







 本文介绍了自动文档摘要评价中的两种主要方法:Edmundson和ROUGE。Edmundson方法通过句子重合率评估摘要质量,而ROUGE则利用n-gram、最长公共子序列等指标进行量化评估。
本文介绍了自动文档摘要评价中的两种主要方法:Edmundson和ROUGE。Edmundson方法通过句子重合率评估摘要质量,而ROUGE则利用n-gram、最长公共子序列等指标进行量化评估。
本人最近在做一个自动文档摘要相关的项目,研究了一下目前业界的一些评价方法,阅读了Chin-Yew Lin的《ROUGE: A Package for Automatic Evaluation of Summaries》的paper,也对应看了其他朋友整理的笔记,特整理此笔记供大家参考!
自动文档摘要评价方法大致分为两类:
(1)内部评价方法(Intrinsic
Methods)
在提供参考摘要的前提下,以参考摘要为基准评价系统摘要的质量。通常情况下,系统摘要与参考摘要越吻合,其质量越高。
(2)外部评价方法(Extrinsic Methods)
下面介绍两个比较简单的,也是在自动摘要评价以及自动文档摘要的相关国际评测中经常会被用到的两个内部评价方法:Edmundson和ROUGE。
(一)Edmundson
Edmundson评价方法属于内部评价方法,可以客观评估,就是通过比较机械文摘(自动文摘系统得到的文摘)与目标文摘的句子重合率(coselection
rate) 的高低来对系统摘要进行评价。也可以主观评估,就是由专家比较机械文摘与目标文摘所含的信息,然后给机械文摘一个等级评分。等级可以分为:完全不相似,基本相似,很相似,完全相似等。Edmundson比较的基本单位是句子,是通过句子级标号分隔开的文本单元,句子级标号包括“。”、“:”、“;”、“!”、“?”等。为使专家文摘与机械文摘具有可比性,只允许专家从原文中抽取句子,而不允许专家根据自己对原文的理解重新生成句子,专家文摘和机械文摘的句子都按照在原文中出现的先后顺序给出。
Edmundson定义:
每一个机械文摘的重合率为按三个专家给出的文摘得到的重合率的平均值:重合率p=匹配句子数/专家文摘句子数×100%
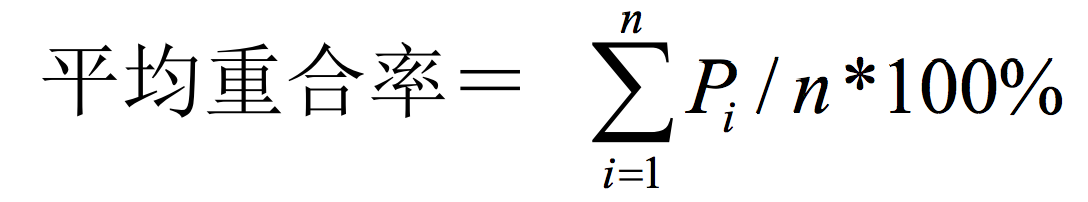
(二)ROUGE
ROUGE(Recall-Oriented Understudy for Gisting Evaluation),在2004年由ISI的Chin-Yew Lin提出的一种自动摘要评价方法,现被广泛应用于DUC(Document Understanding Conference)的摘要评测任务中。ROUGE基于摘要中n元词(n-gram)的共现信息来评价摘要,是一种面向n元词召回率的评价方法。基本思想为由多个专家分别生成人工摘要,构成标准摘要集,将系统生成的自动摘要与人工生成的标准摘要相对比,通过统计二者之间重叠的基本单元(n元语法、词序列和词对)的数目,来评价摘要的质量。通过与专家人工摘要的对比,提高评价系统的稳定性和健壮性。该方法现已成为摘要评价技术的通用标注之一。ROUGE准则由一系列的评价方法组成,包括ROUGE-N(N=1、2、3、4,分别代表基于1元词到4元词的模型),ROUGE-L,ROUGE-S, ROUGE-W,ROUGE-SU等。在自动文摘相关研究中,一般根据自己的具体研究内容选择合适的ROUGE方法。
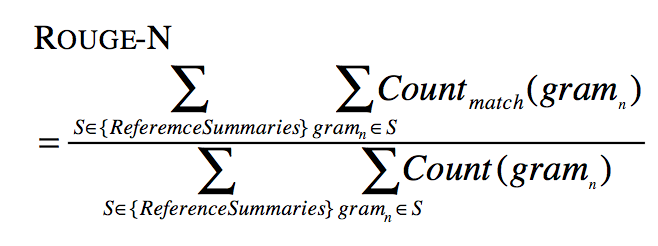
其中,n表示n-gram的长度,{Reference
Summaries}表示参考摘要,即事先获得的标准摘要,表示候选摘要和参考摘要中同时出现n-gram的个数,
则表示参考摘要中出现的n-gram个数。不难看出,ROUGE公式是由召回率的计算公式演变而来的,分子可以看作“检出的相关文档数目”,即系统生成摘要与标准摘要相匹配的N-gram个数,分母可以看作“相关文档数目”,即标准摘要中所有的N-gram个数。
例:R1 : police killed the gunman.
R2 : the gunman was shot down by police.
C1 : police ended the gunman.
C2 :the gunman murdered police.
R1,R2 为参考摘要,C1,C2 为候选摘要。
ROUGE-1(C1)=(3+3)/(4+7)=6/11
ROUGE-1(C2)=(3+3)/(4+7)=6/11
ROUGE-2(C1)=(1+1)/(3+6)=2/9
ROUGE-2(C2)=(1+1)/(3+6)=2/9
C1与C2的ROUGE-1、ROUGE-2分数相等,但是意思完全不相同!
优点:
直观,简洁,能反映词序。
缺点:
区分度不高,且当N>3时,ROUGE-N值通常很小。
应用场景:
ROUGE-1:短摘要评估,多文档摘要(去停用词条件);
ROUGE-2: 单文档摘要,多文档摘要(去停用词条件);
(2)ROUGE-L( Longest Common Subsequence )
公共子序列:给定两个序列X和Y,如果Z既是X的一个子序列又是Y的一个子序列,
则序列Z是X和Y的一个公共子序列。
LCS(最长公共子序列):给定两个序列X和Y,使得公共子序列长度最大的序列是X和Y的最长公共子序列。
Sentence-Level LCS
计算公式:
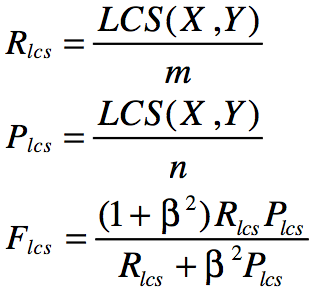
其中X为参考摘要,长度为m,Y为候选摘要,长度为n,用F值来衡量摘要X与Y的相似度,在DUC测评中,由于,所以只考虑
。
C1 : police ended the gunman.
C2 : the gunman murdered police.
R1为参考摘要,C1,C2为候选摘要。
ROUGE-L(C1)=3/4
ROUGE-L(C2)=2/4
C1优于C2!
优点:
不要求词的连续匹配,只要求按词的出现顺序匹配即可,能够像n-gram一样
反映句子级的词序。
自动匹配最长公共子序列,不需要预先定义n-gram的长度。
缺点:
只计算一个最长子序列,最终的值忽略了其他备选的最长子序列及较短子序列的影响。
应用场景:
单文档摘要;短摘要评估。
例:R1 : police killed the gunman.
将LCS应用到摘要级数相时,对参考摘要中的每一个句子C1 :the gunman murdered police.
C2 : the gunman police killed.
R1为参考摘要,C1,C2为候选摘要。
ROUGE-L(C1)=2/4
ROUGE-L(C2)=2/4
ROUGE-2(C1)=1/4
ROUGE-2(C2)=2/4
C1与C2的ROUGE-L分数相等,但C2的ROUGE-2分数高于C1,C2优于C1!
Summary-Level LCS
计算公式:
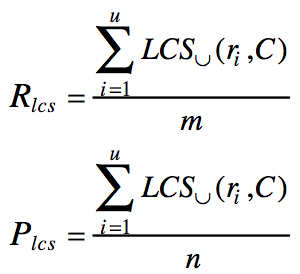

其中R为参考摘要,包含u个句子,m个词,C为候选摘要,包含v个句子,n个词,长度为n,
是句子
和候选摘要C的union LCS。
例:参考只要集句子
: w1 w2 w3 w4 w5
候选摘要C包含两个句子
c1 : w1 w2 w6 w7 w8
c2 : w1 w3 w8 w9 w5
与 c1 的LCS 为w1 w2,与c2的LCS为w1 w3 w5,与C的union LCS 为w1 w2 w3 w5。
ROUGE-L(C)=4/5
(3)ROUGE-W( WeightLongest Common Subsequence )
为使连续匹配比不连续匹配赋予更大的权重,公式描述如下:
例如,同时为了归一化最终的ROUGE-W值,通常选择函数与反函数具有相似形式的函数。例如:
计算公式:
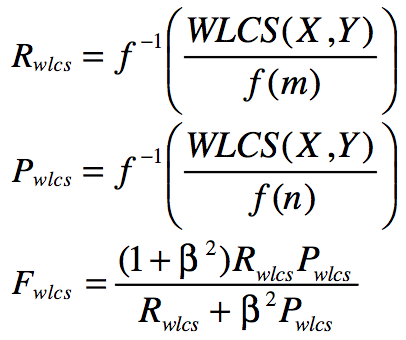
例:R1 : police killed the gunman who injured 3 on campus.
C1 : police kill the gunman and sealed off the scene.
C2 : the police was killed and the gunman ran off.
R1为参考摘要,C1,C2为候选摘要,取
WLCS(R1, C1) = 4*4=16,f(m) = 9*9 =81
WLCS(R1, C2) = 2*4=16,f(m) = 9*9 =81
ROUGE-W(C1) = 0.444
C2优于C1!优点:同一LCS下,对连续匹配词数多的句子赋予更高权重,比LCS区分度更高。
缺点:同ROUGE-L,只计算一个最长子序列,最终的值忽略了其他备选的最长子序列及较短子序列的影响。应用场景:单文档摘要;短摘要评估;
(4)ROUGE-S( Skip-BigramCo-Occurrence Statistics)
Skip-Bigram是按句子顺序中的任何成对词语。
计算公式:
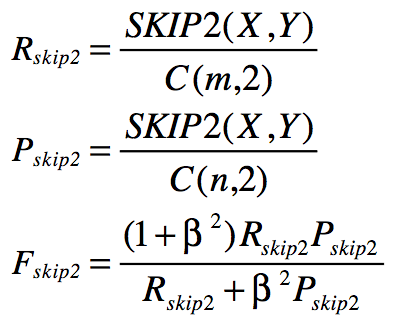
其中X为参考摘要,长度为m,Y为候选摘要,长度为n。SKIP2(X,Y)表示候选摘要与参考摘要的skip-bigram匹配次数。
Skip-gram如果不限制跳跃的距离,会出现很多无意义的词对,比如“the
of”、“in the”等。为了减少无意义词对的出现,可以限制最大跳跃距离,通常写ROUGE-S4表示最大跳跃距离为4,ROUGE-S9表示最大跳跃距离为9,依次类推。如果
为0,那么ROUGE-S0
= ROUGE-2。
例: R1 :police killed the gunman.
C1 :police kill the gunman.
C2 :the gunman kill police.
C3 : thegunman police killed.
R1为参考摘要,C1,C2,C3为候选摘要。
候选摘要 ROUGE-1 ROUGE-2 ROUGE-L ROUGE-W ROUGE-S C1 0.75 0.25 0.75 0.61 0.5 C2 0.75 0.25 0.5 0.5 0.167 C3 1 0.5 0.5 0.5 0.333
优点:考虑了所有按词序排列的词对,比n-gram模型更深入反映句子级词序。
缺点:若不设定最大跳跃词数会出现很多无意义词对。若设定最大跳跃词数,需要指定最大跳跃词数的值。应用场景:单文档摘要;ROUGE-S4,ROUGE-S9: 多文档摘要(去停用词条件);


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









