










一,题目
Recognizing Complex Entity Mentions:A Review and Future Directions
识别复杂实体mentions:回顾与未来方向
Dai X . Recognizing Complex Entity Mentions: A Review and Future Directions[C]// The ACL 2018 Student Research Workshop. 2018.
二,作者
Xiang Dai
CSIRO Data61 and School of IT, University of Sydney
Sydney, Australia
悉尼大学
三,摘要
对可处理复杂实体mentions识别的方法作一个综述回顾,作了分类(token层,句子层),研究了下一步的方向。
四,遇到什么问题?什么复杂实体?
NER很重要,它是很多下游的基础。
传统NER识别定义为给一串tokens,输出一串三元组(开始位置,结束位置,类型);这种方法的成立条件为:a. 一个NE的Mentions是连接的;b. mentions之间不重叠;
传统NER的最常用标注:使用BIO或BIOLU标注集对一个句中的tokens进行标注,标注带有这个实体的类型信息。
传统NER的最常用模型:线性CRF,BiLSTM-CRF
可是,实际情况:nested(嵌套), overlapping(重叠), discontinuous(不连续) NE mentions <==定义为==> complex entity mentions,具体有如下四种情况:
Nested NE mentions : 一个NE mentions被另一个完全包含。
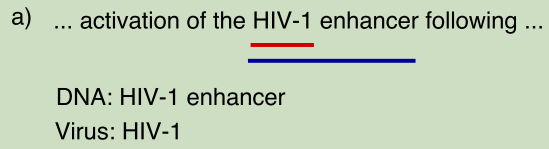
Multi-type NE mentions: 一个NE mentions有两个类型。可以理解为Nested NE的一种极端情况,Mentions A与Mentions B互相包含。即一个实体Mentions却充当着两类角色,最后会被考虑成是两个Mentions。
例如EPPI语料:proteins(蛋白质)是drug(药),也是compound(化学成份).作为药时,蛋白质可以对细胞是起作用的。
Overlapping NE mentions: Mentions A与Mentions B有交集,可是不存在哪个完成包含另一个。

Discontinuous NE mentions: 由不连接的Tokens组成一个实体mentions的。
例如上面的“intense plevic pain”,这个实体mention是分开地在句子中存在的,即“intense pelvic”与“back pain”.
五,基于Token的方法
把基于序列标注的一系统方法定义为基于Token的方法,典型的为线性CRF:
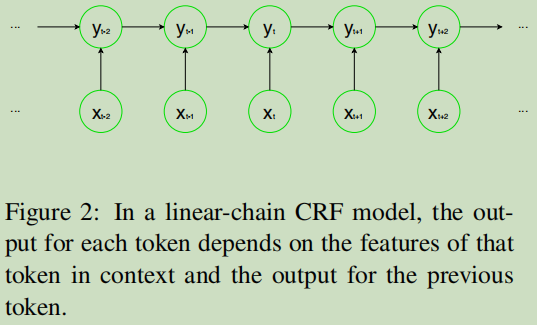
基于Token方法的考虑,既然现在的标注不满足当前的复杂实体mentions,就扩展标注集合。
Metke-Jimenez and Karimi (2015): Concept extraction to identify adverse drug reactions in medical forums: A comparison of algorithms
BIO模式变种,试图去表达非连接的与重叠的NE Mentions,在BIO的基础上加入{ BD, ID, BH, IH},对BI这两个标注的非连接与重叠的扩展;
BD:Beginning of Discontinuous body— 定义一个不连接mentsions的独立的部分;
ID:Inside of Discontinuous body
BH:Beginning of Head – 定义了被多个mentions共享的部分;
IH:Inside of Head
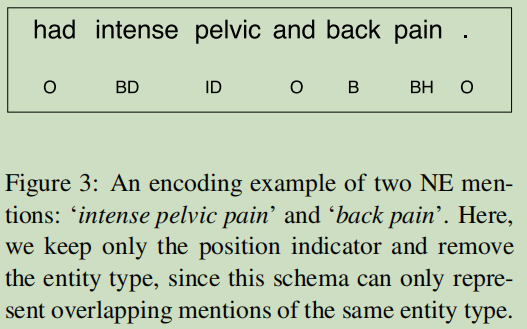
缺点:就算是上面那个这个简单的例子,这种方法却没有很好的标注出来,对于各个mentions在一起时,这个是不可的了。
Muis and Lu (2016):介绍了model ambiguity这个概念,从理论上证明了基于BIO的模式一般具有很高的歧义性,故在实际的使用中具有比较低的正确率。另外还有一个局限性,BIO只支持单个类型的重叠的情况。
Schneider et al. (2014): Discriminative lexical semantic segmentation with gaps: Running the mwegamut
BIO模式变种,解决不连续的多词与嵌套的问题,加入了两个比较严格限制:
a. 一个表示被另一个表示完成包含,但是不重叠;— 即是嵌套
b. 这个嵌套结构最多只能有两层。
显然,这个假设也太严格了。对于复杂的现实环境还是比较难满足这个限制的
Alex et al. (2007) :Recognising nested named entities in biomedical text
基于最大熵模型提出了三个方法去解决nested实体mentions问题。
方法1: Layering(分层方法)
识别器首先识别最内层或最外层的mentions,然后再去识别最内层或最外层的下一层的mentions,最后输出不同的标注结果并作一个联合。
方法2: Joined labeling
每个词被赋以多层合并起来的标签,然后标注器去训练这些合并的标签,在预测时再把相应该的标签解码回去。
方法3: Cascade
对于每个实体类型采用单独的模型去训练,模型使用前面模型的结果作为特征输入到后面的模型中去。虽然很难去分类与分组实体模型,可是这个效果在这三个方法中是最好的。
Byrne (2007): Nested named entity recognition in historical archive text
Xu et al. (2017):A local detection approach for named entity recognition and mention detection
两个采用相似的方法处理Nested问题。具体方法把可能的相邻的tokens连接起来形成可能的spans.然后这个spans与左右相邻的tonken一起送入到分类器中,分类器判断是否是一个mentions,当判断为mentions后,判断其类型。
六,基于Sentence的方法
不是预测某个token或几个token属于某个mentions或者是预测mentions的分类,而是直接预测在一个句子中NE mentions的一个组合体。
McDonald et al. (2005):Flexible text segmentation with structured multilabel classifification
提出结构化多标签分类,不用开始与结束的索引去处理这个问题,而是用一组token位置集去表示NE mentions.

每个token使用IO方案去标注,优点,这个表示十分灵活。解码的时候,可以解码出所有可能的标注,歧义性比较低。缺点,时间复杂度大。
Finkel and Manning (2009):Nested named entity recognition
使用一个判别式句子成份分析器去识别nested NE mentions, 把句子表示成一棵句子成分分析树,每个mentions对应着树上的一个短语,另外每个节点需要在标注加上它的父及祖先的标注,以致CRF-CFG可以学习到NE mentions的嵌套情况。
Ringland (2016): Structured Named Entities
使用了Berkeley 分析器去研究了一个联合模型,展示出在没有使用特定的NER特征的情况下也可以达到很好的效果。
采用分析器方法的缺点:时间复杂度大,高质量的分析训练数据;
Lu and Roth (2015) ,Muis and Lu (2016):Learning to recognize discontiguous entities
提出了一种超图的方法。这些模型的训练目标是最大限度地提高由句子和提及编码超图组成的训练实例的对数可能性。 在推理阶段,模型将首先预测完整超图的所有可能的子超图中的一个子超图,并且预测的提及可以从输出子超图中解码。
缺点:在解决阶段,容易出现歧义。
七,总结
复杂实体的缺点:
a. 缺泛表示能力;
b. 计算的时间复杂大;
基于token的方法一般用在处理只有一种nested NE或不连接NE mentions的情境,对于多种复杂的情况不建议使用。
基于句子的方法,它比较灵活,也比较准确,可是它的时间复杂度却是比较高的。
提出的方向:
a. 降低时间复杂度;
b. 把Sequence-to-sequence的模型框架利用到NE的任务中,可以在预测阶段预测多个标注序列来解决这个问题;
c. 语料标注高成本,故主动学习是一个方向;
d. 基于char或采用联合模型去学习;
采用现成的含有复杂实体的数据(GENIA,CADEC,SemEval2014,ACE,NNE)去训练,使用标准的评估的指标(micro-average
precision, recall and f1-score)去评估提出的方法,另外由于复杂实体的复杂性,可以提出一个宽松的方法例如部分匹配或近似匹配来评估这些方法的有效性。
文章的思想很单一,就是对于某种NER实休的简单回顾,回了两大类方法,总结了这些方法的优缺点,解决这个特殊问题的方法不是太多,就得这两三种,加上之前看了一篇基于转移模型的非连接实体命名识别。大的方向,基于标签的扩展定义,句法成份分析,多分类,超图模型,转移等几个方法。其实这里面的核心是要基于图来处理这个问题了,可以认为这是一个升维的思路。【2】中的DYGIE,基于图的提出来之后,关于Overlapping的实体得到了一定程序的改进。
参考:
【1】[论文阅读笔记12]An Effective Transition-based Model for Discontinuous NER, https://blog.csdn.net/ld326/article/details/112968947
【2】[论文阅读笔记10]A General Framework for Information Extraction using Dynamic Span Graphs, https://blog.csdn.net/ld326/article/details/112802292
by happyprince.https://blog.csdn.net/ld326/article/details/113395265















 1439
1439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









