









一, 题目
《An Effective Transition-based Model for Discontinuous NER》
论文:An Effective Transition-based Model for Discontinuous NER.pdf
代码: https://github.com/daixiangau/acl2020-transition-discontinuous-ner
**实验数据:**https://data.csiro.au/dap/landingpage?pid=csiro:10948&v=3&d=true
**引用:**Xiang Dai, Sarvnaz Karimi, Ben Hachey, and Cecile Paris. 2020. An Effective Transition-based Model for Discontinuous NER. In ACL, Seattle, Washington.
二,作者
Xiang Dai1*,*2 ,Sarvnaz Karimi1,Ben Hachey3 ,Cecile Paris1
1CSIRO Data61, Sydney, Australia:澳大利亚联邦科学与工业研究组织 Data61部门
2University of Sydney, Sydney, Australia:悉尼大学(USyd)
3Harrison.ai, Sydney, Australia:澳大利亚科创企业Harrison. Ai,是一个利用AI来解决生物基因的公司
三,摘要
提出了transition-based模型,在没有牺牲连续实体准确率的性下有效地识别了不连续实体。
flatmodel被理解为:普通的采用序列标注相关技术的模型
四,解决的问题:非连续性实体
相对于传统,==基因与生物领域所涉及的NER、专有名词,在句子中出现并不是不连续的,这里叫做非连续实体训识别。==传统的Markov假设在处理不连接实体识别显得不成立了。

五,场景
NER很重要。例如在药物警戒方面(pharmacovigilance),处理消费者在论坛上讨论的不良药物事件,警示药物的开发,调整,临床应用。在临床上,NER用抽取电子病历。在基因领域出现的不连接实体的抽取也很重要。
5.1 概述
flatModel的两个假设
(1) mentions do not nest or overlap(mentions不可以嵌套或重叠,每一个token都至少属于一个mention) ;
(2)mentions comprise continuous sequences of tokens(mentions是由连接的token序列组成);
a. 面临的问题与挑战
a.1.不满足这两假设
违反第一个假设: Nested entity recognition—嵌套实体
违反第二个假设:discontinuous mentions --不连接实体—这个研究比较少
连续与非连续区别:前者mention相对比较短,后者会长,且它是由一些间隔分开的多个小部分组合而成(discontinuous mentions consist of components that are separated by intervals)。
a.2 挑战
由于要列举出所有可能的mentions(包非连续性span与重叠span),这些枚举与句子的长度呈指数增长的。另外,这个过程时间复杂度高,解码时也容易产生mentions歧义。
a.3 目前对不连续NER的解决方案
| 题目 | 缺点 | 来源 | 年份 |
|---|---|---|---|
| Flexible text segmentation with structured multilabel classifification | 高时间复杂度 | EMNLP | 2005 |
| Recognizing clinical entities in hospital discharge summaries using structural support vector machines with word representation features | 将中间表示转化为提及存在歧义 | In BMC Med Inform Decis Mak | 2013 |
| Concept identifification and normalisation for adverse drug event discovery in medical forums | 转化歧义 | In BMDID@ISWC | 2016 |
| Learning to recognize discontiguous entities | 转化歧义 | EMNLP | 2016 |
目前采用的方法特征还是基于手动去处理。
5.2 动机
组合概念与分拆出来各自概念意思不同;不连续实体的另一个重要特征是他们是部分重叠的,即存在几个提及可能会共享某部分。
5.3 贡献
提出end-to-end的transition-based模型;模型使用指定的action与关注力机制去决定一个span是否是非连续提及的一部分。
采用了三份包括大量不连续实体的生物医学数据进行实验,实验显示在含不连续实体识别的情况下对不连续实体有很好的效果。
6. 相关工作
6.1 解决discontinuous问题方法
- token level—基于序列标记的方法;
- sentence level–在一个句子中多个mentions被联合预测组合;
- As a structured multi-label classifification problem–把discomtinous NER的问题看成一个结构化多标签分类问题。
- transition-based models – shift-reduce parser
6.2 token级
vanilla BIO(原始的BIO)对于overlapping,discontinuous都是很难表达的,所以,
通过扩展BIO标签集来解决非连续实体问题。
| 题目 | 年份 | 出处 |
|---|---|---|
| Concept identification and normalisation for adverse drug event discovery in medical forums | 2016 | BMDID@ISWC |
| Recognizing clinical entities in hospital discharge summaries using structural support vector machines with word representation features | 2013 | In BMC Med Inform Decis Mak |
| Medication and adverse event extraction from noisy text | 2017 | ALTA |
| Recognizing continuous and discontinuous adverse drug reaction mentions from social media using LSTM-CRF | 2018 | Wirel Commun Mob Com |
例如,如下的增加:
• BH: Beginning of Head, defined as the components shared by multiple mentions;
• IH: Intermediate of Head;
• BD: Beginning of Discontinuous body, defined as the exclusive components of a discontinuous mention;
• ID: Intermediate of Discontinuous body
6.2 句子级—超图方法
句子级别方法不预测每个标记是否属于实体mentions及其在mentions的分类,而是预测句子中多个mentions的组合。对于这个问题通过超图方法去解决,使用一个子图来表达句子中的mentions的组合.
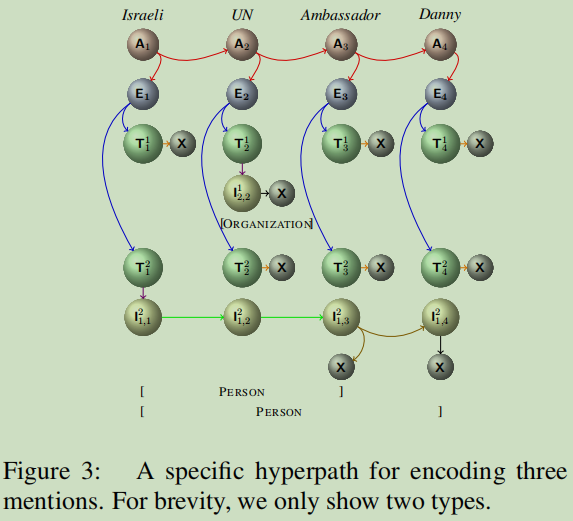
图来自【4】
• A: mentions that start from the current token or a future token;
• E: mentions that start from the current token;
• T: mentions of a certain entity type that start from the current token;
• B: mentions that contain the current token;
• O: mentions that have an interval at the current token;
• X: mentions that end at the current token.
引用【3】的来帮助理解:
5种类型的节点组成:
Ai :编码所有这些以第i个或后面的单词开头的实体。
Ei :编码所有以第i个单词开头的实体。
Tki :表示以第i个单词开头的k类型的所有实体。
Iki,j :表示包含第j个单词并以第i个单词开头的k类型的所有实体。
X:标志着一个实体的结束。两种方法首先预测第一个中间的表达,然后解码出最后的mentions.
关于边:
1、从Ai到它的子代的超边{Ai→(Ai+1,Ei)}意味着Ai包含了要么“从第i个词开始”(Ei),要么“从严格出现在第i个词之后的词开始”(Ai+1)”的实体。
2、从Ei到它的子代的超边{Ei→(T1i,…,Tmi)}意味着我们考虑以第i个词开头的实体(可能长度为0)的所有可能类型。
3、Tki的两个超边{Tki→Iki,i}和{Tki→X}表示至少存在一个以第i个词开头的实体(前一个超边),或者没有任何此类提及(后一个超边)。
4、来自Iki,j的三个超边{Iki,j→Iki,j+1},{Iki,j→X},和{Iki,j→(Iki,j+1,X)}分别表示以下三种情况:1)第j个词和第(j+1)个都属于以第i个词开头的至少一个实体;2)存在一个以第i个词开头以第j个词结尾的提及;3)这两种情况它是有效的。
总结: 两种方法都是通过首先预测mentions中间表达(前面的基于一串标注序列;后面的是建立一个子图),然后通过解码出最后的mentions; 可是有一个缺点,在解码时,会出现歧义。
##本论文提出的transition-base模型也采用中间表达的方式,这里的中间序列是“a sequence of actions”(一系列动作),但可以解决解码歧义这个缺点。##经过一组动作解码出没有歧义的实体mentions.
6.3 structured multi-label classifification problem
| 题目 | 年份 | 来源 | ||
|---|---|---|---|---|
| Flexible text segmentation with structured multilabel classifification | 2005 | EMNLP | Canada | |
| Combining spans into entities: A neural two-stage approach for recognizing discontiguous entities | 2019 | EMNLP | China | 基于分类器首先检测所组成部分,然后合并这些部分形成不连续实体。 |
| Recognizing continuous and discontinuous adverse drug reaction mentions from social media using LSTM-CRF | 2018 | Wirel Commun Mob Com |
优点:灵活,像非连续mentions一样灵活,可以随意组合。
缺点:高时间复杂度。
从论文Flexible text segmentation with structured multilabel classifification中理解一下多标准分类问题,如下为overlapping与不连续NER的例子:

对于这个例子,每对于一个实体,都对应着一组标注序列:

6.4 不连续NER vs 嵌套NER
两都的相同点都是含有overlapping的部分,而区别就是overlapping的方式 。
如果某个mention被别一个mention完成包含了,这种情况就可以叫嵌套NER了。而不连续NER,是两个mention有overlap,不是一个mention完全包含另一个metion。
6.5 基于转换的模型
基于shift-reduce解释器包括stack与buffer容器;stack主要用来储存处理之后spans,buffer用来储存未处理的tokens.
给定解释器的状态,预测用于更改解释器状态的action,重复这个过程直到解释器的终结状态。(例如stack与buffer都空。)
| 题目 | 来源 | 年份 | 动作 |
|---|---|---|---|
| Transition based neural constituent parsing | ACL-IJCNLP | 2015 | SHIFT, REDUCE, UNARY,FINISH,IDEA |
| Neural architectures for named entity recognition | NAACL | 2016 | SHIFT, REDUCE,OUT |
七, 模型
7.1 设计action集
本论文与上面两个shift-reduce不同点是在transition action集上。
【Transition based neural constituent parsing】使用SHIFT, REDUCE, UNARY,FINISH, and IDEA;
【Neural architectures for named entity recognition】使用了SHIFT, REDUCE,OUT.
本论文设计了6个元素的action集:
• SHIFT moves the first token from the buffer to the stack; it implies this token is part of an entity mention.
• OUT pops the first token of the buffer, indicating it does not belong to any mention.
• COMPLETE pops the top span of the stack,outputting it as an entity mention. If we are interested in multiple entity types, we can extend this action to COMPLETE-y which labels the mention with entity type y.
• REDUCE pops the top two spans s0 and s1 from the stack and concatenates them as a new span which is then pushed back to the stack.
• LEFT-REDUCE is similar to the REDUCE action, except that the span s1 is kept in the stack. This action indicates the span s1 is involved in multiple mentions. In other words,several mentions share s1 which could be a single token or several tokens.
• RIGHT-REDUCE is the same as LEFT REDUCE, except that s0 is kept in the stack.
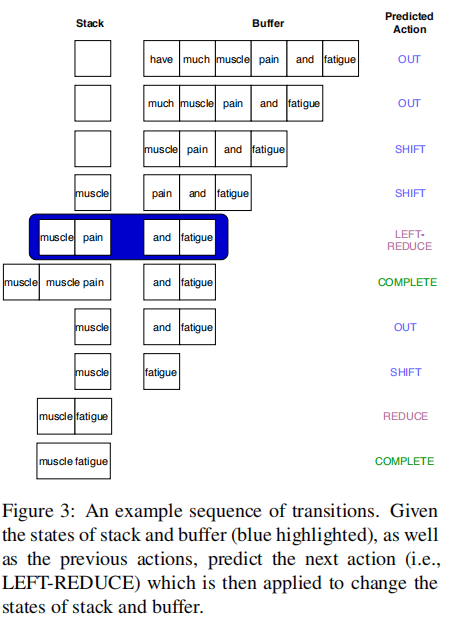
7.2 解释器的状态表达 (Representation of the Parser State)
Bi-LSTM参考于【Speech recognition with deep recurrent neural networks】,字符级通过CNN来嵌入【End-to-end sequence labeling via bi-directional LSTM-CNNs CRF】,表示第i个token的表示:
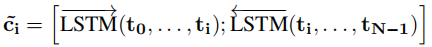
把elmo【Deep contextualized word representations】的上下文向量也拼接加入:
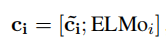
这里构成的C表达,构成了tokens在buffer的状态。
这里也研究过Bert模型,可是Bert模型并没有ELMo的效果好。
用Stack-LSTM来表示stack中的spans.(stack-LSTM结构来自【Transition based dependency parsing with stack long shortterm memory】), 如果一个token从buffer中移到stack中,它的表示为:
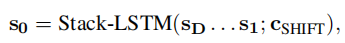
REDUCE,即两个spans合成一个新的span,这个就是两个mentions的合并成新的mention操作:
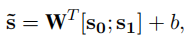
7.3 捕获非连续性依赖(multiplicative attention)
spans与tokens的相互作用是识别非常连续mentions重要因素。
通过乘法关注力机制【Effective approaches to attention-based neural machine translation.】去捕获这个互动与依赖的特征:
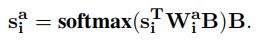
具体过程是利用stack中的si去找所有buffer中token的关系,最后得到一个加权和。
意思是说:看一下stack中的元素与buffer中元素关系密不密切,通过这个关系程度来决定下一次应该进行什么动作。
7.4. 选择一个Action
构建解释器的表达(两部分合并而成): (s0, s1, s2,s0a, s1a, s2a)
第一部分:stack中top3的spans表达;
第二部分:spans对应的注意力表达。
Action是通过单向LSTM来学习训练出来作为表达。
最后通过输入一个softmax作为预测层来选择下一个action.
这里具体是怎样的网络没有看明白。。。
八,实验
8.1 数据集
CADEC【https://www.askapatient.com/】:实体类型包括drug, Adverse Drug Event (ADE), disease,symptom,可是只有ADE包括了非连续实体,其它没有,故不用。与【Concept identifification and normalisation for adverse drug event discovery in medical forums.】,【Recognizing continuous and discontinuous adverse drug reaction mentions from social media using LSTM-CRF】作对比。
ShARe 13,ShARe 14 【MIMIC-III, A freely accessible critical care database】:关注临床的disorder mentions; 包括discharge summaries(出院小结), electrocardiogram(心电图), echocardiogram(超声波心动图), radiology reports(放射学报告)等.
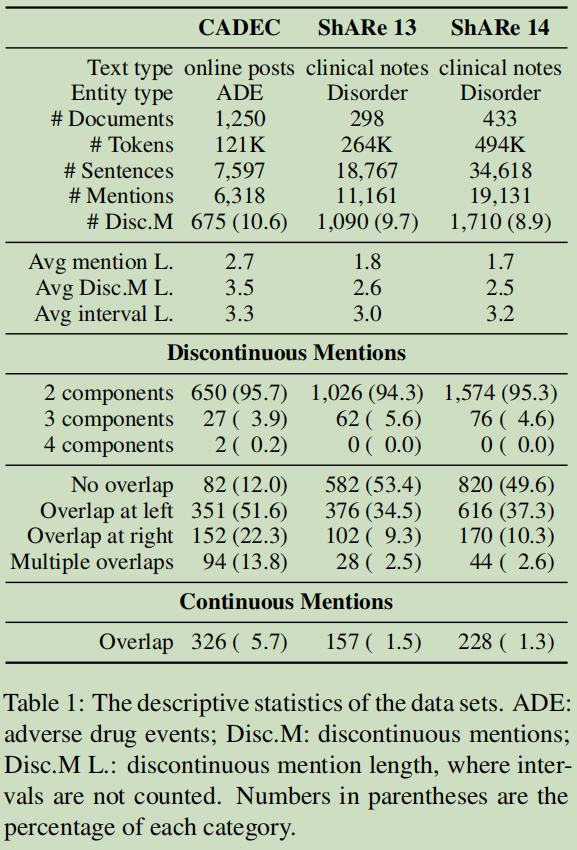
CADECGN与ShARe的区别:CADECGN倾向于使用习语来描述他们的感受—LAYMAN; ShARe则倾向于使用紧凑的术语来进行有效的沟通-- professional practitioners。
8.2 实验设置
CADEC数集划分:training set–70%; development set–15%;test set – 15%;下载地址:https://github.com/daixiangau/acl2020-transition-discontinuous-ner
Evaluation: F1
8.3 Baseline与结果
选择1个Flat model与2个discontinuous NER models作为Baseline.
Flat: 基于【Stanovsky et al., 2017 – Recognizing mentions of adverse drug reaction in social media using knowledge-infused recurrent models】实验, 稍微修改了训练数据;
BIO extension model:基于【Metke-Jimenez and Karimi, 2016–Concept identifification and normalisation for adverse drug event discovery in medical forums】的模型修改了,把CRF模型改成了 BiLSTM-CRF-ELMo;
Graph-based model: (Muis and Lu, 2016)【Learning to recognize discontiguous entities】,原论文只report了都含有非连续mentions的句子的评估结果。这里是对整个测试集进行训练及测试。把这个结论推向现实,在现实中,不会这么理想,不可能只带有非连续mentions的句子集的, 还包含很多连续的mentions的。
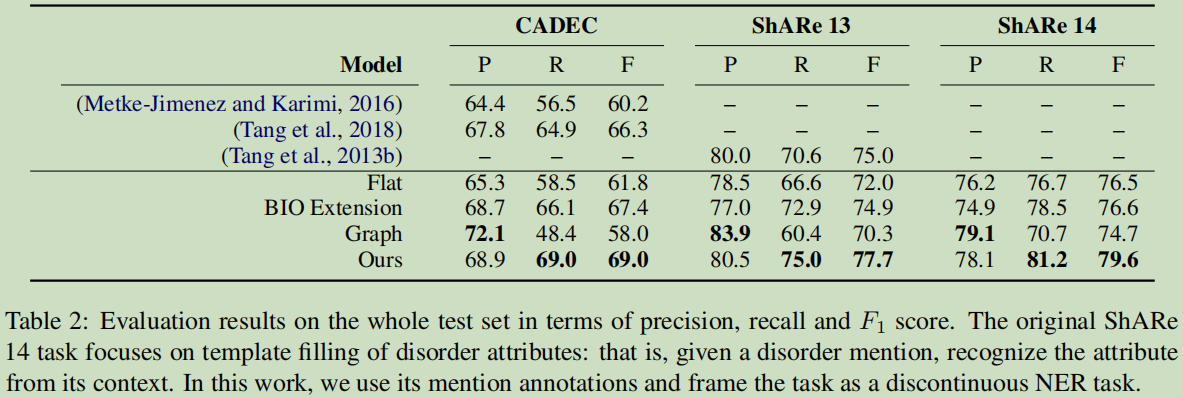
基于Graph的模型正确率还是比较高的,可是它的召回率比较偏低的。而这个模型并没有牺特征正确率去提升召回率。
九,分析
9.1 识别不连续mentions的有效性
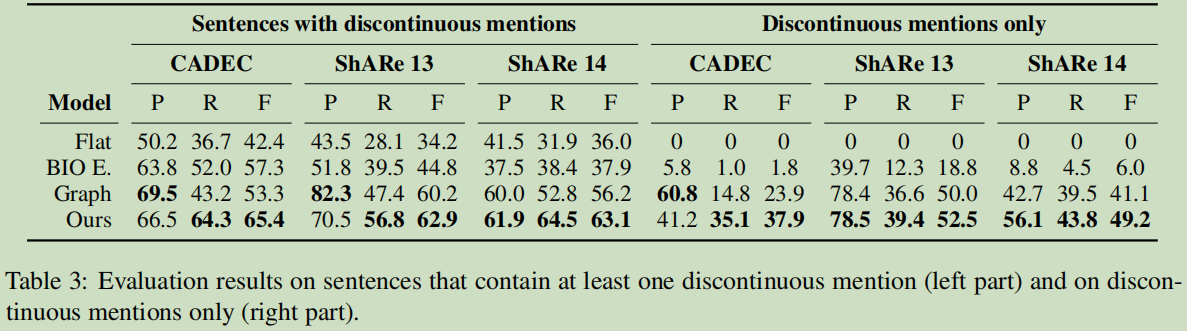
Left: 每个句子中都带有一个非连续的mentions.这个是【Learning to recognize discontiguous entities】论文的实验内容;
Right: 更进一步把连续的mention全部去掉,只留下非连续的mentions了。
可以看出对于非连续mentions的学习还是很好。
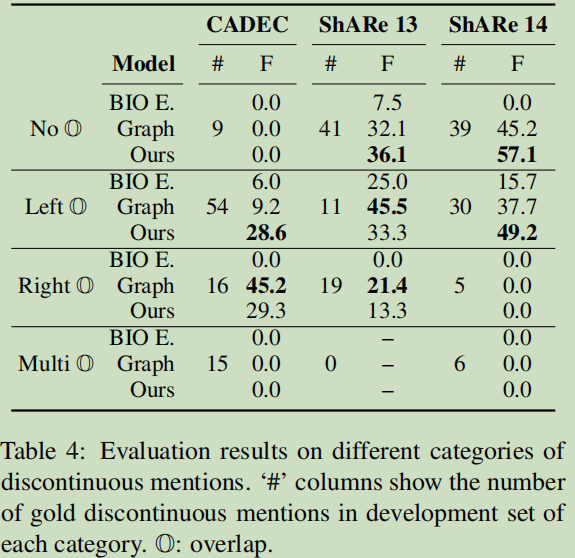
9.2 Characteristics of Discontinuous Mentions(不连续的特征)
一般,不连续mentions比较连续mentions的长度要长,总四类特征:No overlap, Overlap at left,Overlap at right,Multiple overlaps.

9.3 Impact of Overlapping Structure(重叠结构的影响)
本论文的模型:对于没有overlap与Left overlap的mentions有很好的效果;
Graph-based model:对于right overlap有好的结果。
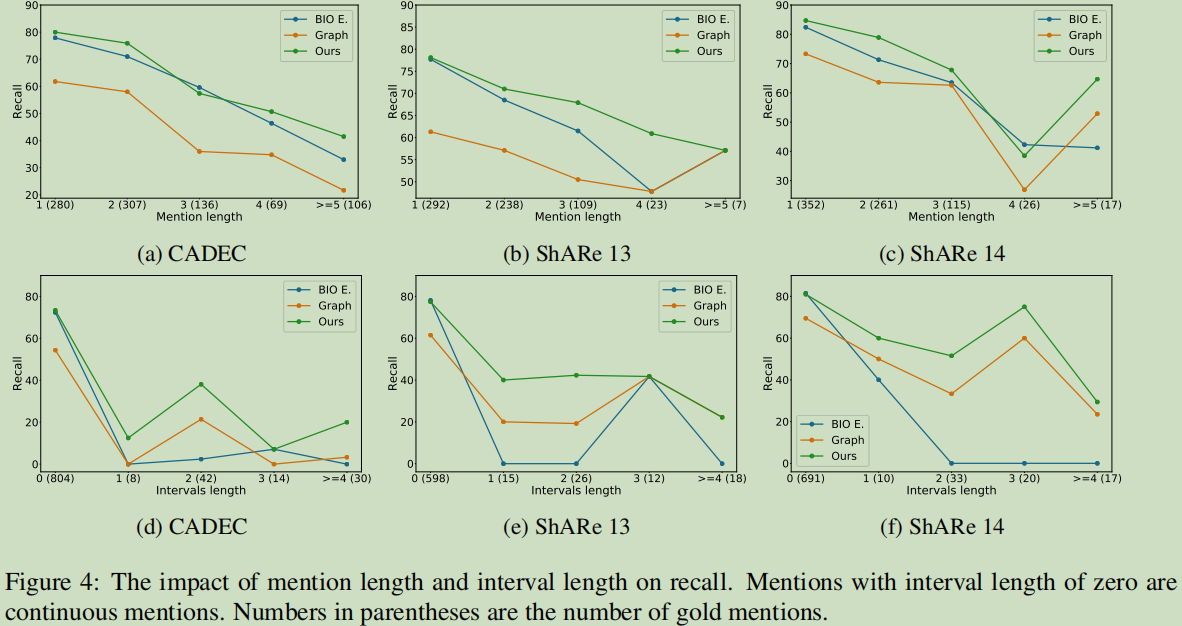
9.4 Impact of Mention and Interval Length(Mention与间隔长度的影响)
长度的影响不是很明显。
十,总结
基于transition-based框架这上,修改action集,对于框架各个环节进行建模改进,取得很好的效果。同时,也对提出的模型作了评估,依目前来看,大体上transition-based还是好一点,另外graph与transition-based还是有得比较。或者有图上面加入一些传播机制是否会有进步(第10篇与第11篇的内容,第9篇中对这个模型进行了简化的)。
这篇论文是第二次看了,之前的一次读完,对于transition-based有了全局的认识,可是没有深入transition-based在解决非连续NER的应用方面的思考,这次作了一个更深一点的学习。
可是,仍然是未有深入到模型的具体细节,例如Stack-LSTM,基于多标签分类等内容还未来得及去看。
anyway,对于在工程方面与现在做的工作还是有很大的帮助。
happyprince,https://blog.csdn.net/ld326/article/details/112968947
参考
【1】[论文笔记]一种高效基于转移的不连续命名实体识别模型,https://zhuanlan.zhihu.com/p/162018769
【2】详解Transition-based Dependency parser基于转移的依存句法解析器,https://mp.weixin.qq.com/s/dIQoNRtZcm2TL_XQldIhaA
【3】《Hypergraphs for Overlapping Mention Recognition》,https://zhuanlan.zhihu.com/p/130680523
【4】Wang B , Lu W . Neural Segmental Hypergraphs for Overlapping Mention Recognition[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018.
Vanilla Neural Networks : Vanilla本意是香草,在这里基本等同于raw.
NP-chunking:noun phrase chunking;分块是entity detection的基础;这种块通常比完整的名词词组小,例如:the market for system-management software是一个名词词组,但是它会被分为两个NP-chunking——the market 和 system-management software。任何介词短语和从句都不会包含在NP-chunking中,因为它们内部总是会包含其他的名词词组。














 149
149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









