







论文标题:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
论文链接:https://arxiv.org/abs/1810.04805
一、概述
- 简介
BERT(Bidirectional Encoder Representations from Transformers)通过预训练来学习无标注数据中的深度双向表示,预训练结束后通过添加一个额外的输出层进行微调,最终在多个NLP任务上实现了SOTA。
预训练语言模型在实践中证明对提高很多自然语言处理任务有效,其中包括句子层级的任务,比如自然语言推断(natural language inference)和复述(paraphrasing),还有token层级的任务,比如命名实体识别(named entity recognition)和问答(question answering)。
- 预训练模型使用方法
在下游任务中应用预训练语言模型表示的方法有两种:feature-based的方法和fine-tuning的方法。举例来说,ELMo这种预训练语言模型使用feature-based的方法,通过将ELMo的预训练的表示作为额外的特征输入到特定于任务的模型中去;GPT使用fine-tuning的方法,通过引入少量的特定于任务的参数,在下游任务中训练时所有的预训练参数。
- 语言模型的单向与双向
截止BERT之前的预训练语言模型都是单向的(unidirectional),包括GPT和ELMo,这样的方法对句子层级的任务不是最优的,而且对于token层级的任务比如问答非常有害。BERT使用masked language model(MLM)的方法来预训练,这种方法能够训练一个双向的(directional)语言模型。除了masked language model的预训练的方法,BERT还使用了next sentence prediction的预训练方法。
- BERT的贡献
-
BERT证明了双向预训练的重要性;
-
BERT减少了对精心设计的特定于下游任务中的架构的依赖;
-
BERT在11个下游任务上达到了SOTA。
二、BERT
BERT的使用分为两个阶段:预训练(pre-training)和微调(fine-tuning)。预训练阶段模型通过两种不同的预训练任务来训练无标注数据。微调阶段模型使用预训练参数初始化,然后使用下游任务(downstream task)的标注数据来微调参数。
BERT的一个显著特点是它在不同的任务上有统一的架构,使用时只需要在BERT后面接上下游任务的结构即可使用。
- 模型架构
BERT的模型架构是一个多层双向的Transformer的encoder。我们标记模型的层数(每一层是一个Tranformer的block)为 L L L,模型的hidden size为 H H H,self-attention head的数量为 A A A。两个比较通用的BERT架构为 B E R T B A S E ( L = 12 , H = 768 , A = 12 , T o t a l P a r a m e t e r s = 110 M ) BERT_{BASE}(L=12,H=768,A=12,Total\; Parameters=110M) BERTBASE(L=12,H=768,A=12,TotalParameters=110M)和 B E R T L A R G E ( L = 24 , H = 1024 , A = 16 , T o t a l P a r a m e t e r s = 340 M ) BERT_{LARGE}(L=24,H=1024,A=16,Total\; Parameters=340M) BERTLARGE(L=24,H=1024,A=16,TotalParameters=340M)。
对比GPT,BERT使用了双向self-attention架构,而GPT使用的是受限的self-attention, 即限制每个token只能attend到其左边的token。
- BERT输入和输出的表示
BERT的输入表示能够是一个句子或者是一个句子对,这是为了让BERT能够应对各种不同的下游任务。BERT的输入是一个序列,该序列包含一个句子的token或者两个句子结合在一起的token。
具体地,我们会将输入的自然语言句子通过WordPiece embeddings来转化为token序列。这个token序列的开头要加上[CLS]这个特殊的token,最终输出的[CLS]这个token的embedding可以看做句子的embedding,可以使用这个embedding来做分类任务。
由于句子对被pack到了一起,因此我们需要在token序列中区分它们,具体需要两种方式:
①在token序列中两个句子的token之间添加[SEP]这样一个特殊的token;
②我们为每个token添加一个用来学习的embedding来区分token属于句子A还是句子B,这个embedding叫做segment embedding。
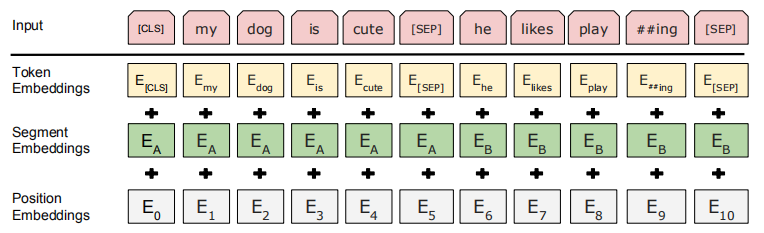
具体地,BERT的输入由三部分相加组成:token embeddings、segment embeddings和position embeddings。如下图所示:
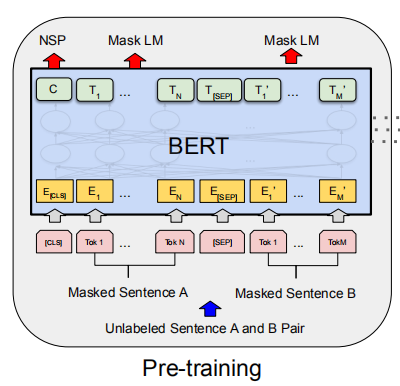
- BERT的预训练
BERT使用两个无监督的任务进行预训练,分别是Masked LM和Next Sentence Prediction(NSP)。如下图所示,我们定义输入的embedding为
E
E
E,BERT最终输出的[CLS]的embedding为
C
∈
R
H
C\in \mathbb{R}^{H}
C∈RH,最终输出的第
i
t
h
i^{th}
ith个token的embedding为
T
i
∈
R
H
T_{i}\in \mathbb{R}^{H}
Ti∈RH。
- Task 1: Masked LM
我们有理由相信一个深度双向模型比left-to-right模型和left-to-right和right-to-left简单连接的模型的效果更加强大。不幸的是,标准的条件语言模型只能够够left-to-right或者right-to-left地训练,这是因为双向条件会使每个token能够间接地“看到自己”,并且模型能够在多层上下文中简单地预测目标词。
为了能够双向地训练语言模型,BERT的做法是简单地随机mask掉一定比例的输入token(这些token被替换成[MASK]这个特殊token),然后预测这些被遮盖掉的token,这种方法就是Masked LM(MLM),相当于完形填空任务(cloze task)。被mask掉的词将会被输入到一个softmax分类器中,分类器输出的维度对应词典的大小。在预训练时通常为每个序列mask掉15%的token。与降噪自编码器(denoising auto-encoders)相比,我们只预测被mask掉的token,并不重建整个输入。
这种方法允许我们预训练一个双向的语言模型,但是有一个缺点就是造成了预训练和微调之间的mismatch,这是因为[MASK]这个token不会在微调时出现。为了缓解这一点,我们采取以下做法:在生成训练数据时我们随机选择15%的token进行替换,被选中的token有80%的几率被替换成[MASK],10%的几率被替换成另一个随机的token,10%的几率该token不被改变。然后
T
i
T_i
Ti将使用交叉熵损失来预测原来的token。
- Task 2: Next Sentence Prediction (NSP)
一些重要的NLP任务如Question Answering (QA)或者Natural Language Inference (NLI)需要理解句子之间的关系,而这种关系通常不会被语言模型直接捕捉到。为了使得模型能够理解句子之间的关系,我们训练了一个二值的Next Sentence Prediction任务,其训练数据可以从任何单语语料库中生成。具体的做法是:当选择句子A和句子B作为训练数据时,句子B有50%的几率的确是句子A的下一句(标签是IsNext),50%的几率是从语料库中随机选择的句子(标签是NotNext)。[CLS]对应的最后一个隐层输出向量被用来训练NSP任务,这个embedding就相当于sentence embedding。虽然这个预训练任务很简单,但是事实上在微调时其在QA和NLI任务上表现出了很好的效果。在前人的工作中,只有sentence embedding被迁移到下游任务中,而BERT会迁移所有的参数来初始化下游任务模型。
- BERT的微调
Transformer的self-attention机制允许BERT建模多种下游任务。对于包含句子对的任务,通常的做法是先独立地对句子对中的句子进行编码,然后再应用双向交叉注意(bidirectional cross attention)。而BERT使用self-attention机制统一了这两个过程,这是因为对拼接起来的句子对进行self-attention有效地包含了两个句子之间的双向交叉注意(bidirectional cross attention)。
对于每个任务来说,我们只需要将任务特定的输入输出插入到BERT中然后端到端地微调即可。举例子来说,BERT的预训练输入句子A和句子B在微调时可以类比为:
①paraphrasing任务中的句子对;
②entailment任务中的hypothesis-premise对;
③question answering任务中的question-passage对;
④text classification或者sequence tagging任务中的text-∅对(也就是只输入一个text,不必一定需要两个句子)。
对于BERT的输出,对于一些token-level的任务,BERT的token表示将被输入到一个输出层,比如sequence tagging或者question answering任务;对于entailment或者sentiment analysis这样的任务,可以将[CLS]对应的表示输入到一个输出层。
三、实验
- GLUE
我们使用[CLS]这个token的最后一层的隐层向量
C
∈
R
H
C\in \mathbb{R}^{H}
C∈RH作为聚合的表示,可以认为是sentence embedding。在微调时只引入一个新的权重
W
∈
R
K
×
H
W\in R^{K\times H}
W∈RK×H,这里的
K
K
K代表标签的数量,然后计算标准分类损失
l
o
g
(
s
o
f
t
m
a
x
(
C
W
T
)
)
log(softmax(CW^{T}))
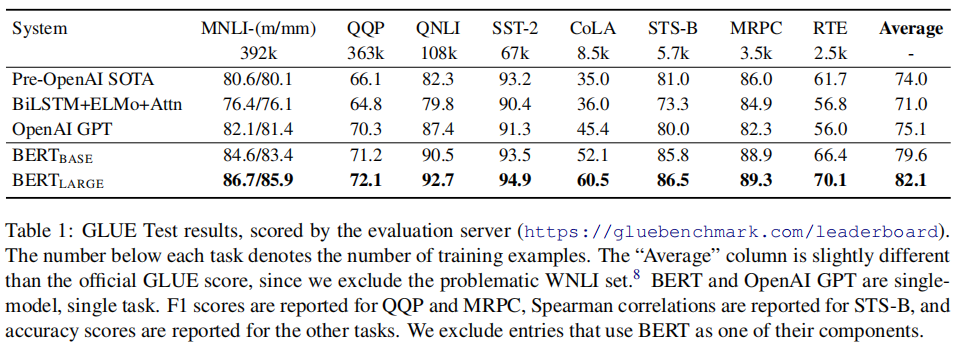
log(softmax(CWT))。下图展示了BERT在GLUE上的效果:
- SQuAD v1.1
在这个数据集上,我们将question和passage拼接起来作为一个输入序列(中间是[SEP])。在微调时引入一个start向量
S
∈
R
H
S\in \mathbb{R}^{H}
S∈RH和一个end向量
E
∈
R
H
E\in \mathbb{R}^{H}
E∈RH,计算
T
i
T_i
Ti和
S
S
S的点积然后通过
s
o
f
t
m
a
x
softmax
softmax函数作为word
i
i
i是答案的span起始位置的概率:
P
i
=
e
S
⋅
T
i
∑
j
e
S
⋅
T
j
P_{i}=\frac{e^{S\cdot T_{i}}}{\sum _{j}e^{S\cdot T_{j}}}
Pi=∑jeS⋅TjeS⋅Ti。答案的终止位置也做上述类似处理。从
i
i
i到
j
j
j的候选区间的得分记作
S
⋅
T
i
+
E
⋅
T
j
S\cdot T_{i}+E\cdot T_{j}
S⋅Ti+E⋅Tj,我们挑选
j
>
i
j>i
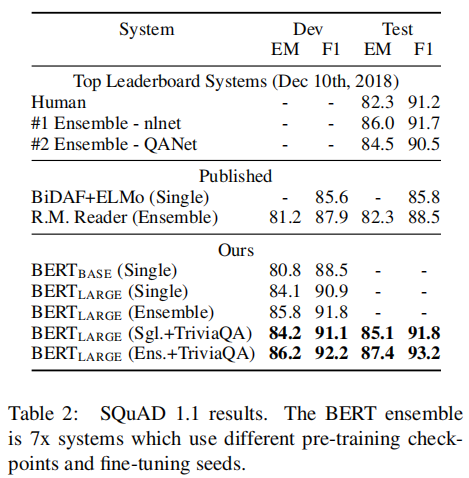
j>i的最大得分区间作为预测的结果。下图展示了BERT在SQuAD v1.1上的效果:
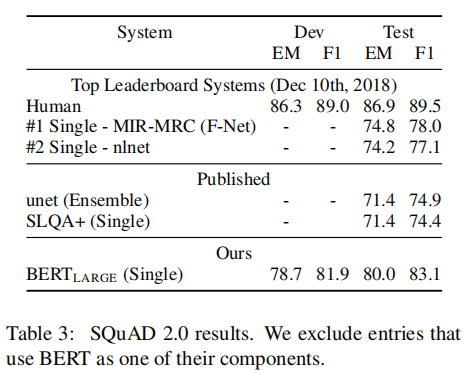
- SQuAD v2.0
SQuAD v2.0有的question在提供的passage中没有答案存在。在微调时我们设置没有答案的问题的span的起始和结束位置都是[CLS]这个token,也就是start和end的可能性空间包含进了[CLS]的位置。在预测时,我们比较没有答案的span得分
s
n
u
l
l
=
S
⋅
C
+
E
⋅
C
s_{null}=S\cdot C+E\cdot C
snull=S⋅C+E⋅C和最优的有答案得分
s
^
i
,
j
=
m
a
x
j
≥
i
S
⋅
T
i
+
E
⋅
T
j
\hat{s}_{i,j}=max_{j\geq i}S\cdot T_{i}+E\cdot T_{j}
s^i,j=maxj≥iS⋅Ti+E⋅Tj。当
s
^
i
,
j
>
s
n
u
l
l
+
τ
\hat{s}_{i,j}>s_{null}+\tau
s^i,j>snull+τ时,我们预测这是一个有答案的问题,这里的
τ
\tau
τ用来在dev set上选择最优的
F
1
F1
F1。下图展示了BERT在SQuAD v2.0上的效果:
- SWAG
微调时BERT的我们为BERT构建4个输入序列,每一个是所给的句子(句子A)和一个可能的延续(句子B)。然后引入一个向量,该向量和每一个输入对应的[CLS]的embedding的点积再通过一个
s
o
f
t
m
a
x
softmax
softmax层来得到每个选择的得分。下图展示了BERT在SWAG上的效果:
















 2567
2567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









