









Deep Learning论文笔记之(六)Multi-Stage多级架构分析
自己平时看了一些论文,但老感觉看完过后就会慢慢的淡忘,某一天重新拾起来的时候又好像没有看过一样。所以想习惯地把一些感觉有用的论文中的知识点总结整理一下,一方面在整理过程中,自己的理解也会更深,另一方面也方便未来自己的勘察。更好的还可以放到博客上面与大家交流。因为基础有限,所以对论文的一些理解可能不太正确,还望大家不吝指正交流,谢谢。
本文的论文来自:
Kevin Jarrett, Koray Kavukcuoglu, Marc’Aurelio Ranzato, and Yann LeCun, ”What is the Best Multi-Stage Architecture for Object Recognition?”, in Proc. International Conference on Computer Vision (ICCV’09), 2009
这里面还提供了一个精简版的Matlab代码。实现的是random convolutional filters 和linear logistic regression classifier的两级目标识别系统。
下面是自己对其中的一些知识点的理解:
《What is the Best Multi-Stage Architecture for Object Recognition?》
对目标识别怎样的多级架构Multi-Stage Architecture还是最好的?在当前的很多目标识别系统中,特征提取阶段一般由一组滤波器,再进行非线性变换和一些类型的特征pooling层组成。大部分系统都使用一级特征提取,这时候的滤波器是hard-wired(人工选择的,硬连线的,参数不可学习调整)的,或者使用两级,这时候其中的一级或者两级的滤波器都可以通过监督或者非监督的方式学习得到。
本文关注三个问题:
1)滤波器组后面接的non-linearities非线性算法是如何影响识别的准确性的?
2)通过监督或者非监督方式学习到的滤波器组是否比随机的滤波器组或者人工指定的滤波器要好?
3)与仅有一级的特征提取对比,两级的特征提取是否还有其他优点?
我们证明了:
1)使用包含校正和局部对比度归一化的非线性算子对增加目标识别的准确性来说有很大帮助。
2)两级的特征提取比一级的要好。准确率更高。
3)惊喜的是,用随机初始化的滤波器组的两级系统却可以在Caltech这个数据中达到63%的识别率。当然,这里面包含了合适的非线性算子和pooling层。
4)经过监督微调,系统在NORB数据库上达到当前领先水平。而且非监督预训练后再加监督微调可以在Caltech这个数据库中达到更好的准确率(大于63%)。然后在没有处理过的MNIST数据库中,可以达到目前我们知道的最低的0.53%的错误率。
一、概述
在过去这几年,对于目标识别来说,出现了很多不错的特征描述子。很多方法都是把输入图像划分为一个个规律排列的密集的patch,然后提取这些patch的特征。再以某种方式组合这些patch的特征作为这个输入图像的特征。概括的来说,这些系统的很大一部分都是这样的一个特征提取过程:输入经过一个滤波器组filter bank(一般是基于方向性的边缘检测器),再经过一个非线性算子non-linear operation(quantization, winner-take-all, sparsification, normalization, and/or point-wise saturation),然后用一个pooling操作(把实空间或者特征空间邻域的值通过一个max, average, or histogramming operator)来绛维和得到一定的不变性。例如俺们熟知的SIFT特征,它先通过对每个小patch经过方向性边缘检测器,然后用winner-take-all算子来获取最显著的方向。最后,在更大块的patch上面统计局部方向的直方图,pooling成一个稀疏向量。
对于一层特征提取的系统,也就是提取到了上面的这个特征后,例如SIFT,HOG等,然后直接接一个监督学习的分类器,就构成了一个目标识别系统。还有一些模型会使用两级或者更多级的特征提取器,然后再接一个监督学习分类器来构成一个比较复杂的目标识别系统。这些系统本质的差别在于:有一个或者多个特征提取层、滤波器组后使用的非线性算子、滤波器组的得到(人工选择、非监督学习还是监督学习)和顶层的分类器的选择(线性分类器还是更复杂的分类器)。
一般对滤波器组的选择是Gabor小波,还有人选择一些简单的方向性检测滤波器组,也就是梯度算子,例如SIFT和HOG。还有一些直接通过非监督学习方法直接从训练数据中学习这些滤波器组。当在自然图像中训练的时候,学到的滤波器也是类似于Gabor边缘检测的东西。特征学习方法的一个好处就是它可以分级的学习特征。因为我们具有一定的先验知识,觉得第一级的特征就应该是边缘检测器,但第二层特征又应该是什么呢?人就没有这个类似的先验知识了。所以就比较难人工设计一个比较好二级特征提取器。所以说,二级或者多级特征必须让系统自己学习。现在出现的方法也很多了,有监督的,非监督的,或者两者联合的。
咋一看,用像Caltech-101这些非常少的训练数据库(这个数据库要识别101类的物体,但每类只提供了很少的有标签训练数据)只用监督学习算法来训练一个完整的系统显得有点天真和不被看好,因为模型参数的个数比训练样本的个数都要多很多。所以很多人觉得只有非常认真的训练或者人工挑选好的滤波器组才可以有好的识别性能,然后再考虑非线性算子的选择。其实,这些观点,都是wrong的。
二、模型架构
这部分讲述如何去构建一个分级的特征提取和分类系统。分级通过堆叠一个或者多个特征提取阶段,每个阶段包括一个滤波器组合层、非线性变换层和一个pooling层,pooling层通过组合(取平均或者最大的)局部邻域的滤波器响应,因而达到对微小变形的不变性。

1、滤波器组层Filter Bank Layer-FCSG:
FCSG一般包括三部分:一组卷积滤波器(C)、再接一个sigmoid/tanh非线性变换函数(S),然后是一个可训练的增益系数(G)。分别对应下面的三个运算:
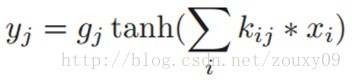
2、校正层Rectification Layer-Rabs:
只是简单的一个取绝对值的操作(如果是tanh,则存在负的值,但在图像中负值是不表示的,而对于卷积来说,里面的都是绝对值越大,非线性函数输出的绝对值最大,实际意义是一样的。卷积是越相似,输出值越大)。除了绝对值算子外,我们还试过了其他的非线性算子,产生的效果差不多。
3、局部对比度归一化层Local Contrast Normalization Layer-N:
该模块主要进行的是局部做减和做除归一化,它会迫使在特征map中的相邻特征进行局部竞争,还会迫使在不同特征maps的同一空间位置的特征进行竞争。在一个给定的位置进行减法归一化操作,实际上就是该位置的值减去邻域各像素的加权后的值,权值是为了区分与该位置距离不同影响不同,权值可以由一个高斯加权窗来确定。除法归一化实际上先计算每一个特征maps在同一个空间位置的邻域的加权和的值,然后取所有特征maps这个值的均值,然后每个特征map该位置的值被重新计算为该点的值除以max(那个均值,该点在该map的邻域的加权和的值)。分母表示的是在所有特征maps的同一个空间邻域的加权标准差。哦哦,实际上如果对于一个图像的话,就是均值和方差归一化,也就是特征归一化。这个实际上是由计算神经科学模型启发得到的。(这里自己有点理解,请见本文的第四节)
4、平均池化和子采样层Average Pooling and Subsampling Layer -PA:
该层的作用是使得提取的特征对微小变形鲁棒,和视觉感知中的复杂细胞的角色差不多。采样窗口所有值取平均得到下采样层的值。
5、最大值池化和子采样层Max-Pooling and Subsampling Layer -PM:
可以用任何一种对称的pooling操作实现对提取的特征的平移不变性。最大池与平均池相似,只是最大取代了平均。一般来说,池化窗口是不重叠的。
三、实验与结论
该文做了很多实验来验证不同的模型架构的性能(组合上面的不同的层)。这里就不列举实验结果了,可以回原文查看。这里就直接回答一开始的那几个问题吧:
1)滤波器组后面接的non-linearities非线性算法是如何影响识别的准确性的?
俺们的实验结论是,简单的矫正过的非线性算子会提高识别性能。原因可能有二。a)特征的对立polarity(也就是负值的特征)和目标的识别是无关的。b)在采用平均池化的时候,矫正层的添加会消去邻近的滤波器输出之间的cancellations,因为如果没有矫正,平均下采样只会传播输入的噪声。另外,局部归一化层也会增加性能,因为它可以使监督学习算法更快,也许是因为所有的变量都具有相似的方差了(与其他白化和去相关的方法的优点一样),这样会加快收敛速度。
2)通过监督或者非监督方式学习到的滤波器组是否比随机的滤波器组或者人工指定的滤波器要好?
实验结果很惊喜,在两级系统中采样随机滤波器组在Caltech-101中居然达到了挺高的62.9%的识别率,但在NORB数据库中就显得有点低调了,可能这种情况只会在训练样本集较少的时候才出现。另外,非监督预训练接个监督微调会有最好的效果,尽管比单纯的全部使用监督会差点。
3)与仅有一级的特征提取对比,两级的特征提取是否还有其他优点?
实验证明,两级比一级好。我们这里,两级系统的性能和最好的一级系统的性能:SIFT特征+PMK-SVM分类器相媲美,也许PM Kernel还隐藏着实现了我们的第二级特征提取的功能。
四、关于local contract normalization
这里对这个东西再啰嗦一下。local contract normalization 这个归一化包括两个部分:局部做减和局部做除(local subtractive and divisive normalizations)。我的理解:自然图像存在低阶和高阶的统计特征,低阶(例如二阶)的统计特征是满足高斯分布的,但高阶的统计特性是非高斯分布。图像中,空间上相邻的像素点有着很强的相关性。而对于PCA来说,因为它是对协方差矩阵操作,所以可以去掉输入图像的二阶相关性,但是却无法去掉高阶相关性。而有人证明了除以一个隐含的变量就可以去除高阶相关性。你可以理解为一张图像x的像素值是一个随机变量,它由两个独立的随机变量相乘得到,分别是二阶量和高阶量相乘,二阶量的相关性可以由PCA去掉,然后高阶量(这个是隐含的,需要通过MAP最大后验估计等方法估计出来)直接用x除掉就好了。
有论文的操作是这样:
对输入图像的每一个像素,我们计算其邻域(例如3x3窗口)的均值,然后每个像素先减去这个均值,再除以这个邻域窗口(例如3x3窗口)拉成的9维向量的欧几里德范数(如果这个范数大于1的时候才除:这个约束是为了保证归一化只作用于减少响应(除以大于1的数值变小),而不会加强响应(除以小于1的数值变大))。也有论文在计算均值和范数的时候,都加入了距离的影响,也就是距离离该窗口中心越远,影响越小,例如加个高斯权重窗口(空间上相邻的像素点的相关性随着距离变大而变小)。
其实在这里,很多自己也还不清楚,所以上面的不一定正确,仅供参考。还望明白的人也指点一下。谢谢。
关于local contract normalization可以参考以下两篇文章:
S. Lyu 等:Nonlinear image representation using divisive normalization.
N. Pinto等: Why is real-world visual object recognition hard?















 4822
4822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









