







接着前面的学习,前面的预测效果都不太如意,我又继续学习,找问题。心里有个谱,可能是因为有噪声数据,在网上查到,对于时间序列的预测,有个比较好的方式是指数平滑法。
那么什么事指数平滑法呢,我们来看看官方的定义:指数平滑法(Exponential Smoothing,ES)是布朗(Robert G..Brown)所提出,布朗认为时间序列的态势具有稳定性或规则性,所以时间序列可被合理地顺势推延;他认为最近的过去态势,在某种程度上会持续的未来,所以将较大的权数放在最近的资料。据平滑次数不同,指数平滑法分为:一次指数平滑法、二次指数平滑法和三次指数平滑法等。
首先我们来看看一次指数平滑的公式和推导,一次指数平滑法的预测公式为 si=αxi+(1-α)si-1 ,推导过程为:

可以看到,α的取值大小对现在值得影响,α越大, 对临近的数据依赖较大,α越小,对更早数据的依赖越大。 看了很多文档,数α的值是事先取好的,根据依赖程度,取一个合理的范围,然后求预测数据与实际数据平方差平均最小的一个α。然后进行预测。
二次指数平滑法是在一次指数平滑法的基础上再平滑,同理,三次指数平滑法是在二次指数平滑法的基础上再平滑。
我们之间过渡到三次指数平滑法,二次在三次的介绍过程中会有提及,我们来看三次指数平滑法的公式:
计算公式为为: 

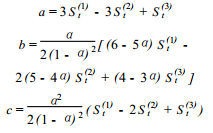
二次指数平滑法的计算公式其实上面也可以看出,他的数学模型为一条直线。y=ax+b。这里就略过了。 现在我们来直接进行三次指数平滑的代码以及最终的图像结果,代码中也包含了二次指数平滑法计算。略微修改就可以进行计算:
<span style="font-family:Microsoft YaHei;"># coding: utf-8
# 三次指数平滑法和二次指数平方
import draw
#st计算
def Calc( alpha , x, lastSt ):
st1 = alpha*x + (1-alpha)*lastSt[0]
st2 = alpha*st1 + (1-alpha)*lastSt[1]
st3 = alpha*st2 + (1-alpha)*lastSt[2]
return [round(st1, 2),round(st2, 2),round(st3,2)]
#指数平滑的数学模型叫2次多项式函数
#Y(t+T) = a(t)+b(t)T+c(t)T^
#其中参数a(t),b(t),c(t)的计算方式为见文档
def ParamCalc(alpha, st):
a = 3*st[0]-3*st[1]+st[2]
temp = alpha/( ( (1-alpha)*(1-alpha) )*2 )
b = temp*( ( 6 - 5*alpha )*st[0] - 2*( 5 - 4*alpha )*st[1]+(4-3*alpha)*st[2] )
temp = ( alpha*alpha )/( 2*( (1-alpha)*(1-alpha) ) )
c = temp*( st[0] - 2*st[1] + st[2] )
return [round(a,2),round(b,2),round(c,2)]
def Variance( stList, yList, number ):
key,sum = 0,0
for y in yList:
temp = stList[key][2]-y
sum = sum + temp*temp
key = key + 1
return sum/number
#st计算,二次指数平滑法
def CalcVT( alpha , x, lastSt ):
st1 = alpha*x + (1-alpha)*lastSt[0]
st2 = alpha*st1 + (1-alpha)*lastSt[1]
return [st1,st2]
def ParamCalcVT(alpha, st):
a = 2*st[0]-st[1]
b = ( alpha/(1-alpha) )*( st[0]-st[1] )
return [a,b]
def VarianceVT( stList, yList, number ):
key,sum = 0,0
for y in yList:
temp = stList[key][1]-y
sum = sum + temp*temp
key = key + 1
return sum/number
#计算误差平方平均,找到最合适的 alpha
#xList = [1989,1990,1991,1992,1993,1994,1995,1996,1997,1998,1999,2000,2001,2002,2003]
xList = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183]
yList = [97, 88, 91, 95, 107, 122, 117, 117, 117, 144, 94, 89, 152, 118, 115, 179, 186, 203, 151, 176, 201, 209, 157, 171, 198, 182, 170, 164, 155, 177, 144, 199, 213, 196, 151, 324, 217, 252, 168, 167, 221, 225, 127, 183, 194, 227, 159, 183, 202, 210, 211, 164, 239, 193, 216, 302, 239, 210, 267, 231, 239, 208, 210, 267, 204, 239, 240, 209, 282, 225, 215, 236, 323, 388, 459, 489, 325, 330, 277, 279, 268, 278, 290, 382, 338, 302, 209, 215, 311, 258, 240, 362, 296, 275, 285, 322, 297, 336, 308, 428, 283, 250, 300, 267, 223, 304, 262, 274, 257, 328, 258, 255, 220, 242, 254, 269, 326, 339, 243, 283, 312, 275, 240, 224, 266, 299, 309, 272, 285, 264, 296, 247, 224, 266, 256, 275, 250, 185, 271, 229, 292, 239, 241, 231, 268, 212, 187, 216, 302, 279, 321, 311, 375, 295, 254, 289, 222, 282, 256, 274, 295, 257, 275, 233, 249, 237, 241, 260, 221, 305, 227, 287, 340, 278, 245, 222, 382, 296, 307, 370, 392, 288, 272]
#yList = [2007,3318,3414,4260,4666,5186,5597,5871,6011,5654,6160,7671,9004,10340,12169]
#xList = [1,2,3,4,5,6,7,8,9,10]
#yList = [2839.87,3004.00,3243.76,4539.00,5251.30,5420.43,6433.54,7892.80,8611.62,9668.42]
number = len(xList)
s01 = (yList[0]+yList[1]+yList[2])/3
s02,s03 = s01, s01
minVariance = 10000
minAlpha = 0.05
lastStList = []
alpha = 0.6
for i in range(0, 7):
alpha = 0.01+( i*0.01 )
firstSt = [s01,s02,s03]
#最终的st列表
stList = [firstSt]
key = 0
for y in yList:
if key > 0:
st = Calc(alpha, y, stList[key-1])
stList.append( st )
key = key + 1
variance = Variance( stList, yList, number )
if minVariance > variance :
lastStList = stList
minAlpha = alpha
minVariance = variance
#获取a,b,c参数
param = ParamCalc( minAlpha, lastStList[len(lastStList)-1] )
print(alpha)
print(param)
#进行数据预测
forcastXList = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183]
forcastYList = []
for work in lastStList:
forcastYList.append(work[2])
#预测后面的5个数值
forcastWork = []
for i in range(1,61):
forcastXList.append( 183+i )
forcastData = param[0]+param[1]*i+param[2]*(i*i)
forcastYList.append(forcastData)
forcastWork.append( forcastData )
#作图
print(forcastWork)
draw.DrawImage( [xList,forcastXList], [yList,forcastYList] )
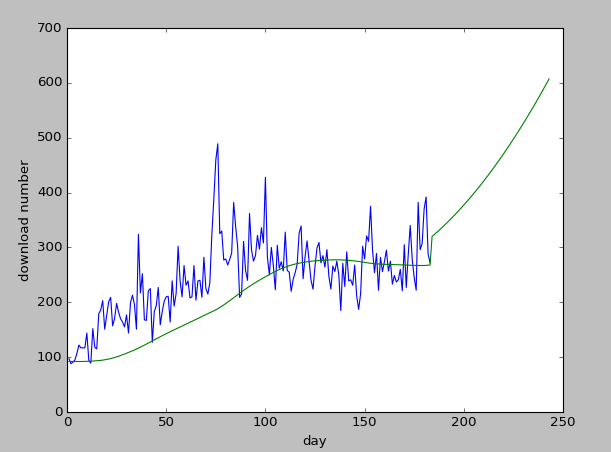
</span>我遇到了一个问题,按照这种方式,我发现不管我的α怎么取,都是越大越好,好奇怪啊,但是越大的话,那些预测线条也太不靠谱了。我首先取了一个小的范围,0.1~0.7.结果算出来0.7误差最小,好奇怪。下面是做出来的图像,后面的是预测值:
后面我有取了一个较大的范围,0.5~0.8.但是预测的值也太扯了,拟合的效果倒是挺好的,这就是传说中的过拟合吗:
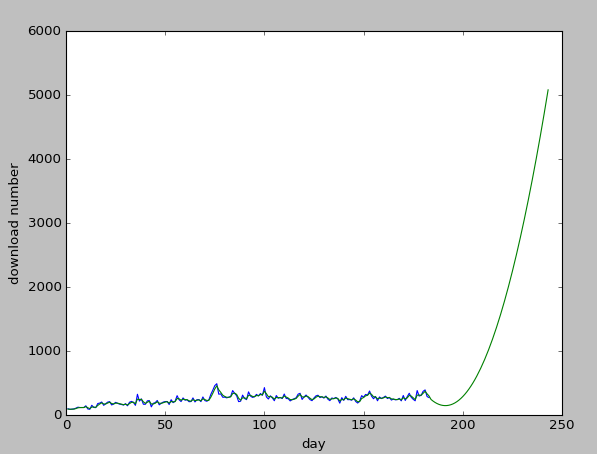
问题:这算是过拟合吗,为啥会出现这种情况,看来我的继续研究。
在研究的过程中,我在很多文章中发现时间序列数据一般有以下几种特点:1.趋势(Trend) 2. 季节性(Seasonality)。三次指数平滑法保留了很好的季节性,我仔细思考了下,我的数据都是短期的,那里来的季节性,所以降级到了二次指数平滑法,但是效果任然不太理想。
在这里吐槽下,百度文库中的很多文档都有介绍这个,但是按照他们的公司计算,他们的数据都合不到,数据我找了好几个,一个都不行。
可能我的代码也有问题,希望看到的人能够指正,因为这么多,没有一个合用,我现在彻底被噪声数据 和 过拟合干扰到了,哎,没办法,只有继续研究
下面我们将继续使用ar|ma。来看看效果如何。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









