







目录
2.2 曼哈顿距离(Manhattan Distance):
2.3 切⽐雪夫距离 (Chebyshev Distance):
2.4 闵可夫斯基距离(Minkowski Distance):
分类算法
3.1 sklearn转换器和估计器
转换器
估计器(estimator)
3.1.1 转换器 - 特征工程的父类
1 实例化 (实例化的是一个转换器类(Transformer))
2 调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
标准化:
(x - mean) / std
步骤:fit_transform()
fit() 计算 每一列的平均值、标准差
transform() (x - mean) / std进行最终的转换

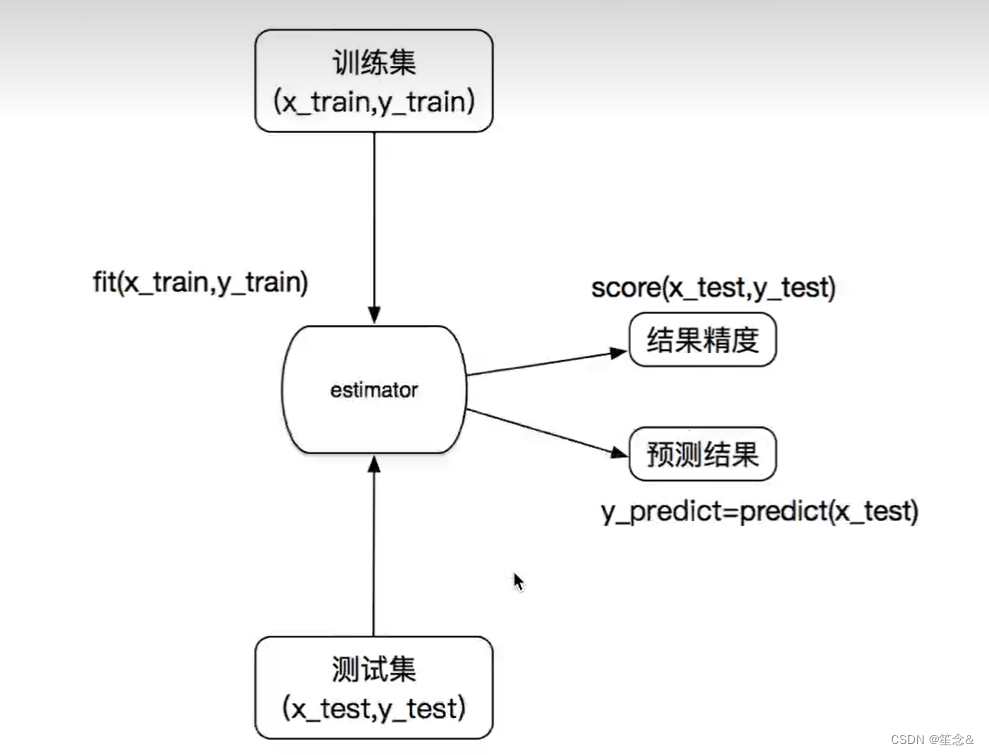
3.1.2 估计器(sklearn机器学习算法的实现)
估计器(estimator)
1 实例化一个estimator
2 estimator.fit(x_train, y_train) 计算
—— 调用完毕,模型生成
3 模型评估:
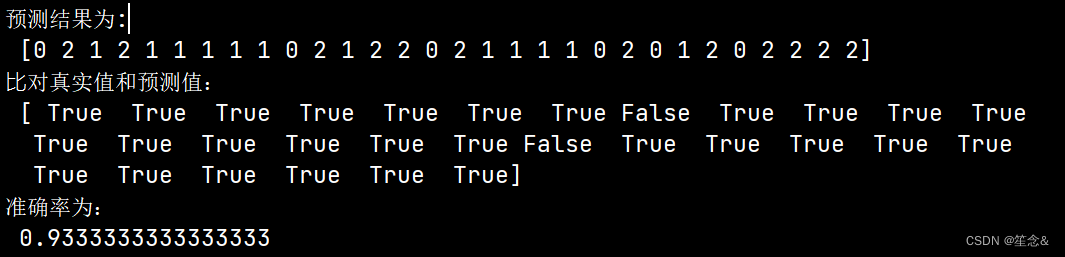
1)直接比对真实值和预测值
y_predict = estimator.predict(x_test)
y_test == y_predict
2)计算准确率
accuracy = estimator.score(x_test, y_test)

估计器流程
-
-
K-近邻算法
-
- 什么是K-近邻算法
根据你的“邻居”来推断出你的类别
1.1 K-近邻算法(KNN)概念
K Nearest Neighbor算法⼜叫KNN算法,这个算法是机器学习⾥⾯⼀个⽐较经典的算法,
1.定义
如果⼀个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的⼤多数属于某⼀个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的⼀种分类算法
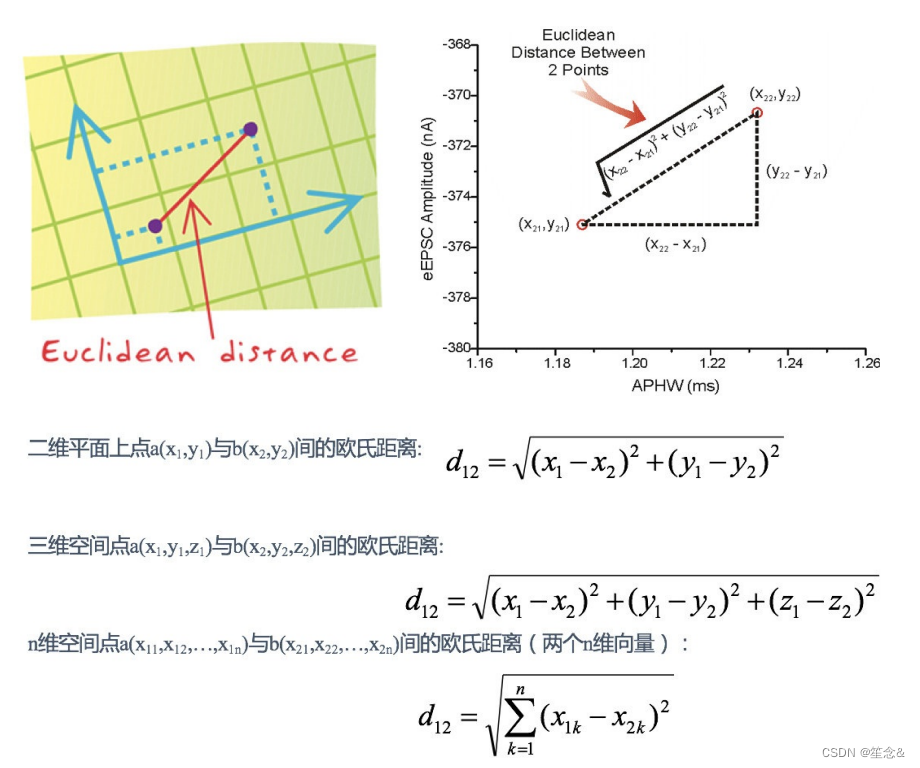
2.距离公式
两个样本的距离可以通过如下公式计算,⼜叫欧式距离 ,关于距离公式会在后⾯进⾏讨论
例:电影类型分析:
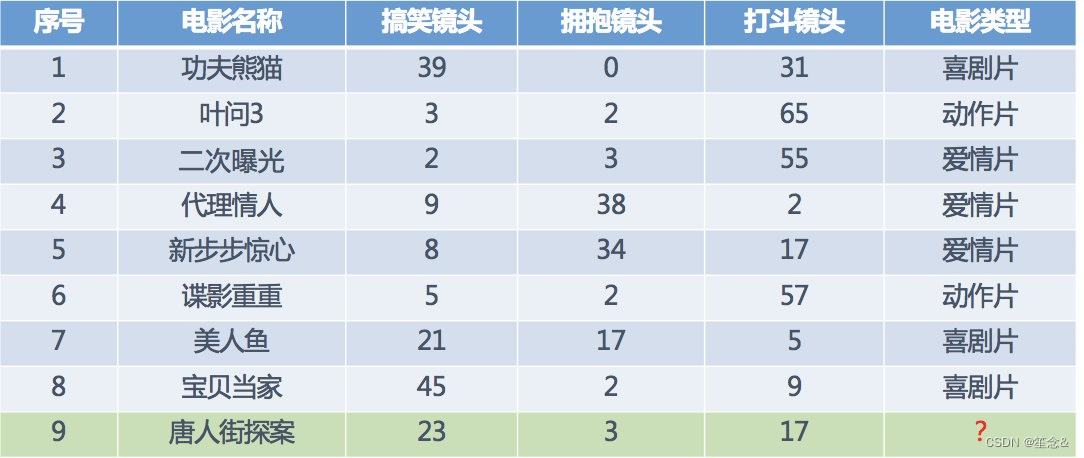
分析九号电影类型
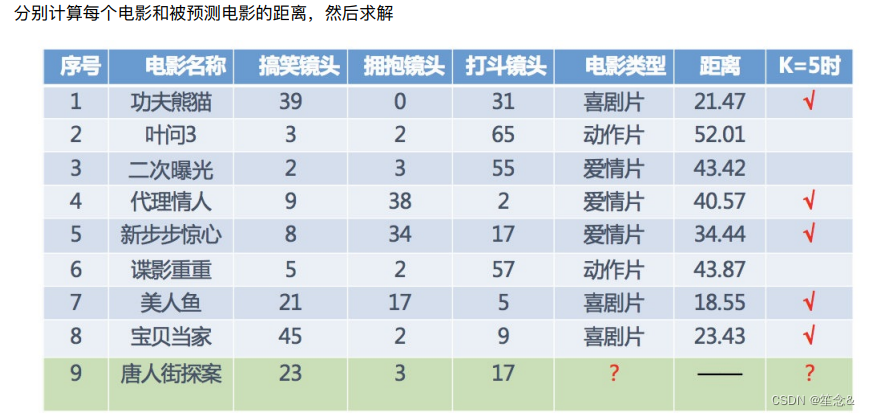
1.3 KNN算法流程总结
1)计算已知类别数据集中的点与当前点之间的距离
2)按距离递增次序排序
3)选取与当前点距离最⼩的k个点
4)统计前k个点所在的类别出现的频率
5)返回前k个点出现频率最⾼的类别作为当前点的预测分类
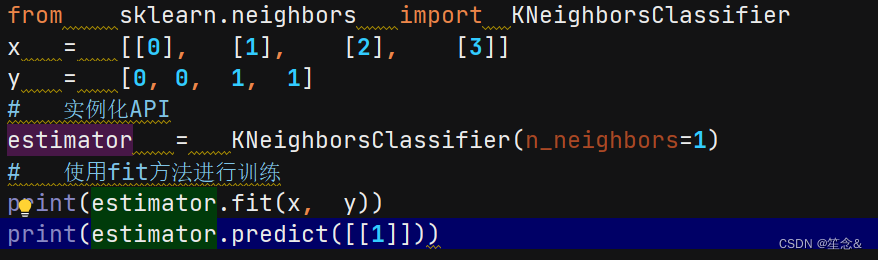
1.2 k近邻算法api初步使⽤
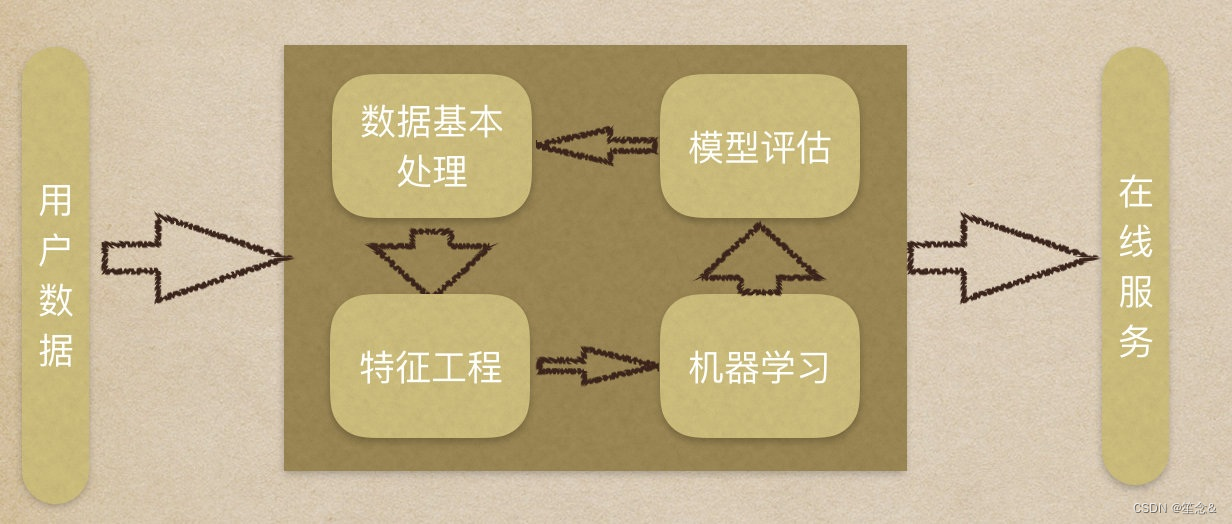
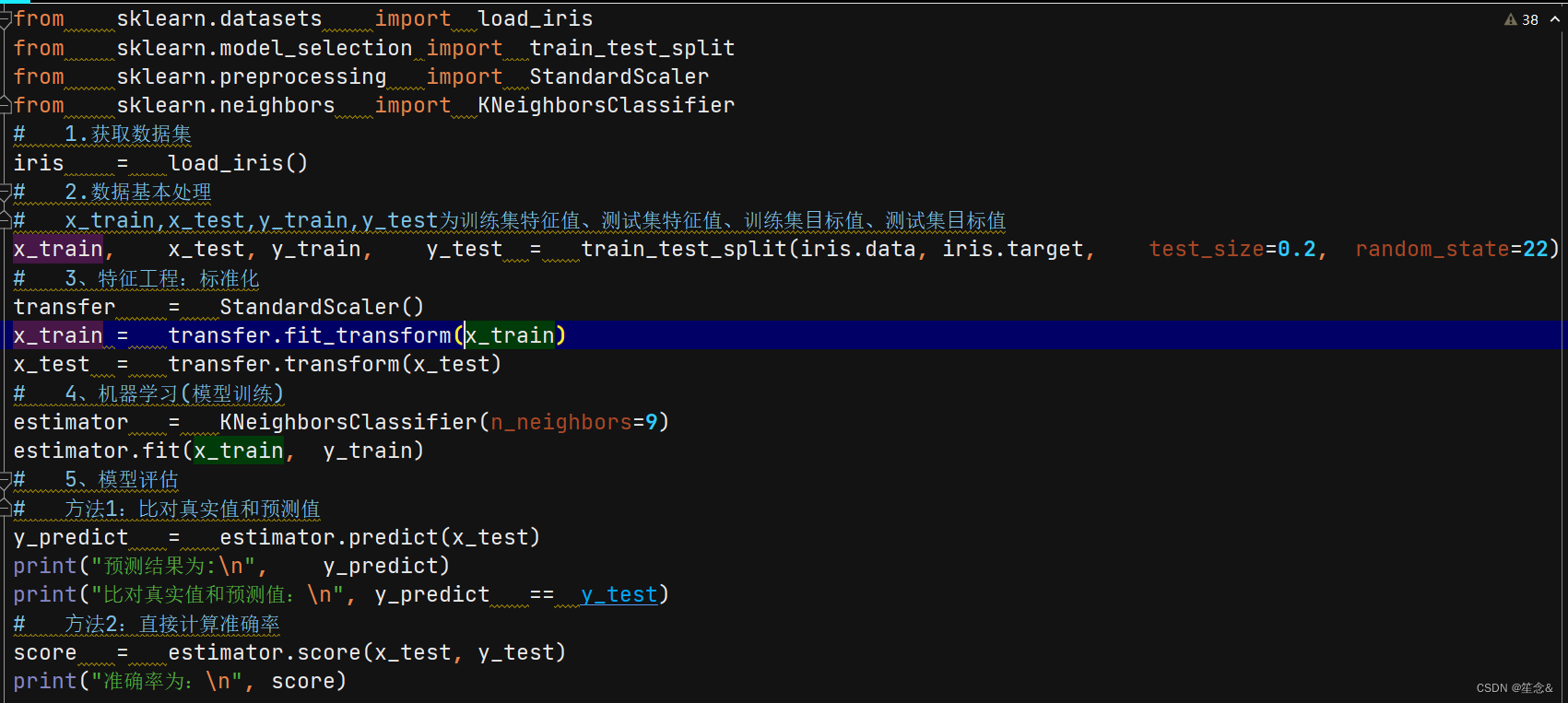
1.获取数据集
2.数据基本处理
3.特征⼯程
4.机器学习
5.模型评估
2 K-近邻算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
n_neighbors:
int,可选(默认= 5),k_neighbors查询默认使⽤的邻居数
algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’}
快速k近邻搜索算法,默认参数为auto,可以理解为算法⾃⼰决定合的搜索算法。除此之外,⽤户也可以⾃⼰指定搜索算法ball_tree、kd_tree、brute⽅法进⾏搜索,brute是蛮⼒搜索,也就是线性扫描,当训练集很⼤时,计算⾮常耗时。kd_tree,构造kd树存储数据以便对其进⾏快速检索的树形数据结构,kd树也就是数据结构中的⼆叉树。以中值切分构造的树,每个结点是⼀个超矩形,在维数⼩于20时效率⾼。ball tree是为了克服kd树⾼维失效⽽发明的,其构造过程是以质⼼C和半径r分割样本空间,每个节点是⼀个超球体。
3案例

-
-
距离度量
-
距离公式的基本性质
在机器学习过程中,对于函数 dist(., .),若它是⼀"距离度量" (distance measure),则需满⾜⼀些基本性质:
⾮负性: dist(X , X ) >= 0 ;
同⼀性:dist(x , x ) = 0。当且仅当 X = X ;
对称性: dist(x , x ) = dist(x , x );
直递性: dist(x , x ) <= dist(x , x ) + dist(x , x )
直递性常被直接称为“三⻆不等式”。
2 常⻅的距离公式
2.1 欧式距离(Euclidean Distance):
欧⽒距离是最容易直观理解的距离度量⽅法,我们⼩学、初中和⾼中接触到的两个点在空间中的距离⼀般都是指欧⽒距离。


2.2 曼哈顿距离(Manhattan Distance):
在曼哈顿街区要从⼀个⼗字路⼝开⻋到另⼀个⼗字路⼝,驾驶距离显然不是两点间的直线距离。这个实际驾驶距离就是“曼哈顿距离”。曼哈顿距离也称为“城市街区距离”(City Block distance)。
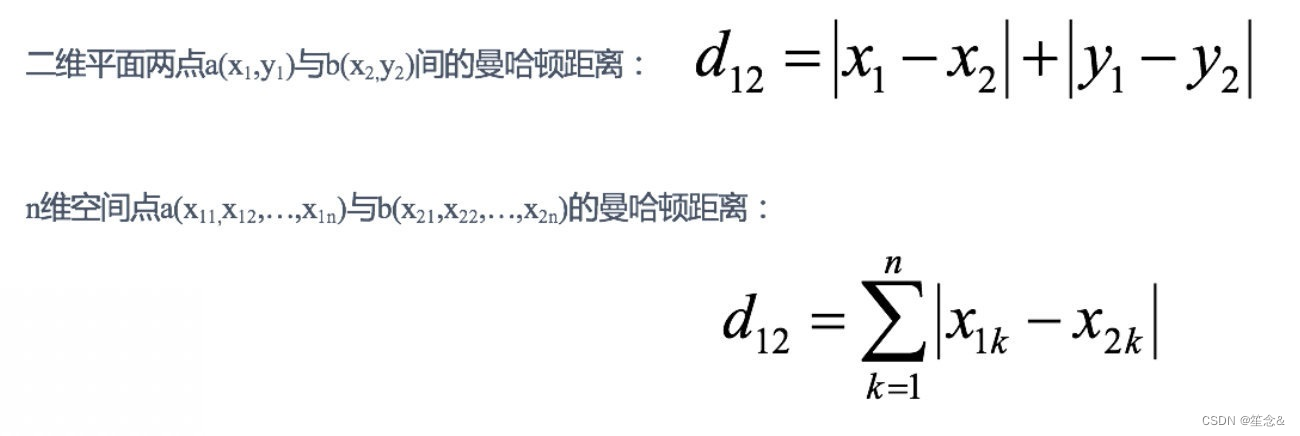

2.3 切⽐雪夫距离 (Chebyshev Distance):
国际象棋中,国王可以直⾏、横⾏、斜⾏,所以国王⾛⼀步可以移动到相邻8个⽅格中的任意⼀个。国王从格⼦(x1,y1)⾛到格⼦(x2,y2)最少需要多少步?这个距离就叫切⽐雪夫距离。
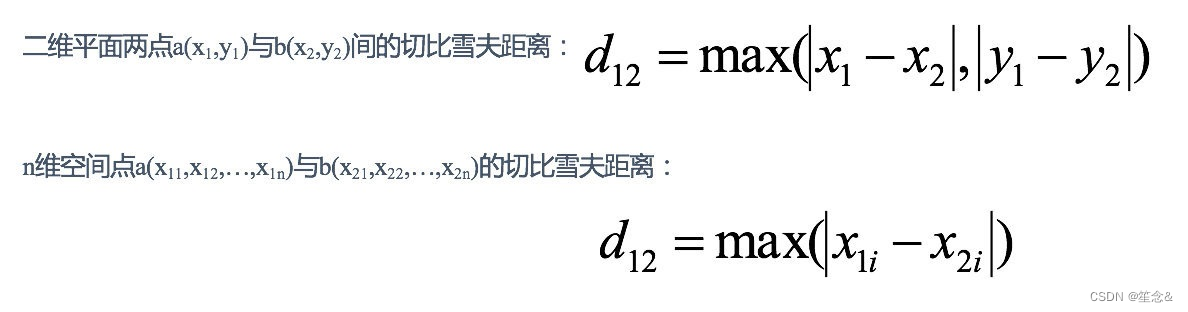

2.4 闵可夫斯基距离(Minkowski Distance):
闵⽒距离不是⼀种距离,⽽是⼀组距离的定义,是对多个距离度量公式的概括性的表述。
两个n维变量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:

根据p的不同,闵⽒距离可以表示某⼀类/种的距离。
⼩结:
1 闵⽒距离,包括曼哈顿距离、欧⽒距离和切⽐雪夫距离,都存在明显的缺点:
e.g. ⼆维样本(身⾼[单位:cm],体重[单位:kg]),现有三个样本:a(180,50),b(190,50),c(180,60)。
a与b的闵⽒距离(⽆论是曼哈顿距离、欧⽒距离或切⽐雪夫距离)等于a与c的闵⽒距离。但实际上身⾼的10cm并不能
和体重的10kg划等号。
2 闵⽒距离的缺点:
(1)将各个分量的量纲(scale),也就是“单位”相同的看待了;
(2)未考虑各个分量的分布(期望,⽅差等)可能是不同的。
3 “连续属性”和“离散属性”的距离计算
我们常将属性划分为"连续属性" (continuous attribute)和"离散属性" (categorical attribute),前者在定义域上有⽆穷多个
可能的取值,后者在定义域上是有限个取值.
若属性值之间存在序关系,则可以将其转化为连续值,例如:身⾼属性“⾼”“中等”“矮”,可转化为{1, 0.5, 0}。
闵可夫斯基距离可以⽤于有序属性。
若属性值之间不存在序关系,则通常将其转化为向量的形式,例如:性别属性“男”“⼥”,可转化为{(1,0),
(0,1)}。
1.4 k值的选择
K值过⼩:
容易受到异常点的影响
k值过⼤:
受到样本均衡的问题
1) 选择较⼩的K值,就相当于⽤较⼩的领域中的训练实例进⾏预测,“学习”近似误差会减⼩,只有与输⼊实例较近或相似的训练实例才会对预测结果起作⽤,与此同时带来的问题
是“学习”的估计误差会增⼤,
换句话说,K值的减⼩就意味着整体模型变得复杂,容易发⽣过拟合;
2) 选择较⼤的K值,就相当于⽤较⼤领域中的训练实例进⾏预测,
其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增⼤。这时候,与输⼊实例较远(不相似的)训练实例也会对预测器作⽤,使预测发⽣错误。且K值的增⼤就意味着整体的模型变得简单。
3) K=N(N为训练样本个数),则完全不⾜取,
因为此时⽆论输⼊实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单,忽略了训练实例中⼤量有⽤信息。在实际应⽤中,K值⼀般取⼀个⽐较⼩的数值,例如采⽤交叉验证法(简单来说,就是把训练数据在分成两组:训练集和验证集)来选择最优的K值。
近似误差:
对现有训练集的训练误差,关注训练集,
如果近似误差过⼩可能会出现过拟合的现象,对现有的训练集能有很好的预测,但是对未知的测试样本将会出
现较⼤偏差的预测。
模型本身不是最接近最佳模型。
估计误差:
可以理解为对测试集的测试误差,关注测试集,
估计误差⼩说明对未知数据的预测能⼒好,
模型本身最接近最佳模型。
1.5 kd树
问题导⼊:
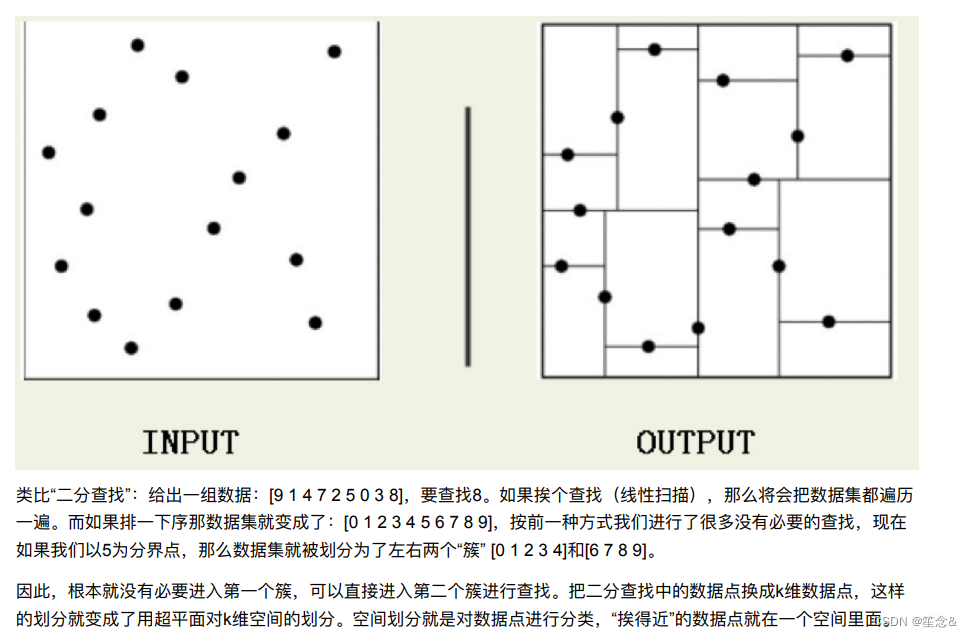
实现k近邻算法时,主要考虑的问题是如何对训练数据进⾏快速k近邻搜索。
这在特征空间的维数⼤及训练数据容量⼤时尤其必要。
k近邻法最简单的实现是线性扫描(穷举搜索),即要计算输⼊实例与每⼀个训练实例的距离。计算并存储好以后,再
查找K近邻。当训练集很⼤时,计算⾮常耗时。
为了提⾼kNN搜索的效率,可以考虑使⽤特殊的结构存储训练数据,以减⼩计算距离的次数。
1 kd树简介
1.1 什么是kd树
根据KNN每次需要预测⼀个点时,我们都需要计算训练数据集⾥每个点到这个点的距离,然后选出距离最近的k个点进
⾏投票。当数据集很⼤时,这个计算成本⾮常⾼,针对N个样本,D个特征的数据集,其算法复杂度为O(DN )。
kd树:为了避免每次都重新计算⼀遍距离,算法会把距离信息保存在⼀棵树⾥,这样在计算之前从树⾥查询距离信息,
尽量避免重新计算。其基本原理是,如果A和B距离很远,B和C距离很近,那么A和C的距离也很远。有了这个信息,
就可以在合适的时候跳过距离远的点。
这样优化后的算法复杂度可降低到O(DNlog(N))。感兴趣的读者可参阅论⽂:Bentley,J.L.,Communications of
the ACM(1975)。
1989年,另外⼀种称为Ball Tree的算法,在kd Tree的基础上对性能进⼀步进⾏了优化。感兴趣的读者可以搜索Five
balltree construction algorithms来了解详细的算法信息。
1.2 原理
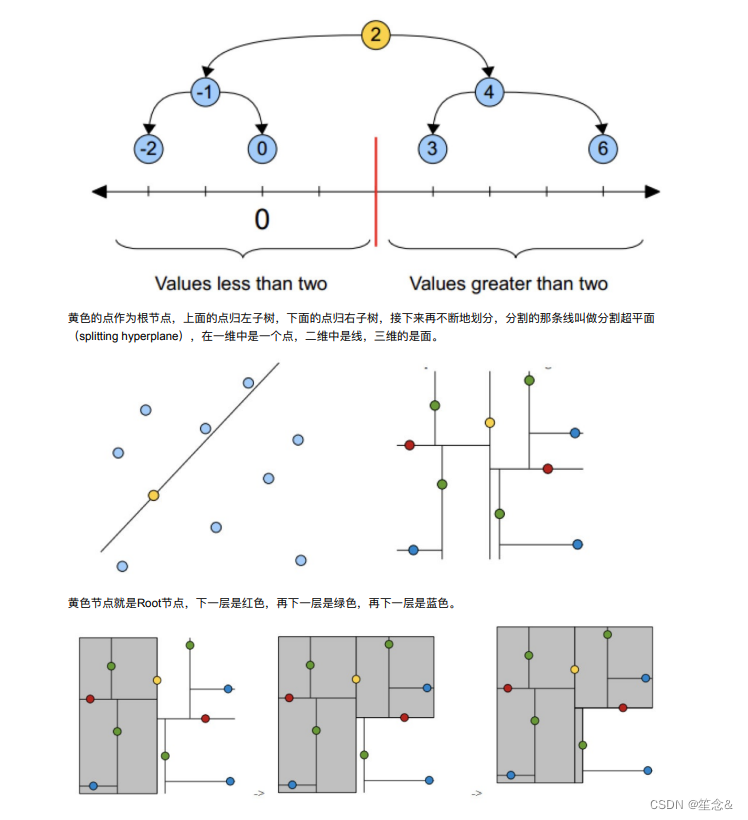
1.树的建⽴;
2.最近邻域搜索(Nearest-Neighbor Lookup)
kd树(K-dimension tree)是⼀种对k维空间中的实例点进⾏存储以便对其进⾏快速检索的树形数据结构。kd树是⼀种⼆叉
树,表示对k维空间的⼀个划分,构造kd树相当于不断地⽤垂直于坐标轴的超平⾯将K维空间切分,构成⼀系列的K维超
矩形区域。kd树的每个结点对应于⼀个k维超矩形区域。利⽤kd树可以省去对⼤部分数据点的搜索,从⽽减少搜索的计算量。

案例一:鸢尾花种类预测
2 scikit-learn中数据集介绍
2.1 scikit-learn数据集API介绍
sklearn.datasets
加载获取流⾏数据集
datasets.load_*()
获取⼩规模数据集,数据包含在datasets⾥
datasets.fetch_*(data_home=None)
获取⼤规模数据集,需要从⽹络上下载,函数的第⼀个参数是data_home,表示数据集下载的⽬录,默认是 ~/scikit_learn_data/
2.1.1 sklearn⼩数据集
sklearn.datasets.load_iris()
加载并返回鸢尾花数据集
2.1.2 sklearn⼤数据集
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
subset:'train'或者'test','all',可选,选择要加载的数据集。
训练集的“训练”,测试集的“测试”,两者的“全部”
2.2 sklearn数据集返回值介绍
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
data:特征数据数组,是 [n_samples * n_features] 的⼆维 numpy.ndarray 数组
target:标签数组,是 n_samples 的⼀维 numpy.ndarray 数组
DESCR:数据描述
feature_names:特征名,新闻数据,⼿写数字、回归数据集没有
target_names:标签名

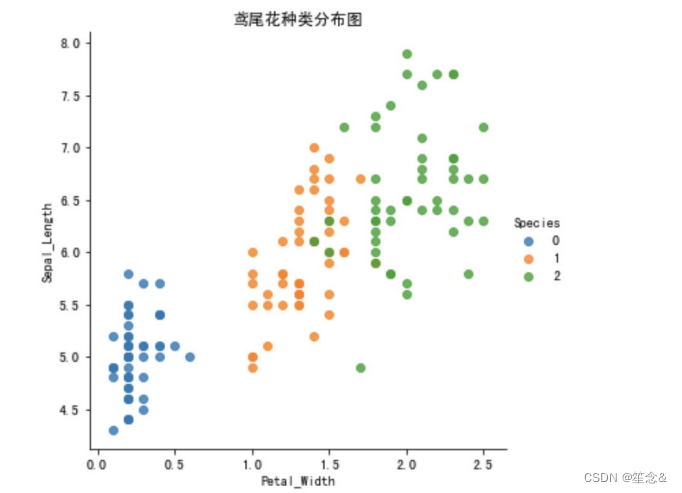
2.3 查看数据分布
通过创建⼀些图,以查看不同类别是如何通过特征来区分的。 在理想情况下,标签类将由⼀个或多个特征对完美分隔。 在现实世界中,这种理想情况很少会发⽣。
seaborn介绍
Seaborn 是基于 Matplotlib 核⼼库进⾏了更⾼级的 API 封装,可以让你轻松地画出更漂亮的图形。⽽ Seaborn
的漂亮主要体现在配⾊更加舒服、以及图形元素的样式更加细腻。
安装 pip3 install seaborn
seaborn.lmplot() 是⼀个⾮常有⽤的⽅法,它会在绘制⼆维散点图时,⾃动完成回归拟合
sns.lmplot() ⾥的 x, y 分别代表横纵坐标的列名,
data= 是关联到数据集,
hue=*代表按照 species即花的类别分类显示,
fit_reg=是否进⾏线性拟合。

2.4 数据集的划分
机器学习⼀般的数据集会划分为两个部分:
训练数据:⽤于训练,构建模型
测试数据:在模型检验时使⽤,⽤于评估模型是否有效
划分⽐例:
训练集:70% 80% 75%
测试集:30% 20% 25%
数据集划分api
sklearn.model_selection.train_test_split(arrays, *options)
参数:
x 数据集的特征值
y 数据集的标签值
test_size 测试集的⼤⼩,⼀般为float
random_state 随机数种⼦,不同的种⼦会造成不同的随机采样结果。相同的种⼦采样结果相同。
return
x_train, x_test, y_train, y_test


具体流程;

例:预测facebook签到位置
本次⽐赛的⽬的是预测⼀个⼈将要签到的地⽅。 为了本次⽐赛,Facebook创建了⼀个虚拟世界,其中包括10公⾥*10
公⾥共100平⽅公⾥的约10万个地⽅。 对于给定的坐标集,您的任务将根据⽤户的位置,准确性和时间戳等预测⽤户下
⼀次的签到位置。 数据被制作成类似于来⾃移动设备的位置数据。 请注意:您只能使⽤提供的数据进⾏预测。
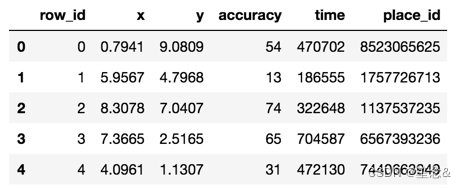
⽂件说明 train.csv, test.csv
row id:签⼊事件的id
x y:坐标
accuracy: 准确度,定位精度
time: 时间戳
place_id: 签到的位置,这也是你需要预测的内容
3 步骤分析
对于数据做⼀些基本处理(这⾥所做的⼀些处理不⼀定达到很好的效果,我们只是简单尝试,有些特征我们可以根
据⼀些特征选择的⽅式去做处理)
1 缩⼩数据集范围 DataFrame.query()
2 选取有⽤的时间特征
3 将签到位置少于n个⽤户的删除
分割数据集
标准化处理
k-近邻预测
具体步骤:
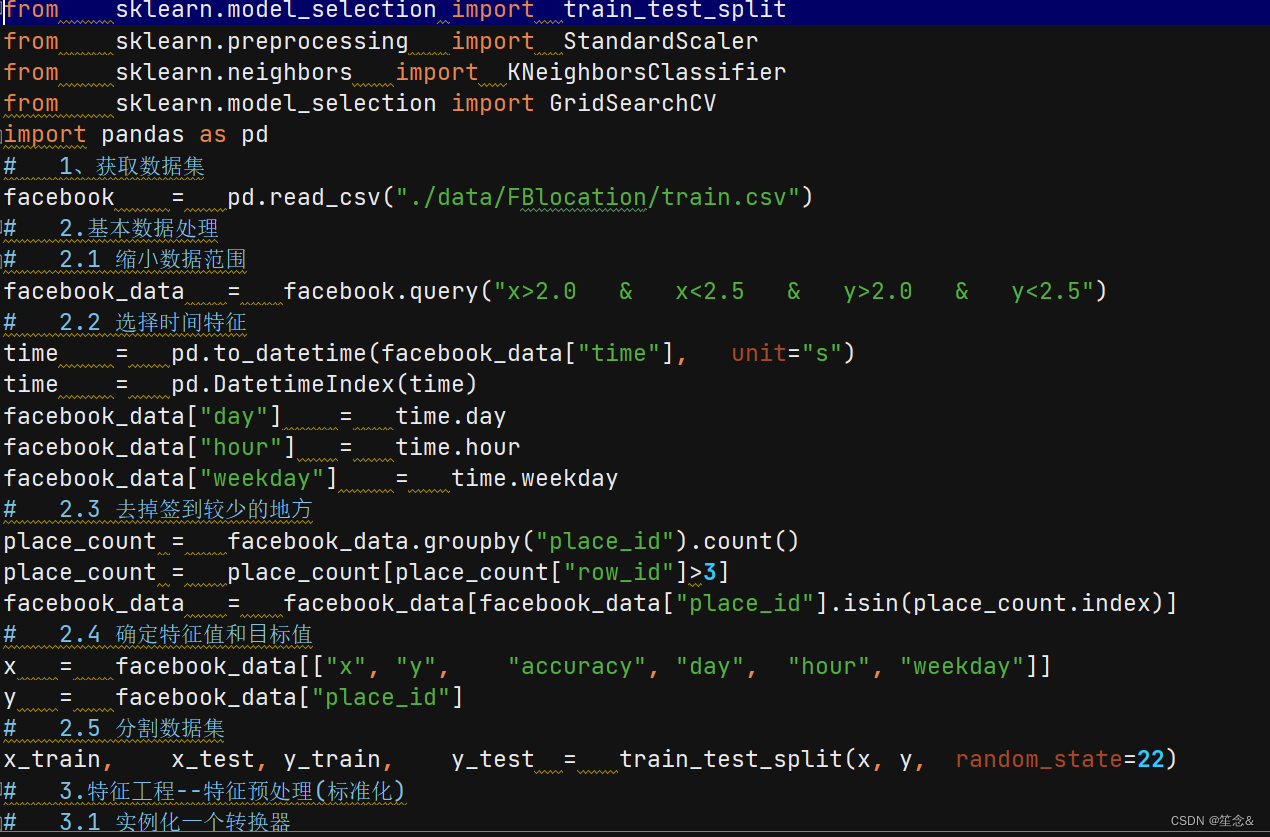
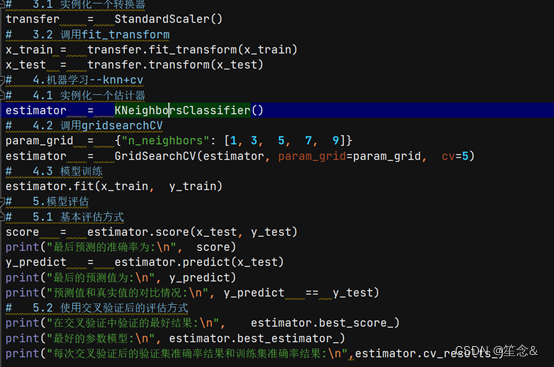
# 1.获取数据集
# 2.基本数据处理
# 2.1 缩⼩数据范围
# 2.2 选择时间特征
# 2.3 去掉签到较少的地⽅
# 2.4 确定特征值和⽬标值
# 2.5 分割数据集
# 3.特征⼯程 -- 特征预处理(标准化)
# 4.机器学习 -- knn+cv
# 5.模型评估
4 代码实现















 663
663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









