







1. 题目
ACL20-《MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification》。
论文下载地址:https://arxiv.org/pdf/2004.12239
论文开源地址:https://github.com/GT-SALT/MixText
2. 作者
Jiaao Chen Georgia Tech jchen896@gatech.edu 佐治亚理工学院(世界排名33)
Zichao Yang CMU zichaoy@cs.cmu.edu 卡内基梅隆大学
Diyi Yang Georgia Tech dyang888@gatech.edu 佐治亚理工学院
3. 摘要
使用带有TMix数据增强的MixText半监督方法去文本分类,超过了state-of the-art的水平。
动机:从两个隐藏向量的插值中解码会产生一个新句子,新句子混合了两个原始句子的含义。
4. 模型
以前的一些半监督模型:
(1)variational auto encoders (VAEs):变分自编码重构句子;
(2)鼓励模型对无标注的数据输出预测置信度—自训练;
(3)数据增强或加入对抗噪音后执行一致性训练;
(4)大规模数据预测训练,然后再用带标注数据进行微调;
缺点:这些方法,容易出现过拟合。
TMix:
本文的方法受Mixup的启发,提出了TMix,TMix是文本隐藏空间中的插值(interpolation in textual hidden space)。
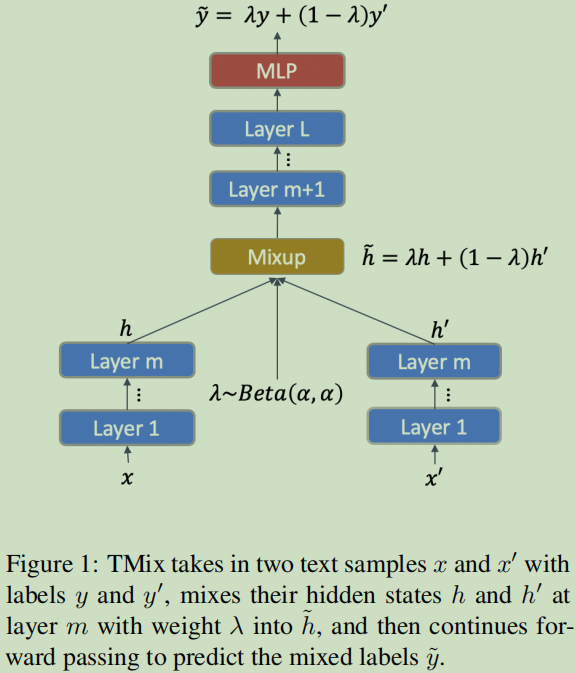
输入两个样本x与x’,y与y’, 首先计算x,x’的隐表示,然后在它们隐表示空间对输入样本进行混合处理。这样就可表示出无穷多个新数据了,因此也是可以防止过拟合。
低层的编码:
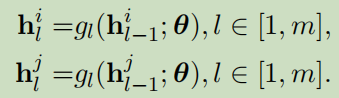
gl(.)表示编码网络;l表示层。
高层混合:
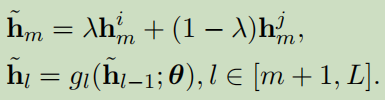
这个公式的意思为:第m层进行对混合,然后再向高层计算直到L层。
TMix总体表达公式为:
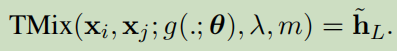
整过过程看成关于TMix(.)函数的计算,g表示编码模型(例如神经网络编码或者某个编码函数), λ表示混合参数,每batch的数值获取来自Beta分布:
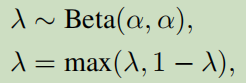
α是分布的超参。
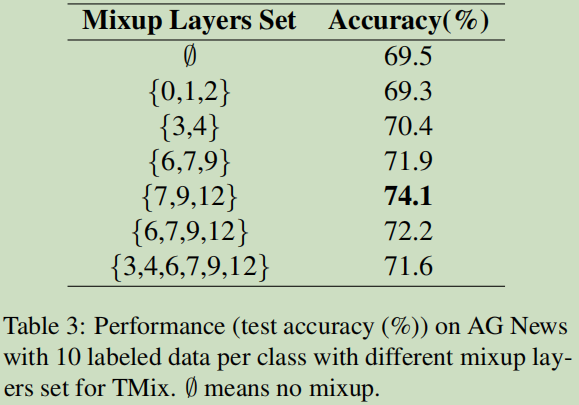
另外,论文在实验时,采用bert来作为句子的编码器,并在选择数据层输出时,选择了 M = {7, 9*,* 12*}*. 选择依据时按照之前的bert分析结论来获取,这样选择会更侧重于句子的句法与句义。同时论文也做了实验去决定为什么选择这三层:
TMix主要是做数据增加,它所可以做的下游任务可是文本分类,或者其它的任务。
**MixText**分类模型
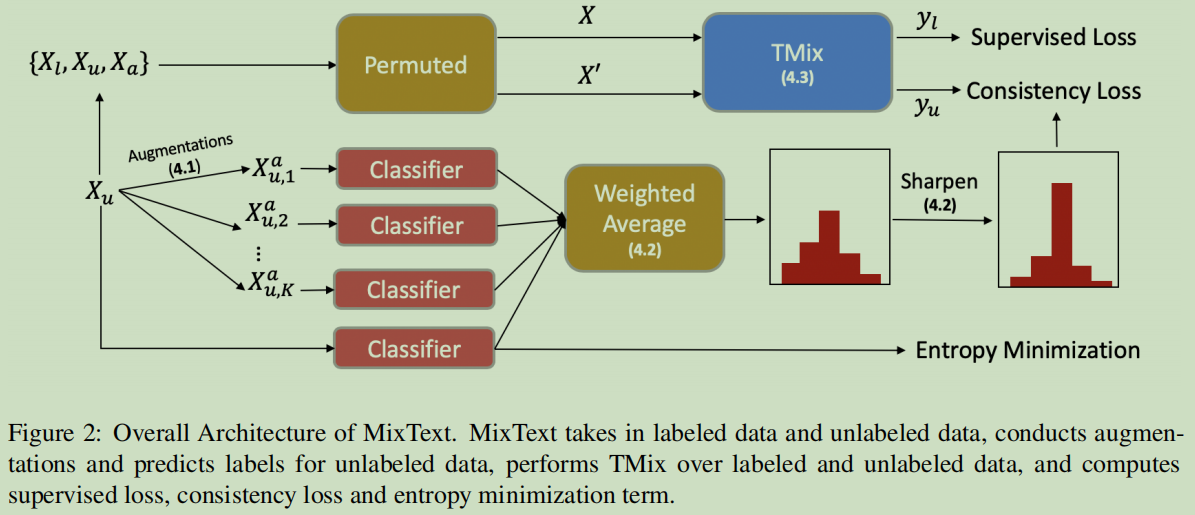
基于这种数据增加的方法,提出了文本分类模型MixText,MixText的核心Idea是基于标注与无标注数据之前的半监督学习:
首先对于未标注数据预测一个低熵标签;
然后使用TMix去混合标注的与无标注的数据。—使用了数据增加技术
MixTex挖掘训练样本之间的隐关系,并把从非标注数据中学习到信息应用到标注数据中进行训练。
MixText的组成部分
a. Data Augmentation—数据增强
Back translations (回译方法),每条无标注句子通过回译的方法生成k句。
b. Label Guessing – 标签猜测
加权平均来获取y,然后为了防止平均过于单一,这里选择Sharpen(.)函数预测标签。

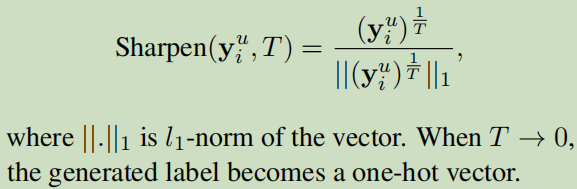
这个是对于无标注数据增强后的处理方法,这里的p表示模型预测出来的概率。
c. TMix on Labeled and Unlabeled Data–合并标签与无标签数据。
随机选择两个句子输畋到TMix(.)函数中进行混合,使用了KL-divergence作为损失函数:
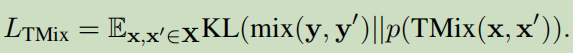
上面的采样具有很大的随机性,根据选择数据不同,可以分为两类:
当数据都是来自标注数时,这个时候叫做:Supervised loss – 监督损失函数
当数据从无标注数据或增强后的数据中采样时,叫做:Consistency loss–一致性损失
d. Entropy Minimization – 熵最小化
为了使用模型对于无标注数据输出可信的标签,提出了最小化预测的概率熵作为自训练的损失函数:
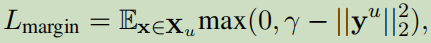
最后的损失函数为:
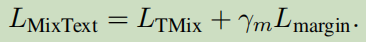
5. 实验结果
数据集
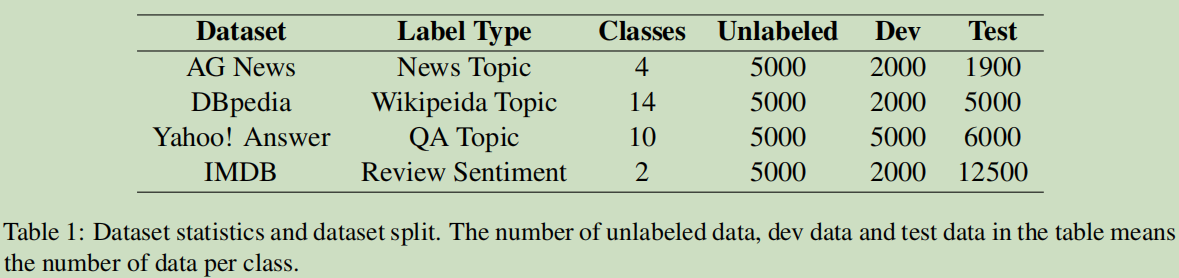
运行结果:
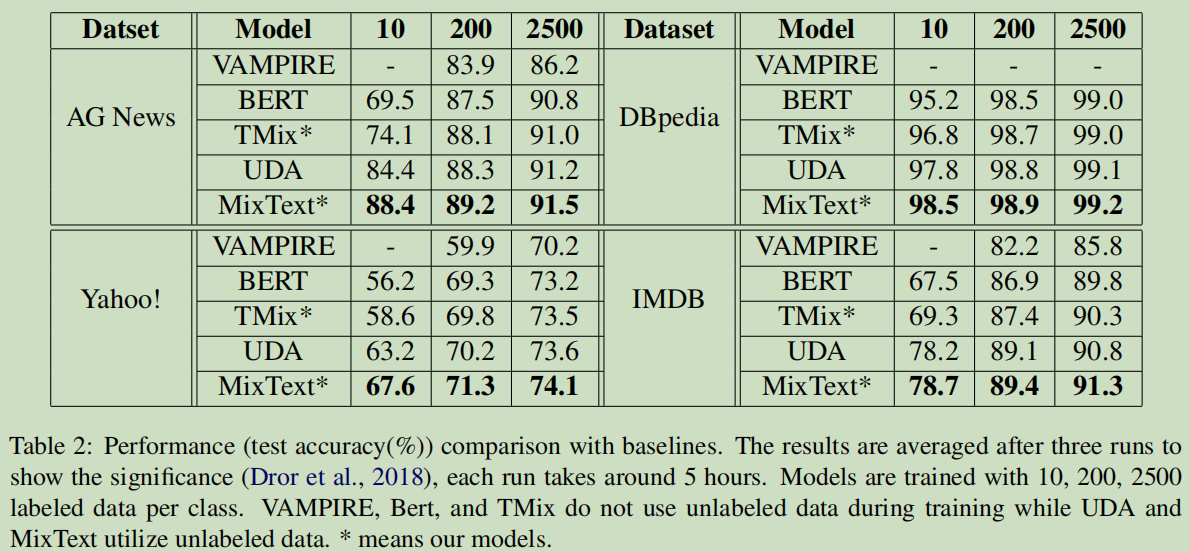
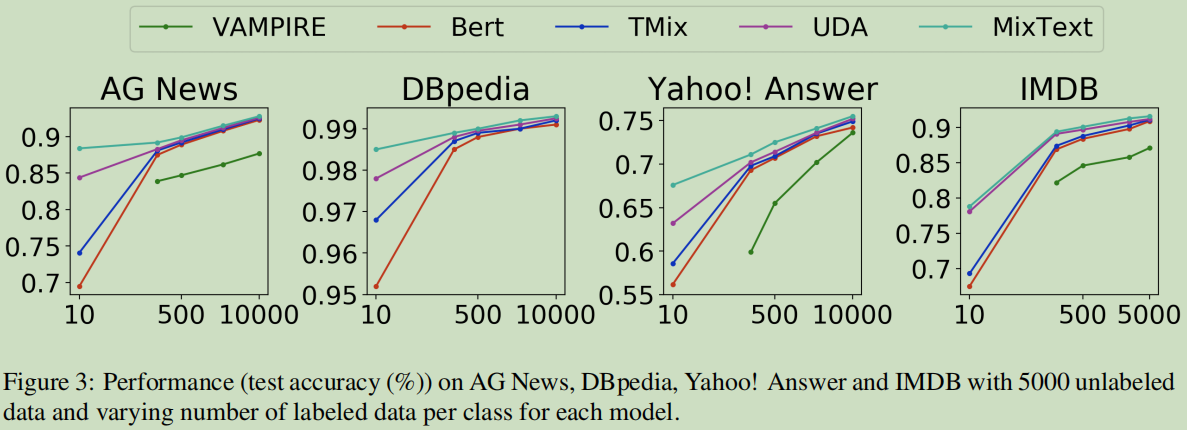
相关工作
Pre-training and Fine-tuning Framework,
Semi-Supervised Learning on Text Data
Interpolation-based Regularizers–基于抽值的正则化
Data Augmentations for Text
另外,半监督技术:
| 方法思想 | 论文 | 说明 |
|---|---|---|
| selftarget-prediction | 2016-Temporal ensembling for semi-supervised learning | 这两个模型,分别为П-model与Temporal ensembling模型。笔记 |
| entropy minimization | 2004-Semisupervised learning by entropy minimization | |
| consistency regularization | 2019 - Mixmatch: A holistic approach to semisupervised learning ; 2019-Unsupervised data augmentation for consistency training |
参考
[1]NLP之MixText 半监督文本分类(2020年4月论文解读), https://zhuanlan.zhihu.com/p/156091468
happyprince; https://blog.csdn.net/ld326/article/details/114138379
interpolate
英[ɪnˈtɜ:pəleɪt] 美[ɪnˈtɜrpəleɪt]
v. 插入,插(话);篡改

















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









