






STRUCTBERT:将语言结构纳入深度语言理解的预训练中
Wei Wang, Bin Bi, Ming Yan, Chen Wu, Zuyi Bao, Jiangnan Xia, Liwei Peng, Luo Si Alibaba Group Inc. {hebian.ww,b.bi,ym119608,wuchen.wc,zuyi.bzy,jiangnan.xjn,liwei.peng,luo.si}@alibaba-inc.com
0、摘要
最近,预训练语言模型 BERT(及其鲁棒优化版本 RoBERTa)在自然语言理解(NLU)领域引起了广泛关注,并在各种 NLU 任务中取得了最先进的准确度,例如 情感分类、自然语言推理、语义文本相似度和问答。 受 Elman [8] 线性化探索工作的启发,我们通过将语言结构纳入预训练,将 BERT 扩展到一个新模型 StructBERT。 具体来说,我们使用两个辅助任务对 StructBERT 进行预训练,以充分利用单词和句子的顺序,分别在单词和句子级别利用语言结构。 因此,新模型适应了下游任务所需的不同语言理解水平。
具有结构预训练的 StructBERT 在各种下游任务上给出了令人惊讶的良好实证结果,包括将 GLUE 基准测试中的最新技术推至 89.0(优于所有已发布的模型),SQuAD v1.1 上的 F1 分数 问题回答为 93.0,SNLI 的准确率为 91.7。
2、介绍
预训练语言模型 (LM) 是许多自然语言理解 (NLU) 任务的关键组成部分,例如语义文本相似性 [4]、问答 [21] 和情感分类 [25]。 为了获得可靠的语言表示,神经语言模型被设计为通过自我监督学习来定义文本中单词序列的联合概率函数。 不同于传统的词特定嵌入,其中每个标记都被分配一个全局表示,最近的工作,如 Cove [16]、ELMo [18]、GPT [20] 和 BERT [6],从语言模型中导出上下文词向量 在大型文本语料库上训练。 这些模型已被证明对许多下游 NLU 任务有效。
在上下文相关的语言模型中,BERT(及其鲁棒优化版本 RoBERTa [15])席卷了 NLP 世界。 它旨在通过联合调节所有层中的左右上下文来预训练双向表示,并通过仅通过上下文预测掩码词来对表示进行建模。 然而,它并没有充分利用底层语言结构。
根据 Elman [8] 的研究,循环神经网络被证明对简单句子中词序的规律性很敏感。 由于语言流畅性是由单词和句子的顺序决定的,因此找到一组单词和句子的最佳排列是许多 NLP 任务中的一个基本问题,例如机器翻译和 NLU [9]。 最近,词序被视为仅基于语言模型的基于 LM 的线性化 [24]。 Schmaltz 表明,即使没有任何明确的句法信息,具有长短期记忆 [11] 单元的循环神经网络语言模型 [17] 也能有效地进行词序排序。
在本文中,我们介绍了一种新型的上下文表示,StructBERT,它通过提出两种新颖的线性化策略将语言结构纳入 BERT 预训练。 具体来说,除了现有的掩蔽策略外,StructBERT 还通过利用结构信息扩展了 BERT:词级排序和句子级排序。 我们分别在句内结构和句间结构上使用两个新的结构目标来增强模型预训练。 通过这种方式,语言方面 [8] 在预训练过程中被明确捕获。通过结构化预训练,StructBERT 编码了上下文表示中单词和句子之间的依赖关系,从而为模型提供了更好的泛化性和适应性。
StructBERT 在各种 NLU 任务上显着提高了最先进的结果,包括 GLUE 基准测试 [27]、SNLI 数据集 [3] 和 SQuAD v1.1 问答任务 [21]。 所有这些实验结果清楚地证明了 StructBERT 在语言理解方面的卓越有效性和泛化能力。
我们做出以下主要贡献:
- 我们提出了新的结构预训练,通过结合单词结构目标和句子结构目标来扩展 BERT,以在上下文表示中利用语言结构。 这使 StructBERT 能够通过强制它重建单词和句子的正确顺序以进行正确预测来显式地建模语言结构。
- StructBERT 在广泛的 NLU 任务上明显优于所有已发布的最先进模型。 该模型扩展了 BERT 的优势,并提升了许多语言理解应用程序的性能,例如语义文本相似性、情感分析、文本蕴含和问答。
2、StructBERT预训练
StructBERT 建立在 BERT 架构之上,该架构使用多层双向 Transformer 网络 [26]。 给定单个文本句子或一对文本句子,BERT 将它们打包成一个标记序列,并为每个标记学习上下文向量表示。 每个输入标记都基于单词、位置和它所属的文本段来表示。 接下来,输入向量被送入多层双向 Transformer 块堆栈,该块使用自注意力通过考虑整个输入序列来计算文本表示。
原始的 BERT 引入了两个无监督预测任务来预训练模型:即掩码 LM 任务和下一句预测任务。 与原始 BERT 不同的是,我们的 StructBERT 通过在单词掩码后打乱一定数量的标记并预测正确的顺序来增强掩码 LM 任务的能力。 此外,为了更好地理解句子之间的关系,StructBERT 随机交换句子顺序并预测下一个句子和前一个句子作为新的句子预测任务。 通过这种方式,新模型不仅明确地捕获了每个句子中的细粒度词结构,而且还以双向的方式正确地对句间结构进行了建模。 一旦使用这两个辅助任务对 StructBERT 语言模型进行了预训练,我们就可以针对各种下游任务针对特定于任务的数据对其进行微调。
2.1、输入表示
每个输入 x 都是一个单词标记序列,可以是单个句子,也可以是打包在一起的一对句子。 输入表示遵循 BERT [6] 中使用的表示。 对于每个输入标记 ti,其向量表示 xi 是通过将相应的标记嵌入、位置嵌入和片段嵌入相加来计算的。 我们总是添加一个特殊的分类嵌入([CLS])作为每个序列的第一个标记,并在每个片段的末尾添加一个特殊的序列结束([SEP])标记。 WordPiece [30] 将文本标记为子词单元,并学习绝对位置嵌入,支持的序列长度高达 512 个标记。 此外,段嵌入用于区分一对句子,就像在 BERT 中一样。
2.2、Transformer编码器
我们使用多层双向 Transformer 编码器 [26] 来编码输入表示的上下文信息。 给定输入向量
X
=
{
x
i
}
i
=
1
N
X=\{x_i\}_{i=1}^N
X={xi}i=1N,使用 L 层 Transformer 将输入编码为:
H
l
=
T
r
a
n
s
f
o
r
m
e
r
l
(
H
l
−
1
)
(1)
H^l=Transformer_l(H^{l-1})\tag{1}
Hl=Transformerl(Hl−1)(1)
其中
l
∈
[
1
,
L
]
,
H
0
=
X
l\in[1,L],H^0=X
l∈[1,L],H0=X和
H
L
=
[
h
1
L
,
⋯
,
h
N
L
]
H^L=[h_1^L,\cdots,h_N^L]
HL=[h1L,⋯,hNL]。 我们使用隐藏向量
h
i
L
h_i^L
hiL 作为输入标记
t
i
t_i
ti的上下文表示。
2.3、预训练目标
为了充分利用语言中丰富的句内和句间结构,我们在两个方面扩展了原始 BERT 的预训练目标:1) word structural objective(主要针对单句任务),2) 句子结构目标(主要针对句对任务)。 我们在统一模型中将这两个辅助目标与原始掩码 LM 目标一起预训练,以利用固有的语言结构。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yY3y4WMd-1681990512163)(./assets/image-20230420185845932.png)]](https://img-blog.csdnimg.cn/0a969c8bce8a4970b03bbeae44d9209b.png)
(a) 单词结构目标 (b) 句子结构目标
图 1:两个新的预训练目标的图示
2.3.1、单词结构目标
尽管在各种 NLU 任务中取得了成功,但原始 BERT 无法显式地建模自然语言中单词的顺序和高阶依赖性。 给定一个句子中随机顺序的一组单词,理想情况下,一个好的语言模型应该能够通过重建这些单词的正确顺序来恢复这个句子。 为了在 StructBERT 中实现这一想法,我们用一个新的词结构目标来补充 BERT 的训练目标,该目标赋予模型重建一定数量的有意打乱的词标记的正确顺序的能力。 这个新词目标与 BERT 的原始掩码 LM 目标联合训练。
图 1(a) 说明了联合训练新词目标和掩蔽 LM 目标的过程。 在每个输入序列中,我们首先随机屏蔽所有标记的 15%,就像在 BERT [6] 中所做的那样。 双向 Transformer 编码器计算出的屏蔽标记的相应输出向量 h i L h_i^L hiL被馈送到 softmax 分类器以预测原始标记。
接下来,新词目标开始发挥作用,将词序考虑在内。 考虑到代币洗牌的随机性,目标这个词等同于最大化将每个洗牌后的代币放在正确位置的可能性。 更正式地说,这个目标可以表述为:
a
r
g
max
θ
∑
log
P
(
p
o
s
1
=
t
2
,
p
o
s
1
=
t
2
,
⋯
,
p
o
s
K
=
t
K
∣
t
1
,
t
2
,
⋯
,
t
K
,
θ
)
(2)
arg\max_{\theta}\sum \log P(pos_1=t_2,pos_1=t_2,\cdots,pos_K=t_K|t_1,t_2,\cdots,t_K,\theta)\tag{2}
argθmax∑logP(pos1=t2,pos1=t2,⋯,posK=tK∣t1,t2,⋯,tK,θ)(2)
其中 θ 表示 StructBERT 的可训练参数集,K 表示每个打乱的子序列的长度。 从技术上讲,较大的 K 会迫使模型能够重建更长的序列,同时注入更多受干扰的输入。 相反,当 K 越小,模型得到的未受干扰序列越多,而恢复长序列的能力越差。 我们决定使用三元组(即 K = 3)进行子序列改组,以平衡模型的语言可重构性和鲁棒性。 具体来说,如图 1(a)所示,我们从未屏蔽的标记中随机选择一定比例的 trigrams,并将每个 trigrams 中的三个单词(例如图中的
t
2
,
t
3
,
和
t
4
t_2,t_3,和t_4
t2,t3,和t4)打乱。 由双向 Transformer 编码器计算出的打乱标记的输出向量随后被送入 softmax 分类器以预测原始标记。 在具有相同权重的统一预训练模型中,新词目标与掩码 LM 目标共同学习。
2.3.1、句子结构目标
下一句预测任务对于原始BERT模型来说被认为是容易的(BERT的预测准确率在这个任务中可以轻松达到97%-98%[6])。 因此,我们通过预测下一个句子和上一个句子来扩展句子预测任务,以使预训练的语言模型以双向方式了解句子的顺序。
如图 1(b)所示,给定一对句子( S 1 , S 2 S_1,S_2 S1,S2)作为输入,我们预测 S 2 S_2 S2是 S 1 S_1 S1之后的下一个句子,还是 S 1 S_1 S1之前的前一个句子,或者来自不同文档的随机句子。 具体来说,对于句子 S 1 S_1 S1, 1 3 \frac{1}{3} 31的时间我们选择 S 1 S_1 S1后面的text span作为第二个句子 S 2 S_2 S2, 1 3 \frac{1}{3} 31的时间选择S1前面的前一个句子, 1 3 \frac{1}{3} 31的时间随机抽取一个句子 来自其他文件的文件被用作 S 2 S_2 S2。 这两个句子连接在一起成为一个输入序列,中间有分隔符 [SEP],就像在 BERT 中所做的那样。 我们通过获取与第一个标记 [CLS] 对应的隐藏状态来汇集模型输出,并将 [CLS] 的编码向量输入 softmax 分类器以进行三类预测。
2.4、预训练设置
训练目标函数是词结构目标和句子结构目标的线性组合。 对于掩蔽 LM 目标,我们遵循与 BERT [6] 中相同的掩蔽率和设置。 选择 5% 的 trigrams 进行随机洗牌。
我们使用来自英语维基百科(2,500M 单词)和 BookCorpus [35] 的文档作为预训练数据,遵循 [6] 中的预处理和 WordPiece 标记化。 输入序列的最大长度设置为 512。
我们以 1e-4 的学习率运行 Adam,β1 = 0.9,β2 = 0.999,L2 权重衰减 0.01,学习率预热总步骤的前 10% ,以及学习率的线性衰减。
我们为每一层设置 0.1 的丢失概率。 gelu 激活 [10] 与 GPT [20] 中一样使用。 我们将 Transformer 块层的数量表示为 L,将隐藏向量的大小表示为 H,并将自注意力头的数量表示为 A。按照 BERT 的做法,我们主要报告两种模型大小的实验结果:
StructBERTBase:L = 12, H = 768, A = 12, Number of parameters= 110M
StructBERTLarge: L = 24, H = 1024, A = 16, Number of parameters= 340M
StructBERT 的预训练是在一个由 64 个节点组成的分布式计算集群上进行的 Telsa V100 GPU 卡。 对于 StructBERTBase,我们运行了 40 个 epoch 的预训练过程,耗时约 38 小时,而 StructBERTLarge 的训练耗时约 7 天完成。
3、实验
在本节中,我们报告了 StructBERT 在各种下游任务上的结果,包括通用语言理解评估(GLUE 基准)、斯坦福自然语言推理(SNLI 语料库)和抽取式问答(SQuAD v1.1)。
遵循 BERT 的做法,在对下游任务进行微调时,我们对以下几组参数进行了网格搜索或穷举搜索(取决于数据大小),并选择了在开发集上表现最好的模型。 所有其他参数与预训练中的参数保持一致:
批量大小:16、24、32; 学习率:2e-5、3e-5、5e-5; 纪元数:2、3; 辍学率:0.05、0.1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x7Gvt86v-1681990512164)(./assets/image-20230420190947667.png)]](https://img-blog.csdnimg.cn/d9befb6d97974688853c7cc65c4333d4.png)
表 1:已发布模型在 GLUE 测试集上的结果,由 GLUE 评估服务器评分。 每个任务下方的数字表示训练示例的数量。 最先进的结果以粗体显示。 所有结果均来自 https://gluebenchmark.com/leaderboard(StructBERT 以不同的模型名称 ALICE 提交)。
3.1、通用语言理解
3.1.1、GLUE基准
通用语言理解评估 (GLUE) 基准 [27] 是九个 NLU 任务的集合,涵盖文本蕴含(RTE [1] 和 MNLI [29])、问答蕴含(QNLI [27])、释义(MRPC [ 7]), 问题
释义 (QQP【1】)、文本相似性 (STS-B [4])、情感 (SST-2 [25])、语言可接受性 (CoLA [28]) 和 Winograd Schema (WNLI [13])。
在 GLUE 基准测试中,鉴于 MRPC/RTE/STS-B 与 MNLI 的相似性,我们在针对相应任务对 MRPC/RTE/STS-B 数据进行训练之前,在 MNLI 上对 StructBERT 进行了微调。 这遵循 [19] 中介绍的两阶段迁移学习 STILT。 对于所有其他任务(即 RTE、QNLI、QQP、SST-2、CoLA 和 MNLI),我们仅针对每个任务的域内数据对 StructBERT 进行微调。
表 1 显示了从官方基准评估服务器获得的 GLUE 测试集上已发布模型的结果。 我们的 StructBERTLarge 集成在平均得分上压制了所有已发布的模型(不包括 RoBERTa 集成和 XLNet 集成),并在九项任务中的六项中在这些模型中表现最好。 在最流行的 MNLI 任务中,我们的 StructBERTLarge 单一模型将最佳结果提高了 0.3%/0.5%,因为我们仅在其域内数据上对 MNLI 进行了微调,这种改进完全归功于我们新的训练目标。 在 CoLA 上观察到比 BERT 最显着的改进(4.8%),这可能是由于词序任务和语法纠错任务之间的强相关性。 在 SST-2 任务中,我们的模型比 BERT 有所改进,但性能不如 MT-DNN,这表明基于单句的情感分析从词结构目标和句子结构目标中受益较少。
通过对大型语料库进行预训练,XLNet 集成和 RoBERTa 集成优于所有已发布的模型,包括我们的 StructBERTLarge 集成。 为了利用 RoBERTa 训练的大数据,我们继续使用已发布的 RoBERTa 模型中的两个新目标进行预训练,名为 StructBERTRoBERTa。 在提交论文时,我们以不同名称 ALICE 提交的 StructBERTRoBERTa 集成在排行榜上取得了包括 RoBERTa 在内的所有已发布模型中的最佳性能,创造了 89.0% 的新的最先进结果 平均 GLUE 分数。 它表明除了 BERT 之外,所提出的目标还能够改进语言模型。
【1】https://data.quora.com/First-Quora-Dataset-Release-Question-Pairs
3.1.2、SNLI
自然语言推理(NLI)是自然语言理解中的重要任务之一。 该任务的目标是测试模型推理两个句子之间语义关系的能力。 为了在 NLI 任务上表现良好,模型需要捕捉句子的语义,从而推断出一对句子之间的关系:蕴含、矛盾或中性。
我们在最广泛使用的 NLI 数据集上评估了我们的模型:斯坦福自然语言推理 (SNLI) 语料库 [3],它由训练/开发/测试集中的 549,367/9,842/9,824 个前提假设对和指示它们关系的目标标签组成 . 我们对参数集进行了网格搜索,并选择了在开发集上表现最好的模型。

表 2 显示了我们模型与其他已发布模型在 SNLI 数据集上的结果。 StructBERT 在 SNLI 上优于所有现有系统,创造了 91.7% 的新的最先进结果,这相当于比之前的最先进模型 SJRC 提高了 0.4%,比 BERT 提高了 0.9%。 由于我们模型的网络架构与 BERT 的网络架构相同,因此这种改进完全归功于新的预训练目标,这证明了所提出的单词预测和句子预测任务的有效性。
3.2、提取式问答
SQuAD v1.1 是一个流行的机器阅读理解数据集,由人群工作者在 536 篇维基百科文章 [21] 上创建的 100,000 多个问题组成。 该任务的目标是从给定问题的相应段落中提取正确的答案范围。
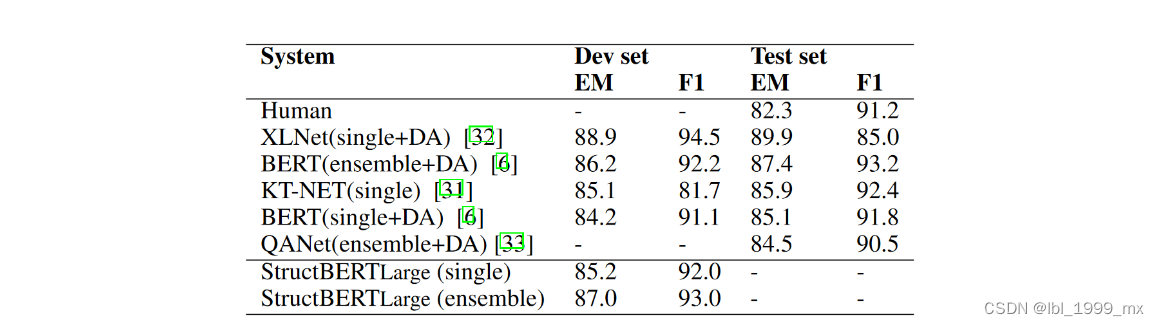
表3:SQuAD 结果。 StructBERTLarge 集成是 10x 系统,它使用不同的预训练检查点和微调种子。
我们在 SQuAD 数据集上对我们的 StructBERT 语言模型进行了 3 个 epoch 的微调,并将结果与官方排行榜 【2】上的最先进方法进行了比较,如表 3 所示。我们可以看到,即使没有任何额外的 数据增强 (DA) 技术,所提出的 StructBERT 模型优于除开发集上的 XLNet+DA 之外的所有已发布模型【3】。 在预训练期间使用数据增强和大型语料库,XLNet+DA 优于我们未使用数据增强或大型预训练语料库的 StructBERT。 它证明了所提出的预训练 StructBERT 在为抽取式问答建模问题-段落关系方面的有效性。 结合单词和句子结构显着提高了这个细粒度答案提取任务的理解能力。
【2】https://rajpurkar.github.io/SQuAD-explorer/
【3】We have submitted the model under the name of ALICE to the SQuAD v1.1 CodaLab for evaluation on the test set. However, due to crash of the Codalab evaluation server, we have not got our test result back yet at the time of paper submission. We will update the result once it is announced.
3.3、不同结构目标的影响
我们已经证明了所提出的模型在各种下游任务上的强大实证结果。 在 StructBERT 预训练中,两个新的结构预测任务是最重要的组成部分。 因此,我们通过一次从预训练中删除一个结构目标来进行消融研究,以检查这两个结构目标如何影响各种下游任务的性能。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z05COXiH-1681990512165)(./assets/image-20230420192335202.png)]](https://img-blog.csdnimg.cn/994efd273f894bc58d9709f844144281.png)
表 4:使用 StructBERTBase 架构对预训练目标进行消融。 每个结果都是使用不同随机种子运行 8 次的平均分数(MNLI 准确率是匹配和不匹配设置的平均分数)。
结果如表 4 所示。从表中我们可以看出:(1)除了 SNLI 任务中的单词结构目标外,这两个结构目标对大多数下游任务都至关重要。 从预训练中删除任何单词或句子目标总是会导致下游任务的性能下降。 具有结构预训练的 StructBERT 模型始终优于原始 BERT 模型,这表明所提出的结构目标的有效性。 (2) 对于 MNLI、SNLI、QQP 和 SQuAD 等句对任务,结合句结构目标显着提高了性能。 它展示了通过预训练学习的句间结构在理解下游任务的句子之间的关系方面的效果。 (3) 对于CoLA、SST-2等单句任务,word structural objective发挥了最重要的作用。 特别是在与语法纠错相关的 CoLA 任务中,提高了 5% 以上。 预训练中重构词序的能力帮助模型更好地判断单个句子的可接受性。
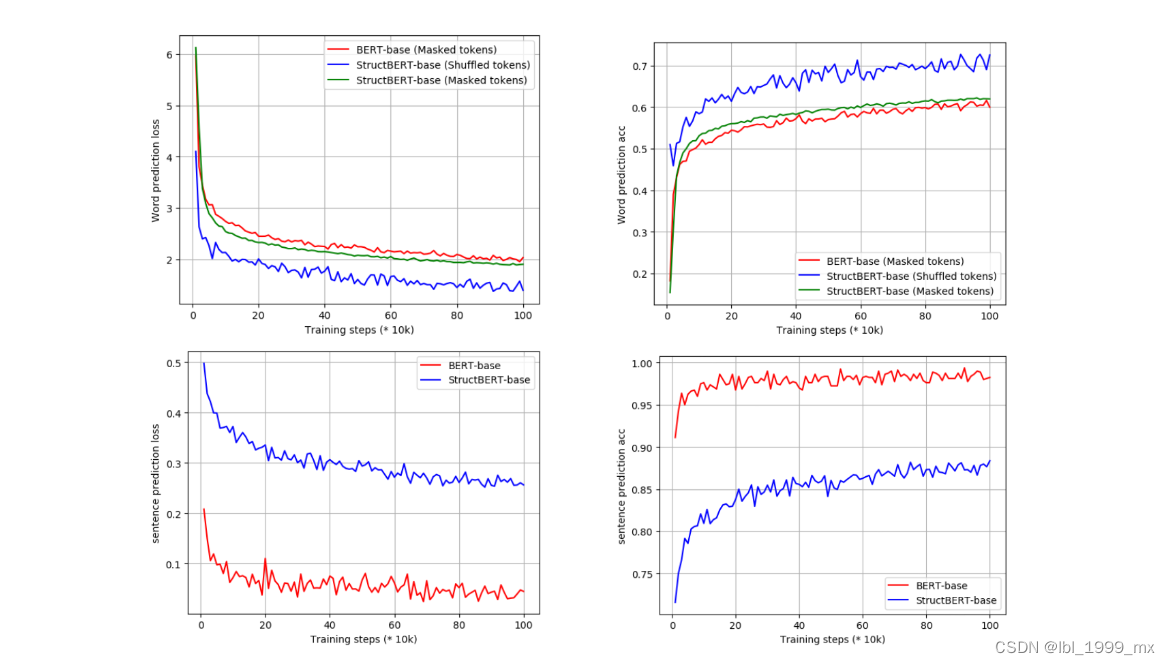
图2:单词和句子预测在预训练步骤上的损失和准确性
我们还研究了自我监督预训练期间两个结构目标的影响。 图 2 说明了 StructBERTBase 和 BERTBase 的预训练步骤数的单词和句子预测的损失和准确性。 从上面的两个子图可以看出,与 BERT 相比,StructBERT 的词结构目标中增强的混洗标记预测对掩码标记预测的损失和准确性影响很小。 另一方面,整合更简单的混洗标记预测任务(更低的损失和更高的准确性)为 StructBERT 提供了单词重新排序的能力。 相比之下,StructBERT 中新的句子结构目标导致比 BERT 中更具挑战性的预测任务,如底部的两个图所示。 这个新的预训练目标使 StructBERT 能够利用句间结构,这有利于句子对下游任务。
4、相关工作
4.1、语境化语言表示
一个词可以有不同的语义,这取决于它的上下文。 上下文化词表示被认为是现代 NLP 研究的重要组成部分,最近出现了各种预训练语言模型 [16、18、20、6]。 ELMo [18] 基于长短期记忆网络 (LSTM) 学习两个单向 LM。 前向 LM 从左到右读取文本,而后向 LM 从右到左编码文本。 遵循 ELMo 的类似想法,OpenAI GPT [20] 通过在大量自由文本语料库上进行训练,将无监督语言模型扩展到更大的规模。 与 ELMo 不同,它建立在多层 Transformer [26] 解码器之上,并使用从左到右的 Transformer 逐字预测文本序列。
相比之下,BERT [6](及其鲁棒优化版本 RoBERTa [15])采用双向 Transformer 编码器来融合左右上下文,并引入了两个新颖的预训练任务以更好地理解语言。 我们的 LM 基于 BERT 的架构,并通过将单词和句子结构引入预训练任务中以进一步扩展它,以实现深度语言理解。
4.2、单词和句子排序
线性化的任务旨在恢复打乱句子的原始顺序 [24]。 关于 LSTM 是否正在捕获句法现象线性化的更大讨论的一部分,在最近的一系列研究中被标准化为一种有助于隔离文本到文本生成 [34] 模型性能的方法。 最近,Transformers 已成为学习语言潜在结构的强大架构。 例如,Bidirectional Transformers (BERT) 降低了语言建模任务的复杂性。 我们通过将 BERT 应用于词序任务而不使用任何显式句法方法来重新审视 Elman 的问题,并发现预训练的语言模型对于具有线性化的各种下游任务是有效的。
许多重要的下游任务,如 STS 和 NLI [27],都是基于理解两个文本句子之间的关系,而语言建模并没有直接捕捉到这种关系。 虽然 BERT [6] 预训练二值化下一句预测任务以理解句子关系,但我们更进一步,将其视为句子排序任务。 句子排序的目标是以清晰一致的方式将一组句子排列成连贯的文本,这可以看作是一个排序问题[5]。 该任务是一般性的但具有挑战性,并且 once 对于自然语言生成尤为重要 [23]。 文本应根据以下属性进行组织:修辞连贯性、主题相关性、时间顺序和因果关系。 在这项工作中,我们关注可以说是序列最基本的特征:它们的顺序。 大多数关于句子排序的先前工作都是下游任务研究的一部分,例如多文档摘要 [2]。 我们在语言建模的背景下将这个问题重新审视为一个新的句子预测任务。
5、结论
在本文中,我们提出了新颖的结构预训练,将单词和句子结构结合到 BERT 预训练中。 引入词结构目标和句子结构目标作为两个新的预训练任务,以深入理解不同粒度的自然语言。 实验结果表明,新的 StructBERT 模型可以在各种下游任务中获得新的最先进的结果,包括流行的 GLUE 基准、SNLI 语料库和 SQuAD v1.1 问答。
6、参考文献
[1] Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. The fifth pascal recognizing textual entailment challenge. In TAC, 2009.
[2] Danushka Bollegala, Naoaki Okazaki, and Mitsuru Ishizuka. A bottom-up approach to sentence ordering for multi-document summarization. Information processing & management, 46(1):89–109, 2010.
[3] Samuel R Bowman, Gabor Angeli, Christopher Potts, and Christopher D Manning. A large annotated corpus for learning natural language inference. arXiv preprint arXiv:1508.05326, 2015.
[4] Daniel Cer, Mona Diab, Eneko Agirre, Inigo Lopez-Gazpio, and Lucia Specia. Semeval-2017 task 1: Semantic textual similarity-multilingual and cross-lingual focused evaluation. arXiv preprint arXiv:1708.00055, 2017.
[5] Xinchi Chen, Xipeng Qiu, and Xuanjing Huang. Neural sentence ordering. arXiv preprint arXiv:1607.06952, 2016.
[6] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
[7] William B Dolan and Chris Brockett. Automatically constructing a corpus of sentential paraphrases. In Proceedings of the Third International Workshop on Paraphrasing (IWP2005), 2005.
[8] Jeffrey L Elman. Finding structure in time. Cognitive science, 14(2):179–211, 1990.
[9] Eva Hasler, Felix Stahlberg, Marcus Tomalin, Adri de Gispert, and Bill Byrne. A comparison of neural models for word ordering. arXiv preprint arXiv:1708.01809, 2017.
[10] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
[11] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
[12] Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, Luke Zettlemoyer, and Omer Levy. Spanbert: Improving pre-training by representing and predicting spans. arXiv preprint arXiv:1907.10529, 2019.
[13] Hector Levesque, Ernest Davis, and Leora Morgenstern. The winograd schema challenge. In Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning, 2012.
[14] Xiaodong Liu, Pengcheng He, Weizhu Chen, and Jianfeng Gao. Multi-task deep neural networks for natural language understanding. arXiv preprint arXiv:1901.11504, 2019.
[15] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
[16] Bryan McCann, James Bradbury, Caiming Xiong, and Richard Socher. Learned in translation: Contextualized word vectors. In Advances in Neural Information Processing Systems, pages 6294–6305, 2017.
[17] Tomáš Mikolov, Martin Karafiát, Lukáš Burget, Jan ˇ Cernock ` y, and Sanjeev Khudanpur. Recurrent neural network based language model. In Eleventh annual conference of the international speech communication association, 2010.
[18] Matthew E Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations. arXiv preprint arXiv:1802.05365, 2018.
[19] Jason Phang, Thibault Févry, and Samuel R Bowman. Sentence encoders on stilts: Supplementary training on intermediate labeled-data tasks. arXiv preprint arXiv:1811.01088, 2018.
[20] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. URL https://s3-us-west-2. amazonaws. com/openai-assets/researchcovers/languageunsupervised/language understanding paper. pdf, 2018.
[21] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250, 2016.
[22] Alexander Ratner, Stephen H Bach, Henry Ehrenberg, Jason Fries, Sen Wu, and Christopher Ré. Snorkel: Rapid training data creation with weak supervision. Proceedings of the VLDB Endowment, 11(3):269–282, 2017.
[23] Ehud Reiter and Robert Dale. Building applied natural language generation systems. Natural Language Engineering, 3(1):57–87, 1997.
[24] Allen Schmaltz, Alexander M Rush, and Stuart M Shieber. Word ordering without syntax. arXiv preprint arXiv:1604.08633, 2016.
[25] Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pages 1631–1642, 2013.
[26] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
[27] Alex Wang, Amapreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461, 2018.
[28] Alex Warstadt, Amanpreet Singh, and Samuel R Bowman. Neural network acceptability judgments. arXiv preprint arXiv:1805.12471, 2018.
[29] Adina Williams, Nikita Nangia, and Samuel R Bowman. A broad-coverage challenge corpus for sentence understanding through inference. arXiv preprint arXiv:1704.05426, 2017.
[30] Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144, 2016.
[31] An Yang, Quan Wang, Jing Liu, Kai Liu, Yajuan Lyu, Hua Wu, Qiaoqiao She, and Sujian Li. Enhancing pre-trained language representations with rich knowledge for machine reading comprehension. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2346–2357, 2019.
[32] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V Le. Xlnet: Generalized autoregressive pretraining for language understanding. arXiv preprint arXiv:1906.08237, 2019.
[33] Adams Wei Yu, David Dohan, Minh-Thang Luong, Rui Zhao, Kai Chen, Mohammad Norouzi, and Quoc V Le. Qanet: Combining local convolution with global self-attention for reading comprehension. arXiv preprint arXiv:1804.09541, 2018.
[34] Yue Zhang and Stephen Clark. Discriminative syntax-based word ordering for text generation. Computational linguistics, 41(3):503–538, 2015.
[35] Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Aligning books and movies: Towards story-like visual explanations by watching movies an














 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









