






写在前面
大家好,我是刘聪NLP。
今天给大家带来一篇acl2022通过低频词典增强预训练模型表征论文-Dict-BERT,全名为《Dict-BERT: Enhancing Language Model Pre-training with Dictionary》
paper地址:https://aclanthology.org/2022.findings-acl.150.pdf
模型
Dict-BERT为了解决BERT模型对语料中低频词(rare words)的不敏感性,通过在预训练中加入低频词词典&对应低频词定义来增强训练语言模型,并且引入了针对低频词的词语级别和句子级别的两个特殊任务。
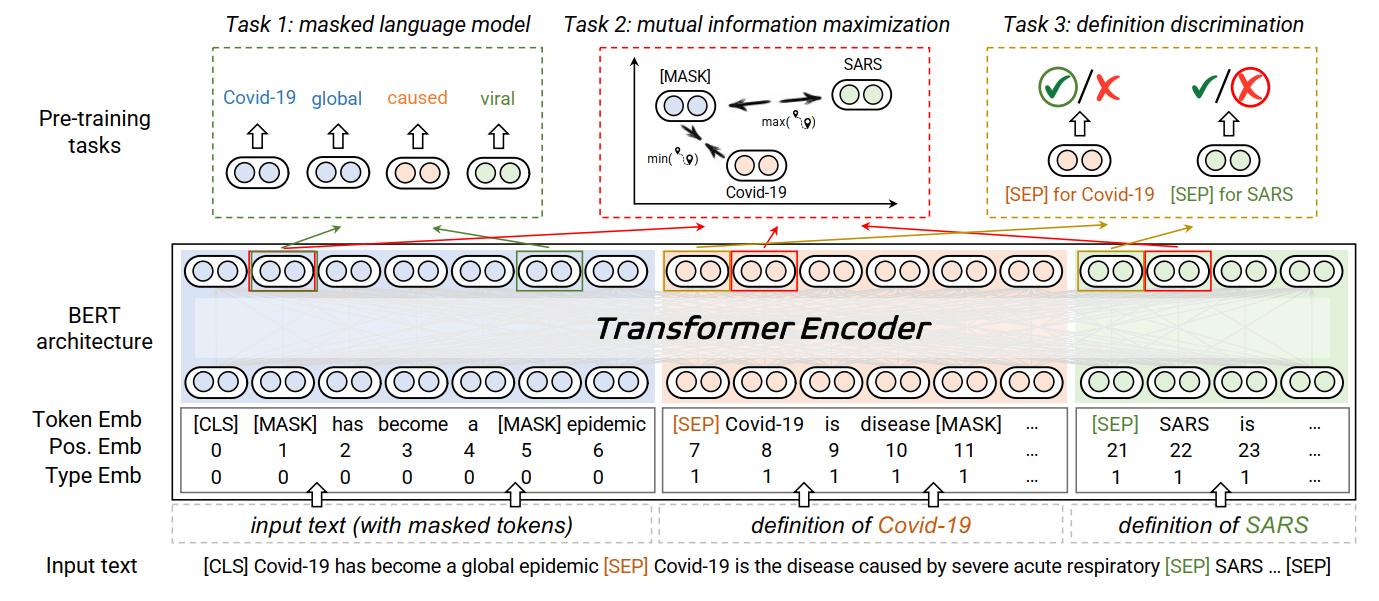
如上图所示:
-
Task1(MLM):原始预训练语言模型任务;
-
Task2(MIM):针对低频词的词语级别的对比学习任务,是被[mask]的低频词,距离正例中的低频词比负例中的噪声词更近;
-
Task3(DD):针对低频词的句子级别的判别任务,是判断句子是低频词的定义还是噪声词的定义。
预训练时,三个loss结合进行联合训练。
在finetuning阶段,为了使用低频词词典,引入了Knowledge-visible Attention,防止引入的低频词定义文本对原始文本产生干扰,如下图所示,

结果如下表所示: 领域自适应预训练,结果如下表所示: 针对不同低频词率和Knowledge注意力的效果,结果如下表所示:
总结
Dict-BERT的一个优点是在下游中可以动态调整低频词的词汇量,但是在真实场景中如何获取低频词的定义解释是一个问题。
整理不易,请多多点赞,关注,有问题的朋友也欢迎加我微信「logCong」、公众号「NLP工作站」、知乎「刘聪NLP」私聊,交个朋友吧,一起学习,一起进步。
我们的口号是“生命不止,学习不停”。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









