









把之前做过的校园新闻小项目拆开来,简单分析每个部分的功能,希望能给感兴趣的童鞋一些借鉴和启发。纯手工打造,尊重原创,转载必究!
先聊聊爬虫的思想,想象你往Internet丢了一只贪婪但只会爬行的小虫子,从第一个根节点开始,它找到了网页,继而在这个网页里探寻更多的节点,把这些节点放到两个动态栈里,一个是存放已到过的节点,另一个存放已知的但还没到的节点。当到达新的节点时,先检测两个栈里是否已有这个节点,如果有则跳过,如果没有就重复上述过程,直到想去的节点全都去过了,就停止爬虫。
我的爬虫小程序结构如下:
用VS2010生成的类关系依赖图如下:
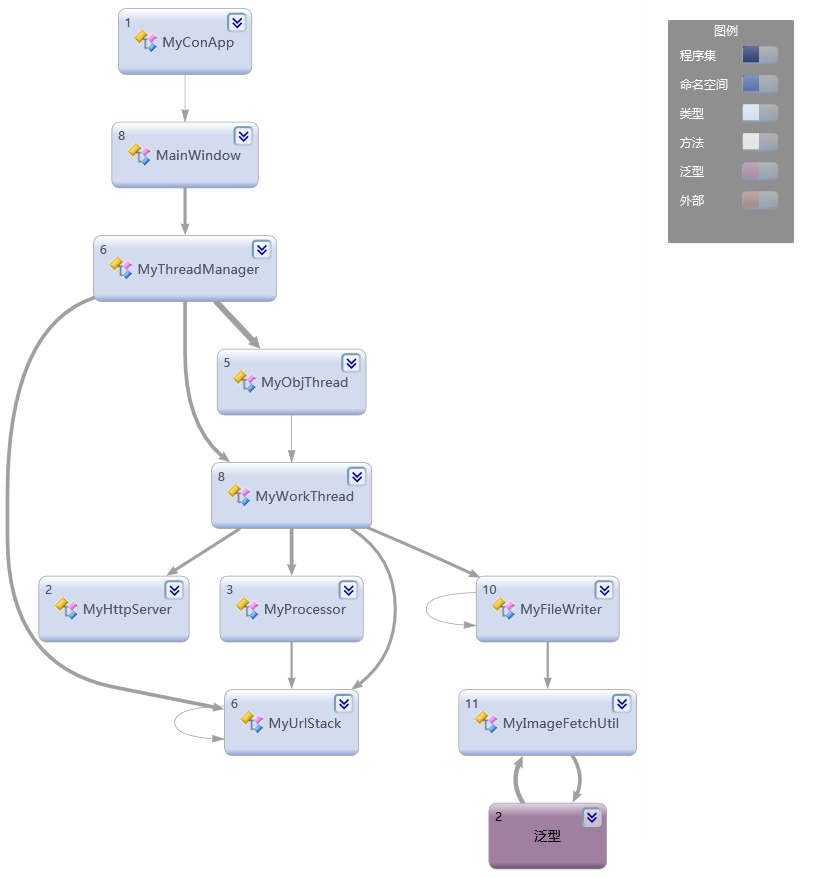
MyConApp是程序入口,MainWindow是窗体函数,主要是一些控件逻辑,这里接受用户输入的根节点(输入的网址也会被简单处理以规范化),有了根节点就开启了漫漫爬虫之旅,为了提高爬取更多网址的效率,采用多线程是必然,所以如何管理这些线程又是一个重要话题。但我们先暂且撇开这部分,理清楚在单线程的情况下,爬虫应该如何工作吧。
我们可以逆向分析,爬虫的结果是什么,文本和图片?这其实不是最原始的结果,文本内容是来自网页通过正则表达式匹配得到的所需内容,图片是通过图片标签获取到url重新向网络请求得到的,这些工作采用一个MyFileWriter来处理。在先前的博客里我讨论了在多生产者单消费者和多生产者多消费者如何选择的问题,在这个系统里,为了保证文件写入的顺序(多线程写入可能导致文本被多次写入而覆盖),我用了MyFileWriter单例模式。之后的图片上传和ID回传我就不多说了,因为采用了别人的图片服务器,不方便公开哈。
如何获取最原始的网页呢,只需要网页的url即可,由于本项目并不涉及cookie等模拟用户登录步骤,相对简单。一张网页里一般都有很多url,在存储网页内容之前就需要你检测此时的url是否是符合需求的。当然想要让爬取url和存储每个url对应网页的内容能保持速度一致,几乎是不可能的,而且我们还需要排除重复的url,所以需要专门写一个队列为url做维护(也可以用stack类型,不过用queue在逻辑上更容易被人类接受吧),而且在整个程序中url栈应该是全局唯一的,这由MyUrlStack来处理。
怎么获取url呢?c#有HttpWebRequest类非常符合网络爬虫的需求,封装在MyHttpServer,负责请求单个网页的类。获取到html网页内容后,又要用到正则表达式了,找到所有匹配。这里为了保证全局url栈的功能的纯净,特别是涉及到多线程的时候更需要保证对url栈操作(添加,删除)的并发性,我把从网页分析并获取更多url的操作单独分离出来写成了MyProcessor类。
理清单线程的具体工作后,我们就来分析一下如何管理多线程服务,主要涉及到3个类:
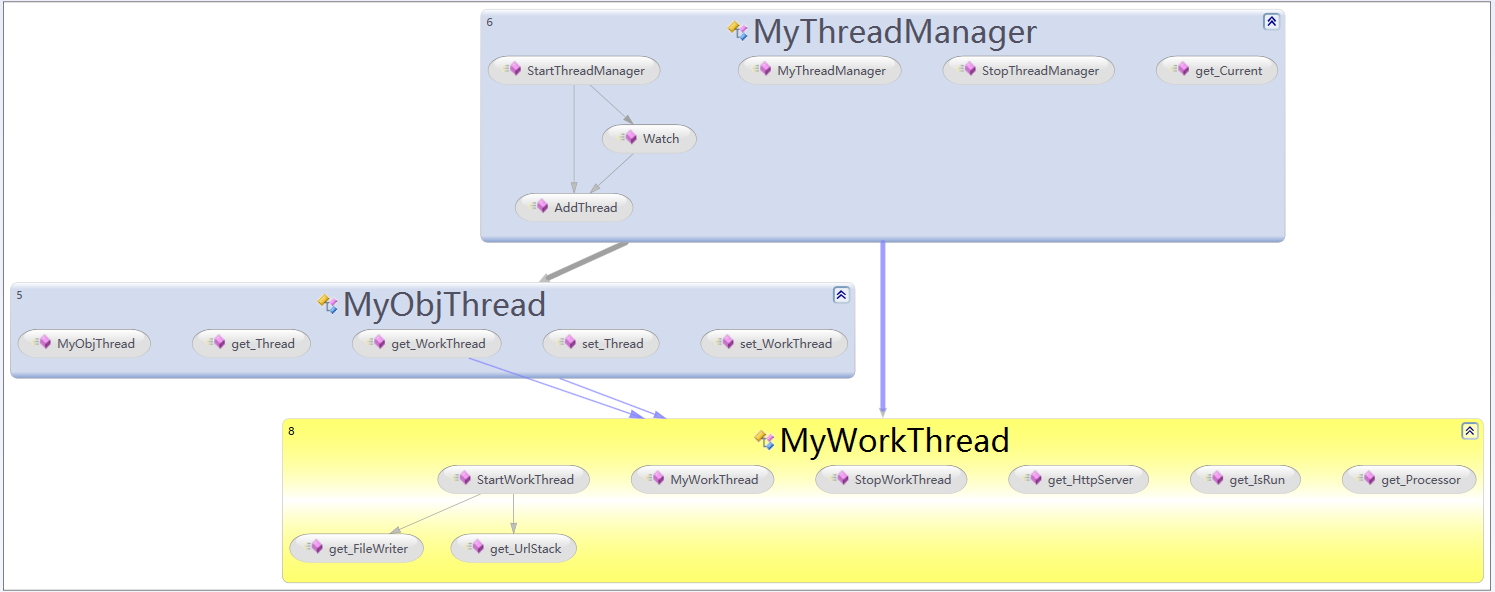
- 首先来看一下工作线程的代码,它封装了我们的单个线程需要做的事情和数据
/// <summary>
/// MyWorkThread是工作线程类,
/// 包括解析html的类对象,请求html的类对象,存储urls的实例,存储html新闻内容的类对象
/// </summary>
class MyWorkThread
{
private MyProcessor _processor = new MyProcessor();
internal MyProcessor Processor
{
get { return _processor; }
}
private MyHttpServer _httpserver = new MyHttpServer();
internal MyHttpServer HttpServer
{
get { return _httpserver; }
}
internal MyUrlStack UrlStack
{
get { return MyUrlStack.UrlStackInstance; }
}
internal MyFileWriter FileWriter
{
get { return MyFileWriter.MyFileWriteInstance; }
}
private bool _isRun = false;
internal bool IsRun
{
get { return _isRun; }
}
/// <summary>
/// 工作线程开始工作,
/// 从urlstack中取出url,读出html,存储html中的新闻,解析html中的urls添加到urlstack中
/// </summary>
public void StartWorkThread()
{
bool flag_isEmpty_firstTime = true;
try
{
this._isRun = true;
while (_isRun)
{
string url = this.UrlStack.Pop();
if (!string.IsNullOrEmpty(url))
{
string html = _httpserver.GetResponse(url);
if (!string.IsNullOrEmpty(html))
{
FileWriter.SaveElement(url, html);
_processor.AddUrl(_processor.GetLinks(html));
}
}
else
{
if (flag_isEmpty_firstTime)
{
flag_isEmpty_firstTime = false;
}
else
{
_isRun = false;
}
}
}
}
catch
{
Console.WriteLine("Error in MyWorkThread.StartWorkThread!");
}
}
/// <summary>
/// 停止工作线程
/// </summary>
public void StopWorkThread()
{
this._isRun = false;
}
}- 然后我们把上述工作逻辑和一个托管线程封装在一个线程类型里,这样在启动任何一个线程的时候都可以方便的控制单线程逻辑:
/// <summary>
/// MyObject类是一种线程类型
/// </summary>
class MyObjThread
{
//封装线程需要做的事情和数据
private MyWorkThread _workThread;
internal MyWorkThread WorkThread
{
get { return _workThread; }
set { _workThread = value; }
}
//托管的线程
private System.Threading.Thread _thread;
internal System.Threading.Thread Thread
{
get { return _thread; }
set { _thread = value; }
}
}- 最后,就是多线程的管理了,如何让这些自动启动新的线程,如何自动清理已经逻辑上结束或者terminated或者aborted的线程:
/// <summary>
/// MyThreadManager用于开启工作线程和监控线程,
/// 监控线程用于清除已死线程,更新线程list
/// </summary>
public class MyThreadManager
{
public int _maxThread = Convert.ToInt32(System.Configuration.ConfigurationManager.AppSettings["MaxCount"]);
internal List<MyObjThread> _list = new List<MyObjThread>();
private bool _isRun = false;
/// <summary>
/// 监控线程list里的线程存活死亡的主线程
/// </summary>
private System.Threading.Thread _watchThread = null;
public int Current
{
get { return MyUrlStack.UrlStackInstance.Count; }
}
public void StartThreadManager(string url)
{
try
{
MyUrlStack.UrlStackInstance.Push(url);
_isRun = true;
for (int i = 0; i < _maxThread; i++)
{
this.AddThread();
}
_watchThread = new System.Threading.Thread(Watch);
_watchThread.Start();
}
catch
{
Console.WriteLine("Errors in MyThreadManager.StartThreadManager!");
}
}
public void StopThreadManager()
{
try
{
_isRun = false;
_watchThread.Join();//阻塞调用线程,直到线程终止
foreach (MyObjThread obj in _list)
{
obj.WorkThread.StopWorkThread();
obj.Thread.Abort();//终止过程开始
obj.Thread.Join();//阻塞主(调用)线程,直到obj线程终止
}
_list.RemoveRange(0, _list.Count);
}
catch
{
Console.WriteLine("Errors in MyThreadManager.StopThreadManager!");
}
}
private void AddThread()
{
MyObjThread thread = new MyObjThread();
thread.WorkThread = new MyWorkThread();
//Thread 初始化参数ThreadStart类型(委托),它表示此线程开始执行时要调用的方法。
thread.Thread = new System.Threading.Thread(thread.WorkThread.StartWorkThread);
_list.Add(thread);
thread.Thread.Start();
}
/// <summary>
/// 删除已终止线程,更新线程列表
/// </summary>
private void Watch()
{
List<MyObjThread> _newList = new List<MyObjThread>();
while (_isRun)
{
try
{
//检测存活下来的线程,并保存
foreach (MyObjThread temp in _list)
{
if (temp.WorkThread.IsRun && temp.Thread.IsAlive)
{
_newList.Add(temp);
}
}
//更新list中的线程
this._list.RemoveRange(0, _list.Count);
_list.AddRange(_newList);
int _leftCount = _maxThread - _list.Count;
for (int i = 0; i < _leftCount; i++)
{
this.AddThread();
}
_newList.RemoveRange(0, _newList.Count);
}
catch
{
Console.WriteLine("Errors in MyObjThread.Watch!");
}
}
}
}好了,现在简单的爬虫程序就完成啦,快去喝杯咖啡,让他奔跑起来吧!















 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









