 命名实体识别结果。 使用开发集选择超参数。 报告的开发和测试分数是使用这些超参数对 5 次随机重启进行平均的。
6、结论
最近由于使用语言模型进行迁移学习而带来的实证改进表明,丰富的、无监督的预训练是许多语言理解系统不可或缺的一部分。 特别是,这些结果甚至使低资源任务也能从深度单向架构中受益。 我们的主要贡献是将这些发现进一步推广到深度双向架构,使相同的预训练模型能够成功处理广泛的 NLP 任务。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









