






尚医通项目总结
一、 项目介绍
尚医通即为网上预约挂号系统,网上预约挂号是近年来开展的一项便民就医服务,旨在缓解看病难、挂号难的就医难题,许多患者为看一次病要跑很多次医院,最终还不一定能保证看得上医生。网上预约挂号全面提供的预约挂号业务从根本上解决了这一就医难题。随时随地轻松挂号!不用排长队!
二、 核心技术
后端
SpringBoot:简化新Spring应用的初始搭建以及开发过程
SpringCloud:基于Spring Boot实现的云原生应用开发工具,SpringCloud使用的技术:(SpringCloudGateway、Spring Cloud Alibaba Nacos、Spring Cloud Alibaba Sentinel、SpringCloud Task和SpringCloudFeign等)
MyBatis-Plus:持久层框架
Redis:内存缓存
RabbitMQ:消息中间件
HTTPClient: Http协议客户端
Swagger2:Api接口文档工具
Nginx:负载均衡
Lombok
Mysql:关系型数据库
MongoDB:面向文档的NoSQL数据库
前端
Vue.js:web 界面的渐进式框架
Node.js: JavaScript 运行环境
Axios:Axios 是一个基于 promise 的 HTTP 库
NPM:包管理器
Babel:转码器
Webpack:打包工具
Docker :容器技术
Git:代码管理工具
三、 业务流程
医通业务流程图:
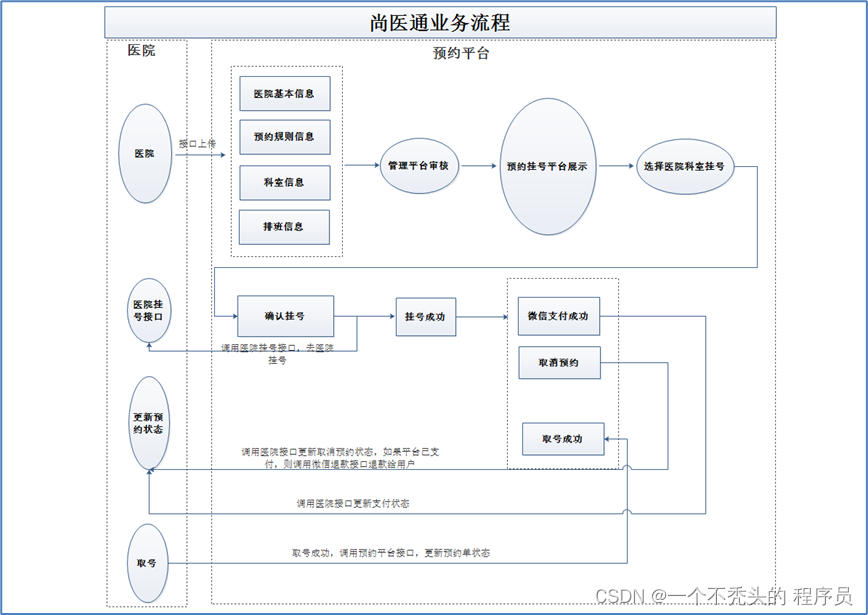
四、 项目模块构建介绍
hospital-manage:医院接口模拟端(已开发,直接使用)
yygh-parent:根目录,管理子模块:
common:公共模块父节点
common-util:工具类模块,所有模块都可以依赖于它
rabbit-util:rabbitmq业务封装
service-util:service服务的工具包,包含service服务的公共配置类,所有 service模块依赖于它
server-gateway:服务网关
model:实体类模块
service:api接口服务父节点
service-hosp:医院api接口服务
service-cmn:公共api接口服务
service-user:用户api接口服务
service-order:订单api接口服务
service-oss:文件api接口服务
service-sms:短信 api接口服务
service-task:定时任务服务
service-statistics:统计api接口服务
service-client:feign服务调用父节点
service-cmn-client:公共api接口
service-hosp-client:医院api接口
service-order-client:订单api接口
五、 医院系统功能介绍
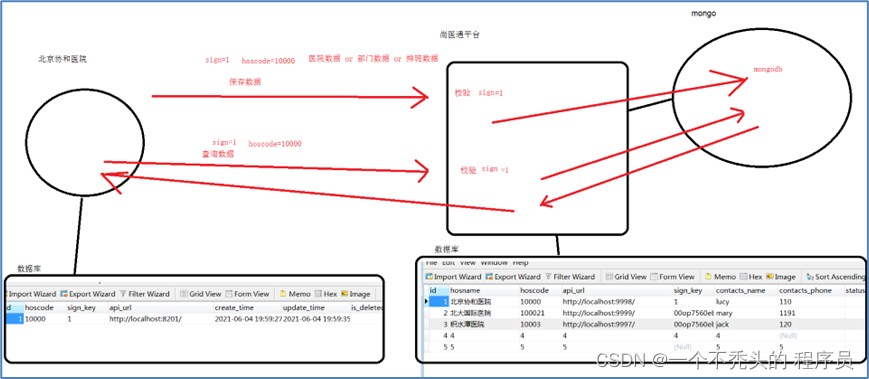
医院与尚医通合作后,尚医通会提供给医院的唯一标识ID号(hoscode)和用于接口调用的MD5数字签名算法的密码串(signKey)。这样接口采用数据签名的方式来保证医院与尚医通系统间的身份验证、中间信息传递的完整性,以便进行电子商务安全当中非常重要的交易身份辨识、不可抵赖、防止篡改等功能。
这个系统的功能只要是为我们后面的平台提供数据支持,通过这个系统,可以添加医院信息,查看医院信息,上传医院科室信息,查看医院科室信息,上传医院医生排班,查看医生的排班,并且提供了预约下单,更新支付状态,取消预约的接口。
医院平台涉及的数据库:
hospital_set 保存医院的信息和平台信息表
order_info 订单信息表
schedule 排班信息表
业务流程的沟通图
医院设置
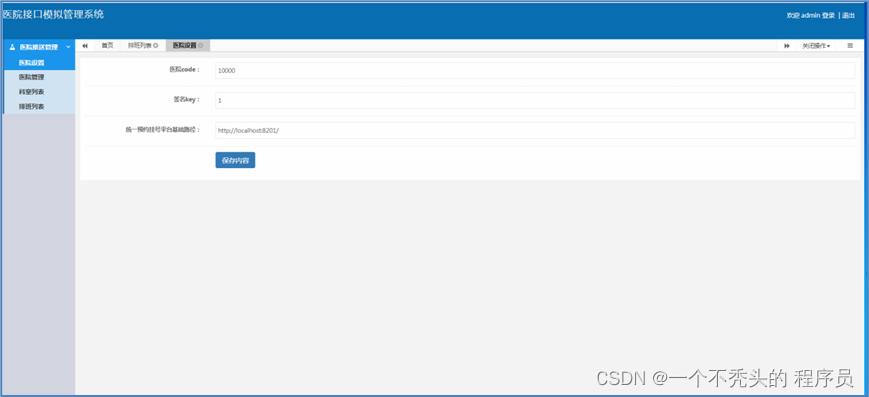
医院设置,会把医院的编号,医院的签名 和平台的接口地址设置到hospital_set表里。每次访问平台系统的时候会携带者签名sign到医院平台进行比对,如果一致才能调用平台的接口添加和查询数据。
医院管理
医院数据添加
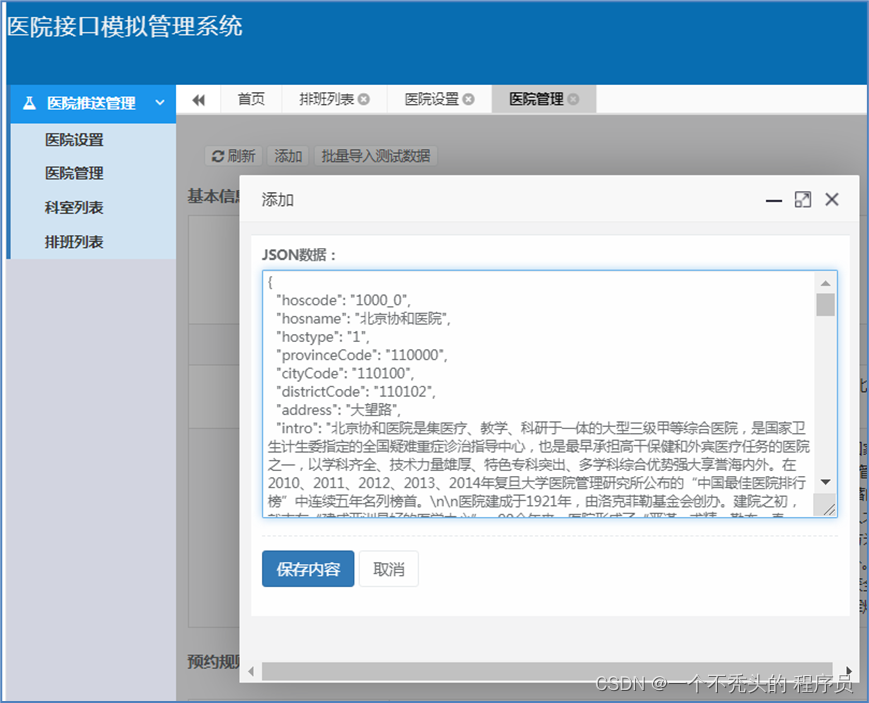
1.数据分为医院基本信息与预约规则信息
2.医院logo转换为base64字符串
3.预约规则信息属于医院基本信息的一个属性
4.预约规则rule,以数组形式传递
5.数据传递过来我们还要验证签名,只允许平台开通的医院可以上传数据,保证数据安全性
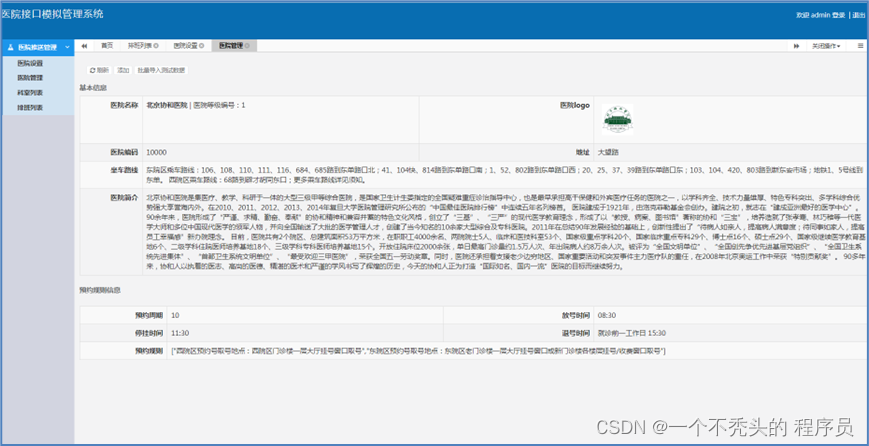
医院详情展示
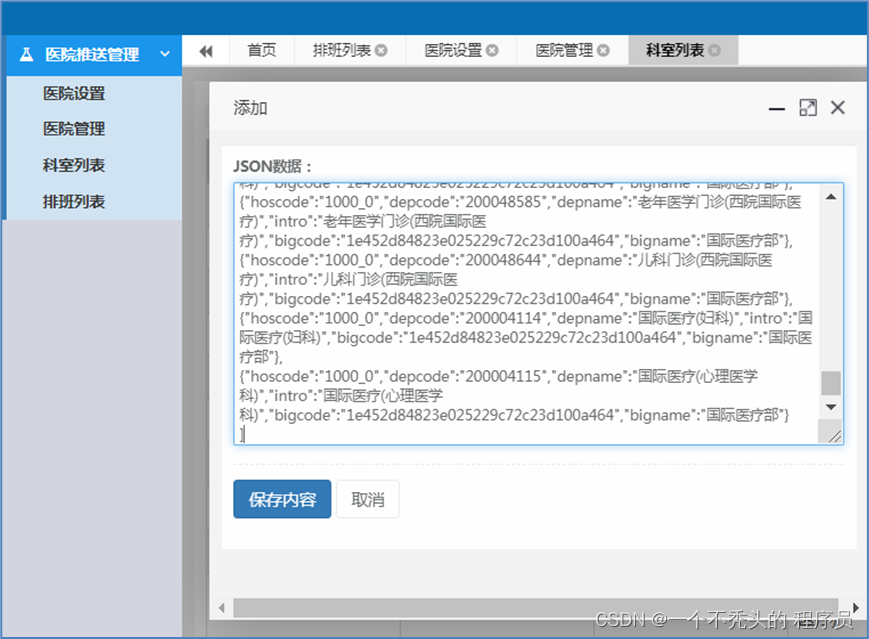
科室数据上传
接口数据结构
{
"hoscode": "1000_0",
"depcode": "200050923",
"depname": "门诊部核酸检测门诊(东院)",
"intro": "门诊部核酸检测门诊(东院)",
"bigcode": "44f162029abb45f9ff0a5f743da0650d",
"bigname": "体检科"
}
说明:一个大科室下可以有多个小科室,如图:

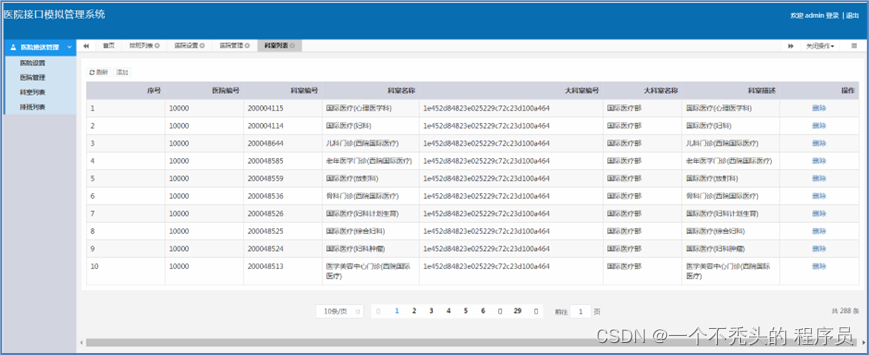
科室列表展示
排班数据上传
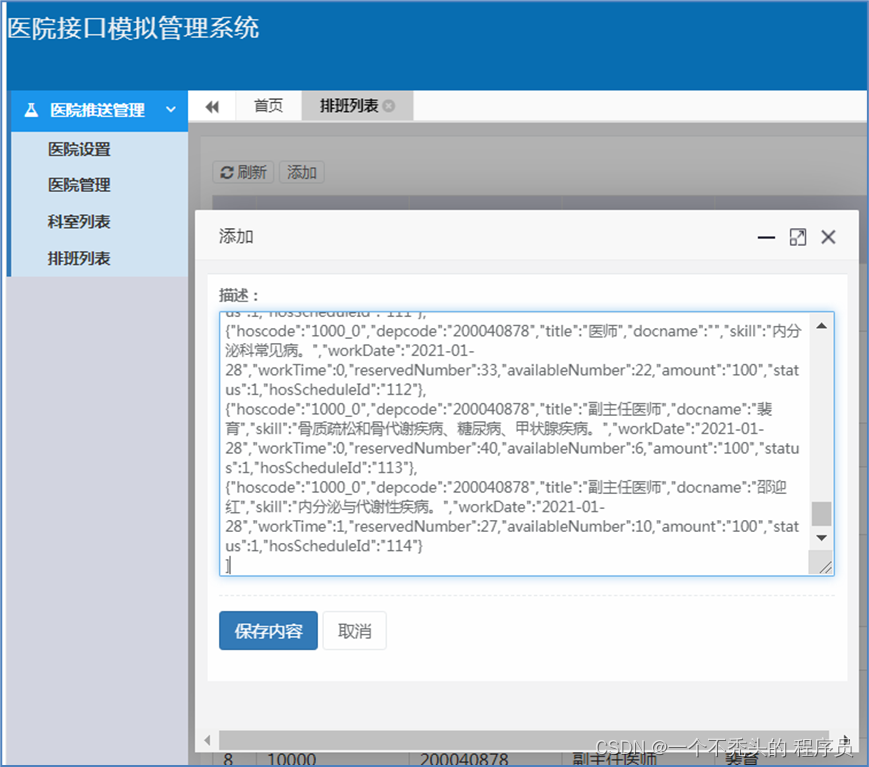
接口数据结构
```bash
{
"hoscode": "1000_0",
"depcode": "200040878",
"title": "医师",
"docname": "",
"skill": "内分泌科常见病。",
"workDate": "2020-06-22",
"workTime": 0,
"reservedNumber": 33,
"availableNumber": 22,
"amount": "100",
"status": 1,
"hosScheduleId": "1"
}
六、 后台系统介绍
后台系统
6.1、医院设置管理
医院设置主要是用来保存开通医院的一些基本信息,每个医院一条信息,保存了医院编号(平台分配,全局唯一)和接口调用相关的签名key等信息,是整个流程的第一步,只有开通了医院设置信息,才可以上传医院相关信息。
我们所开发的功能就是基于单表的一个CRUD、锁定/解锁和发送签名信息这些基本功能
涉及的数据库yygh_hosp ,设计的数据库表hospital_set
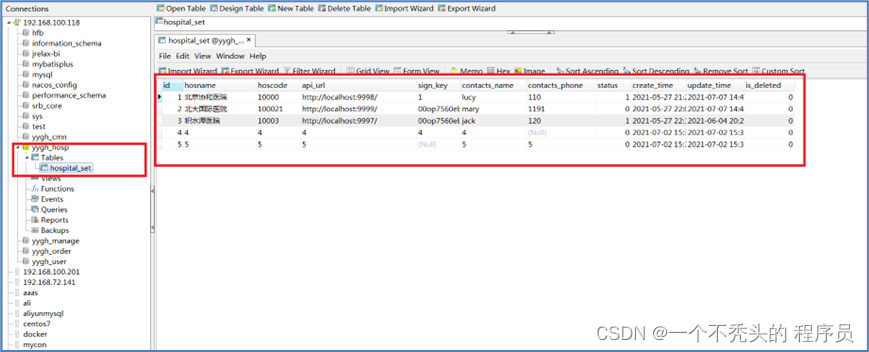
1)医院设置列表
技术点: mybatis-plus实现分页
医院设置列表查询的时候,用的组件是mybatis-plus,MyBatis Plus自带分页插件,只要简单的配置即可实现分页功能。
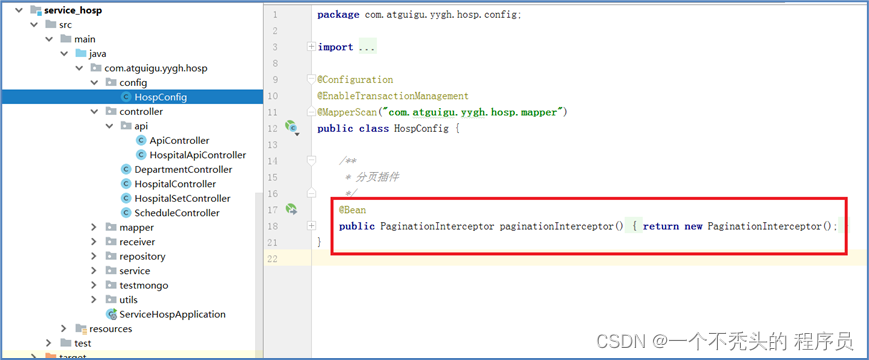
技术点: mybatis-plus实现条件查询
医院条件查询用的时候,用的查询条件对象QueryWrapper
2)医院设置列表添加
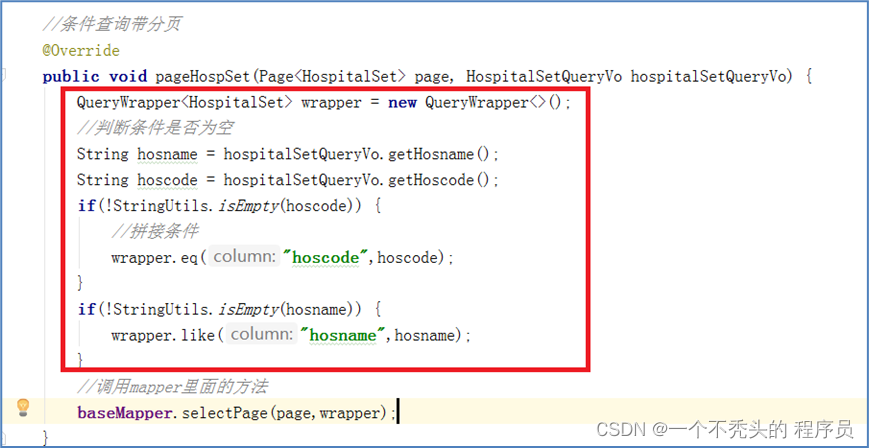
技术点: mybatis-plus的主键策略
(1)ID_WORKER
MyBatis-Plus默认的主键策略是:ID_WORKER 全局唯一ID
(2)自增策略
要想主键自增需要配置如下主键策略
需要在创建数据表的时候设置主键自增
实体字段中配置 @TableId(type = IdType.AUTO)
@TableId(type = IdType.AUTO)
private Long id;
其它主键策略:分析 IdType 源码可知
public enum IdType {
/**
* 数据库ID自增
*/
AUTO(0),
/**
* 该类型为未设置主键类型
*/
NONE(1),
/**
* 用户输入ID
* 该类型可以通过自己注册自动填充插件进行填充
*/
INPUT(2),
/**
* 全局唯一ID
*/
ASSIGN_ID(3),
/**
* 全局唯一ID (UUID)
*/
ASSIGN_UUID(4),
/** @deprecated */
@Deprecated
ID_WORKER(3),
/** @deprecated */
@Deprecated
ID_WORKER_STR(3),
/** @deprecated */
@Deprecated
UUID(4);
private final int key;
private IdType(int key) {
this.key = key;
}
public int getKey() {
return this.key;
}
}
技术点: mybatis-plus自动填充
项目中经常会遇到一些数据,每次都使用相同的方式填充,例如记录的创建时间,更新时间等。
我们可以使用MyBatis Plus的自动填充功能,完成这些字段的赋值工作:
(1)数据库表中添加自动填充字段
在User表中添加datetime类型的新的字段 create_time、update_time
(2)实体上添加注解
@Data
public class User {
......
@TableField(fill = FieldFill.INSERT)
private Date createTime;
//@TableField(fill = FieldFill.UPDATE)
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date updateTime;
}
(3)实现元对象处理器接口
注意:不要忘记添加 @Component 注解
@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
this.setFieldValByName("createTime", new Date(), metaObject);
this.setFieldValByName("updateTime", new Date(), metaObject);
}
@Override
public void updateFill(MetaObject metaObject) {
this.setFieldValByName("updateTime", new Date(), metaObject);
}
}
3)医院设置锁定
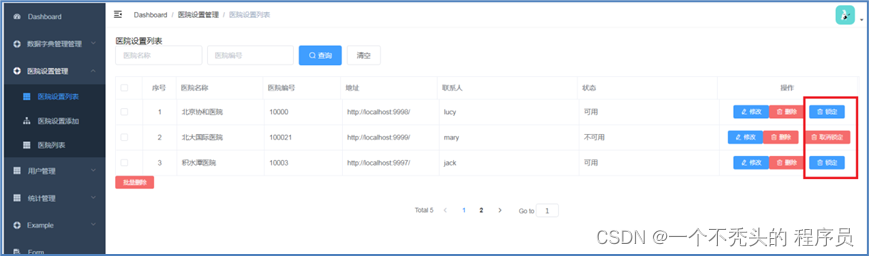
设置锁定就是修改hospital_set 的字段status为0
4)医院设置删除
技术点: mybatis-plus数据逻辑删除
物理删除:真实删除,将对应数据从数据库中删除,之后查询不到此条被删除数据
逻辑删除:假删除,将对应数据中代表是否被删除字段状态修改为“被删除状态”,之后在数据库中仍旧能看到此条数据记录。
(1)数据库中添加 deleted字段
(2)实体类添加deleted 字段
并加上 @TableLogic 注解 和 @TableField(fill = FieldFill.INSERT) 注解
@TableLogic
@TableField(fill = FieldFill.INSERT)
private Integer deleted;
(3)元对象处理器接口添加deleted的insert默认值
@Override
public void insertFill(MetaObject metaObject) {
…
this.setFieldValByName(“deleted”, 0, metaObject);
}
(4)application.properties 加入配置
此为默认值,如果你的默认值和mp默认的一样,该配置可无
mybatis-plus.global-config.db-config.logic-delete-value=1
mybatis-plus.global-config.db-config.logic-not-delete-value=0
(5)测试逻辑删除
测试后发现,数据并没有被删除,deleted字段的值由0变成了1
6.2、医院列表,详情,排班,下线功能
目前我们把医院、科室和排班都上传到了平台,那么管理平台就应该把他们管理起来,在我们的管理平台能够直观的查看这些信息。
这个是以mongodb为存储数据库,创建了3个集合,Hospital是储存医院信息,Department是储存科室信息,Schedule是储存医生的排班信息。
1).医院列表展示
查询医院列表是通过查询mongodb数据库Hospital,展示医院列表的,用的是springdata-mongo查询,所以service_hosp 需要加入对应的依赖包。dao可以通过继承
MongoRepository接口实现对Hospital的查询所有操作。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
//医院列表条件查询带分页方法
@Override
public Page<Hospital> selectHospPage(int page, int limit, HospitalQueryVo hospitalQueryVo) {
//设置排序
Sort sort = Sort.by(Sort.Direction.DESC, "createTime");
//创建Pageable对象
// 当前页从0 开始的 page-1
Pageable pageable = PageRequest.of(page-1,limit,sort);
//创建条件匹配器
ExampleMatcher matcher = ExampleMatcher.matching() //构建对象
.withStringMatcher(ExampleMatcher.StringMatcher.CONTAINING) //改变默认字符串匹配方式:模糊查询
.withIgnoreCase(true); //改变默认大小写忽略方式:忽略大小写
//创建条件封装对象
Hospital hospital = new Hospital();
BeanUtils.copyProperties(hospitalQueryVo,hospital);
hospital.setIsDeleted(0);
Example<Hospital> example = Example.of(hospital,matcher);
//调用方法
Page<Hospital> pages = hospitalRepository.findAll(example, pageable);
List<Hospital> content = pages.getContent();
// for (int i = 0; i <content.size(); i++) {
// Hospital item = content.get(i);
// this.packHospital(item);
// }
content.stream().forEach(item -> {
this.packHospital(item);
});
return pages;
}
从mongo中查询出来的数据医院是编号,和地址编号,需要通过远程调用字典的微服务获取,医院编号对应的医疗类型,地址编号对应的城市信息,然后封装到Hospital的扩展信息里,最后再页面显示。
/**
* 封装数据
* @param hospital
* @return
*/
private Hospital packHospital(Hospital hospital) {
String hostypeString = dictFeignClient.getName(DictEnum.HOSTYPE.getDictCode(),hospital.getHostype());
String provinceString = dictFeignClient.getName(hospital.getProvinceCode());
String cityString = dictFeignClient.getName(hospital.getCityCode());
String districtString = dictFeignClient.getName(hospital.getDistrictCode());
hospital.getParam().put("hostypeString", hostypeString);
hospital.getParam().put("fullAddress", provinceString + cityString + districtString + hospital.getAddress());
return hospital;
}
2).医院的详细信息
医院的详细信息也是通过查询mongo里hospital的id查询出具体的医院详细信息和预约规则信息。
3).查看医院排班信息
这个功能显示医院的排班信息,这个功能分成3部分:
第一部分显示医院的科室,这个可是因为有大科室和小科室的父子级别关系,所以这部分是通过树形图来展示。
第二部分,是当点击对应科室的时候,显示每天 一共多少个号并且已经还剩下多少个号码,并且这部分需要分页显示。
第三部分,当选中某一天后,显示这天的每位医生的上班时间、可预约数、剩余数,挂号费等信息。
6.3、数据管理
数据管理模块涉及的数据yygh_cmn,涉及的表 dict
1)数据字典树形的显示
public class DictServiceImpl extends ServiceImpl<DictMapper, Dict> implements DictService {
//根据数据id查询子数据列表
@Override
public List<Dict> findChlidData(Long id) {
QueryWrapper<Dict> wrapper = new QueryWrapper<>();
wrapper.eq("parent_id",id);
List<Dict> dictList = baseMapper.selectList(wrapper);
//向list集合每个dict对象中设置hasChildren
for (Dict dict:dictList) {
Long dictId = dict.getId();
boolean isChild = this.isChildren(dictId);
dict.setHasChildren(isChild);
}
return dictList;
}
//判断id下面是否有子节点
private boolean isChildren(Long id) {
QueryWrapper<Dict> wrapper = new QueryWrapper<>();
wrapper.eq("parent_id",id);
Integer count = baseMapper.selectCount(wrapper);
return count>0;
}
}
2).excle字典模板数据的导出
//数据字典导出功能
@Override
public void exportDictData(HttpServletResponse response) {
try {
response.setContentType("application/vnd.ms-excel");
response.setCharacterEncoding("utf-8");
// 这里URLEncoder.encode可以防止中文乱码 当然和easyexcel没有关系
String fileName = URLEncoder.encode("数据字典", "UTF-8");
response.setHeader("Content-disposition", "attachment;filename="+ fileName + ".xlsx");
//查询数据字典表所有数据
List<Dict> dictAll = baseMapper.selectList(null);
// List<Dict>内容 放到 List<DictEeVo>里面
//遍历dictAll
List<DictEeVo> dictVoAll = new ArrayList<>();
for(Dict dict : dictAll) {
DictEeVo dictEeVo = new DictEeVo();
//dictEeVo.setId(dict.getId());
BeanUtils.copyProperties(dict,dictEeVo);
dictVoAll.add(dictEeVo);
}
//使用EasyExcel实现写操作
EasyExcel.write(response.getOutputStream(), DictEeVo.class).sheet("数据字典").doWrite(dictVoAll);
}catch(Exception e) {
e.printStackTrace();
}
}
3).数据字典的导入
EasyExcel采用一行一行的解析模式,并将一行的解析结果以观察者的模式通知处理(AnalysisEventListener)。
实现代码
public void importDictData(MultipartFile file) {
try {
EasyExcel.read(file.getInputStream(),DictEeVo.class,excelListenrer).sheet().doRead();
} catch (IOException e) {
e.printStackTrace();
}
}
@Component
public class DictExcelListenrer extends AnalysisEventListener<DictEeVo> {
@Autowired
private DictMapper dictMapper;
// @Autowired
// private DictService dictService;
//创建监听器对象时候,执行invoke方法,读取excel内容,一行一行读取,从第二行读取
@Override
public void invoke(DictEeVo dictEeVo, AnalysisContext analysisContext) {
//dictEeVo每行数据
//调用mapper的方法添加到数据库
//dictEeVo 变成 dict对象
Dict dict = new Dict();
BeanUtils.copyProperties(dictEeVo,dict);
dictMapper.insert(dict);
// dictService.save(dict);
}
技术点: easy-excel 和poi的区别
生成Excel比较有名的框架有Apache poi等,但他们都存在一个严重的问题就是非常的耗内存。如果你的系统并发量不大的话可能还行,但是一旦并发上来后一定会OOM或者JVM频繁的full gc。
EasyExcel是阿里巴巴开源的一个excel处理框架,以使用简单、节省内存著称。EasyExcel能大大减少占用内存的主要原因是在解析Excel时没有将文件数据一次性全部加载到内存中,而是从磁盘上一行行读取数据,逐个解析。
技术点: Redis做缓存
1.Redis介绍
Redis是当前比较热门的NOSQL系统之一,它是一个开源的使用ANSI c语言编写的key-value存储系统(区别于MySQL的二维表格的形式存储。)。和Memcache类似,但很大程度补偿了Memcache的不足。和Memcache一样,Redis数据都是缓存在计算机内存中,不同的是,Memcache只能将数据缓存到内存中,无法自动定期写入硬盘,这就表示,一断电或重启,内存清空,数据丢失。所以Memcache的应用场景适用于缓存无需持久化的数据。而Redis不同的是它会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,实现数据的持久化。
Redis的特点:
1,Redis读取的速度是110000次/s,写的速度是81000次/s;
2,原子 。Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
3,支持多种数据结构:string(字符串);list(列表);hash(哈希),set(集合);zset(有序集合)
4,持久化,集群部署
5,支持过期时间,支持事务,消息订阅
Spring Cache 是一个非常优秀的缓存组件。自Spring 3.1起,提供了类似于@Transactional注解事务的注解Cache支持,且提供了Cache抽象,方便切换各种底层Cache(如:redis)
使用Spring Cache的好处:
1,提供基本的Cache抽象,方便切换各种底层Cache;
2,通过注解Cache可以实现类似于事务一样,缓存逻辑透明的应用到我们的业务代码上,且只需要更少的代码就可以完成;
3,提供事务回滚时也自动回滚缓存;
4,支持比较复杂的缓存逻辑;
数据字典模块添加Redis缓存
<!-- redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- spring2.X集成redis所需common-pool2-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.6.0</version>
</dependency>
添加Redis配置类
@Configuration
@EnableCaching
public class RedisConfig {
/**
* 设置RedisTemplate规则
* @param redisConnectionFactory
* @return
*/
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
// 指定要序列化的域,field,get和set,以及修饰符范围,ANY是都有包括private和public
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
// 指定序列化输入的类型,类必须是非final修饰的,final修饰的类,比如String,Integer等会跑出异常
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
//序列号key value
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
/**
* 设置CacheManager缓存规则
* @param factory
* @return
*/
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题),过期时间600秒
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}
配置文件添加redis配置
spring.redis.host=192.168.44.165
spring.redis.port=6379
spring.redis.database= 0
spring.redis.timeout=1800000
spring.redis.lettuce.pool.max-active=20
spring.redis.lettuce.pool.max-wait=-1
#最大阻塞等待时间(负数表示没限制)
spring.redis.lettuce.pool.max-idle=5
spring.redis.lettuce.pool.min-idle=0
通过注解添加redis缓存
(1)缓存@Cacheable
根据方法对其返回结果进行缓存,下次请求时,如果缓存存在,则直接读取缓存数据返回;如果缓存不存在,则执行方法,并把返回的结果存入缓存中。一般用在查询方法上。
查看源码,属性值如下
(2)缓存@CachePut
使用该注解标志的方法,每次都会执行,并将结果存入指定的缓存中。其他方法可以直接从响应的缓存中读取缓存数据,而不需要再去查询数据库。一般用在新增方法上。
查看源码,属性值如下:
(3)缓存@CacheEvict
使用该注解标志的方法,会清空指定的缓存。一般用在更新或者删除方法上
查看源码,属性值如下:
查询数据字典列表添加Redis缓存
//根据数据id查询子数据列表
@Cacheable(value = "dict", key = "'selectIndexList'")
@Override
public List<Dict> findChlidData(Long id) {
QueryWrapper<Dict> wrapper = new QueryWrapper<>();
wrapper.eq("parent_id",id);
List<Dict> dictList = baseMapper.selectList(wrapper);
//向list集合每个dict对象中设置hasChildren
for (Dict dict:dictList) {
Long dictId = dict.getId();
boolean isChild = this.isChildren(dictId);
dict.setHasChildren(isChild);
}
return dictList;
}
6.4、用户管理
用户管理涉及的数据库和表
用户管理涉及的数据库yyds_user
涉及的表
user_info 用户表
patient 就诊人表
user_login_record 用户登录记录表
1)用户列表
用户列表是一个简单的分页查询的一个功能,并且支持名字name 和创建时间的范围查询。并且把用户的认证情况和是否锁定,都封装到了用户的扩展字段。
2).查看用户详情功能
通过用户的id去数据库查询user_info表里的数据,然后再通过QueryWrapper wrapper.eq(“user_id”,userId)封装查询条件去patient查询用户所关联的所有就诊人,最后封装为map在页面显示。
3).用户锁定功能
锁定用户就是修改user_info 表里的status属性,如果是0表示锁定,1表示正常
4).认证用户审批
锁定用户就是修改user_info 表里的auth_status属性,0:未认证 1:认证中 2:认证成功 -1:认证失败。
用户的认证代码如下:
6.5、统计管理
预约统计
我们统计医院每天的预约情况,通过图表的形式展示,统计的数据都来自订单模块,因此我们在该模块封装好数据,在统计模块通过feign的形式获取数据。因为在实际的生产环境中,有很多种各式统计,数据来源于各个服务模块,我们得有一个统计模块来专门管理
在order项目中编程sql预测根据日期分组查询每天预约的数量
service层把日期封装到一个list集合里面,然后把数据封装到一个list集合里面,方便页面显示
ECharts是百度的一个项目,后来百度把Echart捐给apache,用于图表展示,提供了常规的折线图、柱状图、散点图、饼图、K线图,用于统计的盒形图,用于地理数据可视化的地图、热力图、线图,用于关系数据可视化的关系图、treemap、旭日图,多维数据可视化的平行坐标,还有用于 BI 的漏斗图,仪表盘,并且支持图与图之间的混搭。我们通过向后台请求xData和yData,赋值给echarts组件就可以显示出折线图。
<script>
import echarts from 'echarts'
import statisticsApi from '@/api/yygh/sta'
export default {
data() {
return {
searchObj: {
hosname: '',
reserveDateBegin: '',
reserveDateEnd: ''
},
btnDisabled: false,
chart: null,
title: '',
xData: [], // x轴数据
yData: [] // y轴数据
}
},
methods: {
// 初始化图表数据
showChart() {
statisticsApi.getCountMap(this.searchObj).then(response => {
this.yData = response.data.countList
this.xData = response.data.dateList
this.setChartData()
})
},
setChartData() {
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('chart'))
// 指定图表的配置项和数据
var option = {
title: {
text: this.title + '挂号量统计'
},
tooltip: {},
legend: {
data: [this.title]
},
xAxis: {
data: this.xData
},
yAxis: {
minInterval: 1
},
series: [{
name: this.title,
type: 'line',
data: this.yData
}]
}
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option)
},
}
}
</script>
七、 前台系统介
7.1、首页展示医院的等级和地区分类并且显示出医院列表
等级信息通过查询字典表dictApi.findByDictCode(‘Hostype’)对应的等级’Hostype’,从而查询出所有有等级列表。
地区信息是也是通过查询dictApi.findByDictCode(‘Beijin’)北京下面所有的地区,然后再返回到前台页面的。
医院列表是通过带条件的分页查询hospApi.getPageList(this.page,this.limit,this.searchObj)实现的,医院的数据是从mongodb中的hospital集合中查询获取的。并且通过点击分类信息,可以实现带条件的查询。
具体的代码如下:
//医院列表条件查询带分页方法
@Override
public Page<Hospital> selectHospPage(int page, int limit, HospitalQueryVo hospitalQueryVo) {
//设置排序
Sort sort = Sort.by(Sort.Direction.DESC, "createTime");
//创建Pageable对象
// 当前页从0 开始的 page-1
Pageable pageable = PageRequest.of(page-1,limit,sort);
//创建条件匹配器
ExampleMatcher matcher = ExampleMatcher.matching() //构建对象
.withStringMatcher(ExampleMatcher.StringMatcher.CONTAINING) //改变默认字符串匹配方式:模糊查询
.withIgnoreCase(true); //改变默认大小写忽略方式:忽略大小写
//创建条件封装对象
Hospital hospital = new Hospital();
BeanUtils.copyProperties(hospitalQueryVo,hospital);
hospital.setIsDeleted(0);
Example<Hospital> example = Example.of(hospital,matcher);
//调用方法
Page<Hospital> pages = hospitalRepository.findAll(example, pageable);
List<Hospital> content = pages.getContent();
// for (int i = 0; i <content.size(); i++) {
// Hospital item = content.get(i);
// this.packHospital(item);
// }
content.stream().forEach(item -> {
this.packHospital(item);
});
return pages;
}
7.2、医院详情显示
医院的详细信息和科室显示
1.通过医院的id从mongodb数据库中的hospital集合中查询出医院的详细信息和医院的预约规则。
2.科室信息,这是通过医院编号,然后查询出所有的科室,然后再把大科室分组,然后把小科室集合封装到大科室的属性里。
用来做页面显示的科室示的实体类,里面封装有小科室的集合。
@Data
@ApiModel(description = "Department")
public class DepartmentVo {
@ApiModelProperty(value = "科室编号")
private String depcode;
@ApiModelProperty(value = "科室名称")
private String depname;
@ApiModelProperty(value = "下级节点")
private List<DepartmentVo> children;
}
业务层的集体代码如下:
//根据医院编号查询医院所有科室列表
@Override
public List<DepartmentVo> findDeptTree(String hoscode) {
//1 根据医院编号查询所有科室列表
Department departmentQuery = new Department();
departmentQuery.setHoscode(hoscode);
Example<Department> example = Example.of(departmentQuery);
List<Department> departmentList = departmentRepository.findAll(example);
//根据departmentList集合所有 大科室code进行分组操作
// 分组之后封装map集合 map的key是大科室code value是大科室下面所有小科室集合
Map<String, List<Department>> deparmentMap =
departmentList.stream().collect(Collectors.groupingBy(Department::getBigcode));
//创建list集合用于数据最终封装
List<DepartmentVo> finalData = new ArrayList<>();
//遍历分组之后map集合
for(Map.Entry<String,List<Department>> entry : deparmentMap.entrySet()) {
//得到map集合 key值,每个大科室id
String bigCode = entry.getKey();
//得到map集合 value值,每个大科室所有小科室集合
List<Department> deparment1List = entry.getValue();
//封装大科室数据
DepartmentVo departmentVoBig = new DepartmentVo();
departmentVoBig.setDepcode(bigCode);
departmentVoBig.setDepname(deparment1List.get(0).getBigname());
//封装大科室里面小科室信息
//创建list集合用于封装大科室里面小科室
List<DepartmentVo> departmentSmaList = new ArrayList<>();
for(Department department : deparment1List) {
DepartmentVo departmentSma = new DepartmentVo();
departmentSma.setDepcode(department.getDepcode());
departmentSma.setDepname(department.getDepname());
//转换之后所有小科室 对象 放到 departmentSmaList集合
departmentSmaList.add(departmentSma);
}
//把小科室集合放到大科室对象里面
departmentVoBig.setChildren(departmentSmaList);
//把多个大科室(包含小科室)放到最终集合里面
finalData.add(departmentVoBig);
}
return finalData;
}
7.3、用户登录功能
1)用户注册可以用手机号来注册和登录,用户收入手机号,然后后台生成验证码,一份保存在redis里(保存的时间是5分钟),并且把验证码以短信的方式发送给用户。
当用户输入正确验证码后,第一步就会把用户信息保存在数据库里实现用户的注册,第二步会把通过jwt技术生成一个token,把token发送给浏览器保存在cookie里,页面会再次发送请求通过token获取用户的姓名等信息保存在cookie里,这样就实现了用户的登录。
手机号登录(短信验证码发送)
@RestController
@RequestMapping("/api/msm")
public class MsmController {
@Autowired
private MsmService msmService;
@Autowired
private RedisTemplate<String, String> redisTemplate;
@GetMapping(value = "/send/{phone}")
public R code(@PathVariable String phone) {
String code = redisTemplate.opsForValue().get(phone);
if(!StringUtils.isEmpty(code)) return R.ok();
code = RandomUtil.getFourBitRandom();
Map<String,Object> param = new HashMap<>();
param.put("code", code);
boolean isSend = msmService.send(phone, "SMS_180051135", param);
if(isSend) {
redisTemplate.opsForValue().set(phone, code,5, TimeUnit.MINUTES);
return R.ok();
} else {
return R.error().message("发送短信失败");
}
}
}
技术点: 阿里云手机短信发送
1、在service-msm的pom中引入依赖
<dependencies>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
</dependency>
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>aliyun-java-sdk-core</artifactId>
</dependency>
</dependencies>
手机发送短信代码:
要用阿里云实现短信发送,需要在阿里云上先申请开通短信功能。
需要的参数有:accessKey,secretid,手机号,SignName签名名称,TemplateCode 模板id。
登录成功后,前端会把后台返回的token放到cookie里面
技术点: jwt
JWT(Json Web Token)是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准。
JWT的声明一般被用来在身份提供者和服务提供者间传递被认证的用户身份信息,以便于从资源服务器获取资源。比如用在用户登录上
JWT最重要的作用就是对 token信息的防伪作用。
JWT的原理
一个JWT由三个部分组成:公共部分、私有部分、签名部分。最后由这三者组合进行base64编码得到JWT。
1、 公共部分
主要是该JWT的相关配置参数,比如签名的加密算法、格式类型、过期时间等等。
Key=ATGUIGU
2、 私有部分
用户自定义的内容,根据实际需要真正要封装的信息。
userInfo{用户的Id,用户的昵称nickName}
3、 签名部分
SaltiP: 当前服务器的Ip地址!{linux 中配置代理服务器的ip}
主要用户对JWT生成字符串的时候,进行加密{盐值}
最终组成 key+salt+userInfo token!
base64编码,并不是加密,只是把明文信息变成了不可见的字符串。但是其实只要用一些工具就可以把base64编码解成明文,所以不要在JWT中放入涉及私密的信息。
使用方式添加依赖:
<dependencies>
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
</dependency>
</dependencies>
jwt的工具类:
public class JwtHelper {
private static long tokenExpiration = 24*60*60*1000;
private static String tokenSignKey = "123456";
//根据userid和username生成token字符串
public static String createToken(Long userId, String userName) {
String token = Jwts.builder()
.setSubject("YYGH-USER")
.setExpiration(new Date(System.currentTimeMillis() + tokenExpiration))
.claim("userId", userId)
.claim("userName", userName)
.signWith(SignatureAlgorithm.HS512, tokenSignKey)
.compressWith(CompressionCodecs.GZIP)
.compact();
return token;
}
//从token字符串获取用户信息
public static Long getUserId(String token) {
if(StringUtils.isEmpty(token)) return null;
Jws<Claims> claimsJws = Jwts.parser().setSigningKey(tokenSignKey).parseClaimsJws(token);
Claims claims = claimsJws.getBody();
Integer userId = (Integer)claims.get("userId");
return userId.longValue();
}
public static String getUserName(String token) {
if(StringUtils.isEmpty(token)) return "";
Jws<Claims> claimsJws
= Jwts.parser().setSigningKey(tokenSignKey).parseClaimsJws(token);
Claims claims = claimsJws.getBody();
return (String)claims.get("userName");
}
public static void main(String[] args) {
String token = JwtHelper.createToken(1L, "lucy");
System.out.println(token);
System.out.println(JwtHelper.getUserId(token));
System.out.println(JwtHelper.getUserName(token));
}
}
2)微信扫码登录
微信登录需要配置的需要参数
微信登录流程如图:
操作步骤为:
第一步我们通过接口把对应参数返回页面
第二步在头部页面启动打开微信登录二维码
第三步处理登录回调接口
第四步后台系统通过回调获取到临时的票据code和state
第五步通过临时的票据和appid 等参数,再次请求微信接口获取openid和access_token
第六步通过openid和access_token再次请求微信地址获取用户的基本信息nickname和headimgurl
第七步回调返回页面通知微信登录层回调成功
第八步如果是第一次扫描登录,则绑定手机号码,登录成功
7.4、实名认证
实名认证是把用户的真实姓名,身份证号以及照片,上传到后台系统service-user,然后更新到数据库里。此时数据表里user_info中auth_status的状态是1(认证中)。
在等到实名认证提交完成,然后再去点击实名认证的时候,不再让填写认证信息的表单,而是直接显示用户信息。对应的代码如下:
技术点: 阿里云的OSS图片上传
用户认证需要上传证件图片、首页轮播也需要上传图片,因此我们要做文件服务,阿里云oss是一个很好的分布式文件服务系统,所以我们只需要集成阿里云oss即可。
1、开通“对象存储OSS”服务
(1)申请阿里云账号
(2)实名认证
(3)开通“对象存储OSS”服务
(4)进入管理控制台
2、创建Bucket
选择:标准存储、公共读、不开通
二、使用SDK
引入pom文件的坐标
com.aliyun.oss
aliyun-sdk-oss
<!-- 日期工具栏依赖 -->
<dependency>
<groupId>joda-time</groupId>
<artifactId>joda-time</artifactId>
</dependency>
文件上传的实例代码如下:
7.5、就诊人管理
下单不光可以给自己挂号,也可以给其他的人挂号,所以预约下单需要选择就诊人,因此我们要实现就诊人管理,就诊人管理其实就是要实现一个完整的增删改查。
就诊人管理对应的数据库yygh_user,需要操作的表是patient
7.6、预约挂号功能
预约挂号室这个项目中最核心的业务,首先是要现实出对应预约科室门诊的每天的号源情况
,并且每天的号源对应的医生的排班信息,都要显示出来。
页面展示分析
(1)分页展示可预约日期,根据有号、无号、约满等状态展示不同颜色,以示区分
(2)可预约最后一个日期为即将放号日期,根据放号时间页面展示倒计时
1.排班和挂号详情信息
对于排班和挂号详情显示逻辑如下:
1.生成获取可预约日期分页数据dateList,先根据当前的时间是否已经过了8点30分,如果过了循环周期+1。
2. 根据日期查询对应号源信息,从mongodb中分组查询获取可预约日期科室剩余预约数
3. 把查询可预约日期排班数据转换 map集合,map<workDate,BookingScheduleRuleVo>。
4. 根据预约日期dateList 查询map对应数据,拿着获取每个日期查询map,判断map的日期对应对象是否为空,如果为空这个日期里面没有排班数据,那么AvailableNumber
为-1没有号,如果不为空,那么设置相应的当日挂号总数和剩余号数。
5.设置计算当前预约日期为周几。
6. 后一页最后一条记录为即将预约 status 状态 0:正常 1:即将放号
7. 第一页第一条数据判断是否超过预约时间,如果超过设置status 为当天停止挂号为-1。
8.当点击可挂号日期,后台会查询医院编号,就诊科室和日期查询详细的排班信息显示。
2生成预约挂号订单
订单表结构
生成订单需要的参数:就诊人id与 排班id
第一、生成订单需要获取就诊人信息,通过排班id获取排班下单信息与规则信息
第二、订单基本信息保存在订单表order_info里
第三、然后封装参数,通过接口去医院预约下单
第四、通过医院系统返回来的指更新订单信息例如:预约序号和取号时间
第五、从医院系统返回的排班可预约数(reservedNumber)和排班剩余预约数(availableNumber),yygh_order系统通过RabbitMQ把号源信息发送给yygh_hosp系统更新排班号源和发送短信
技术点: RabbitMQ
(1)rabbitMQ简介
以商品订单场景为例,
如果商品服务和订单服务是两个不同的微服务,在下单的过程中订单服务需要调用商品服务进行扣库存操作。按照传统的方式,下单过程要等到调用完毕之后才能返回下单成功,如果网络产生波动等原因使得商品服务扣库存延迟或者失败,会带来较差的用户体验,如果在高并发的场景下,这样的处理显然是不合适的,那怎么进行优化呢?这就需要消息队列登场了。
消息队列提供一个异步通信机制,消息的发送者不必一直等待到消息被成功处理才返回,而是立即返回。消息中间件负责处理网络通信,如果网络连接不可用,消息被暂存于队列当中,当网络畅通的时候在将消息转发给相应的应用程序或者服务,当然前提是这些服务订阅了该队列。如果在商品服务和订单服务之间使用消息中间件,既可以提高并发量,又降低服务之间的耦合度。
RabbitMQ就是这样一款消息队列。RabbitMQ是一个开源的消息代理的队列服务器,用来通过普通协议在完全不同的应用之间共享数据。
典型应用场景:
异步处理。把消息放入消息中间件中,等到需要的时候再去处理。
流量削峰。例如秒杀活动,在短时间内访问量急剧增加,使用消息队列,当消息队列满了就拒绝响应,跳转到错误页面,这样就可以使得系统不会因为超负载而崩溃。
(2)安装rabbitMQ
#拉取镜像
docker pull rabbitmq:management
#创建容器启动
docker run -d --restart=always -p 5672:5672 -p 15672:15672 --name rabbitmq rabbitmq:management
(3)服务rabbitMQ后台
pom引入jar包
<dependencies>
<!--rabbitmq消息队列-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-amqp</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
</dependency>
</dependencies>
发送消息端的service方法
@Service
public class RabbitService {
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* 发送消息
* @param exchange 交换机
* @param routingKey 路由键
* @param message 消息
*/
public boolean sendMessage(String exchange, String routingKey, Object message) {
rabbitTemplate.convertAndSend(exchange, routingKey, message);
return true;
}
}
配置mq消息转换器
@Configuration
public class MQConfig {
@Bean
public MessageConverter messageConverter(){
return new Jackson2JsonMessageConverter();
}
}
说明:默认是字符串转换器
消息接受端的实例代码
@Component
public class SmsReceiver {
@Autowired
private MsmService msmService;
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = MqConst.QUEUE_MSM_ITEM, durable = "true"),
exchange = @Exchange(value = MqConst.EXCHANGE_DIRECT_MSM),
key = {MqConst.ROUTING_MSM_ITEM}
))
public void send(MsmVo msmVo, Message message, Channel channel) {
msmService.send(msmVo);
}
}
7.7、挂号订单支付(微信)
微信支付接口调用的整体思路:
按API要求组装参数,以XML方式发送(POST)给微信支付接口(URL),微信支付接口也是以XML方式给予响应。程序根据返回的结果(其中包括支付URL)生成二维码或判断订单状态。
在线微信支付开发文档:
https://pay.weixin.qq.com/wiki/doc/api/index.html
(1) appid:微信公众账号或开放平台APP的唯一标识,weixin.pay.appid=wx74862e0dfcf69954
(2)mch_id:商户号 (配置文件中的partner),weixin.pay.partner=1558950191
(3)partnerkey:商户密钥,weixin.pay.partnerkey=T6m9iK73b0kn9g5v426MKfHQH7X8rKwb
(4)sign:数字签名, 根据微信官方提供的密钥和一套算法生成的一个加密信息, 就是为了保证交易的安全性
生成支付二维码
需要引入pom文件的jar包
<dependency>
<groupId>com.github.wxpay</groupId>
<artifactId>wxpay-sdk</artifactId>
<version>0.0.3</version>
</dependency>
生成支付二维码的代码并保存交易记录
@Service
public class WeixinServiceImpl implements WeixinService {
@Autowired
private OrderService orderService;
@Autowired
private PaymentService paymentService;
@Autowired
private RedisTemplate redisTemplate;
/**
* 根据订单号下单,生成支付链接
*/
@Override
public Map createNative(Long orderId) {
try {
Map payMap = (Map) redisTemplate.opsForValue().get(orderId.toString());
if(null != payMap) return payMap;
//根据id获取订单信息
OrderInfo order = orderService.getById(orderId);
// 保存交易记录
paymentService.savePaymentInfo(order, PaymentTypeEnum.WEIXIN.getStatus());
//1、设置参数
Map paramMap = new HashMap();
paramMap.put("appid", ConstantPropertiesUtils.APPID);
paramMap.put("mch_id", ConstantPropertiesUtils.PARTNER);
paramMap.put("nonce_str", WXPayUtil.generateNonceStr());
String body = order.getReserveDate() + "就诊"+ order.getDepname();
paramMap.put("body", body);
paramMap.put("out_trade_no", order.getOutTradeNo());
//paramMap.put("total_fee", order.getAmount().multiply(new BigDecimal("100")).longValue()+"");
paramMap.put("total_fee", "1");//为了测试
paramMap.put("spbill_create_ip", "127.0.0.1");
paramMap.put("notify_url", "http://guli.shop/api/order/weixinPay/weixinNotify");
paramMap.put("trade_type", "NATIVE");
//2、HTTPClient来根据URL访问第三方接口并且传递参数
HttpClient client = new HttpClient("https://api.mch.weixin.qq.com/pay/unifiedorder");
//client设置参数
client.setXmlParam(WXPayUtil.generateSignedXml(paramMap, ConstantPropertiesUtils.PARTNERKEY));
client.setHttps(true);
client.post();
//3、返回第三方的数据
String xml = client.getContent();
Map<String, String> resultMap = WXPayUtil.xmlToMap(xml);
//4、封装返回结果集
Map map = new HashMap<>();
map.put("orderId", orderId);
map.put("totalFee", order.getAmount());
map.put("resultCode", resultMap.get("result_code"));
map.put("codeUrl", resultMap.get("code_url"));
if(null != resultMap.get("result_code")) {
//微信支付二维码2小时过期,可采取2小时未支付取消订单
redisTemplate.opsForValue().set(orderId.toString(), map, 1000, TimeUnit.MINUTES);
}
return map;
} catch (Exception e) {
e.printStackTrace();
return new HashMap<>();
}
}
}
支付后续处理
- 点击支付后,后台会拼接appid, mch_id,partnerkey,订单id ,支付金额,等参数然后发送到微信端口
2.从微信的返回中获取支付的地址codeUrl,然后通过前端组件把codeUrl渲染成二维码
3.用户扫描二维码并支付
4.页面添加定时器方法,每隔3秒去查询一次支付状态
5.如果支付成功,修改支付表里的支付状态。
6.修改订单状态。
7.调用医院接口,通知跟新支付状态。
订单列表
7.8、取消预约订单
1.根据订单号获取订单信息
2,判断当前时间是否超过退号时间
3.调用医院的模拟接口
4.医院模拟系统返回,返回状态是200
5.如果返回状态200,医院系统成功了
微信退款
更新当前订单状态
6.yygh_order项目整合mq给yygh_hosp系统号源+1,并且给就诊人发送消息
7.9、就医提醒功能
定时任务在固定的时间每天早上8点定时给需要看病的人发短信
service-task定时任务每天8点发送消息到mq,然后service-orders系统收到消息,查询所有需要发短信的订单,然后遍历订单,在把消息发送service-msm系统发送消息。
八、 项目功能测试
8.1、测试工具介绍
项目是通过swagger注解表明该接口会生成文档,包括接口名、请求方法、参数、返回信息的等等。
@Api:修饰整个类,描述Controller的作用
@ApiOperation:描述一个类的一个方法,或者说一个接口
@ApiParam:单个参数描述
@ApiModel:用对象来接收参数
@ApiModelProperty:用对象接收参数时,描述对象的一个字段
@ApiImplicitParam:一个请求参数
@ApiImplicitParams:多个请求参数
8.2、swagger2集成
项目整合swagger2
在common模块pom.xml引入依赖
<!--swagger-->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
</dependency>
说明:我们在yygh-parent中的pom.xml中添加了版本控制,这里不需要添加版本,已引入就忽略
8.3、添加swagger2配置类
在service-util模块添加配置类:
com.atguigu.yygh.common.config.Swagger2Config类
/**
* Swagger2配置信息
*/
@Configuration
@EnableSwagger2
public class Swagger2Config {
@Bean
public Docket webApiConfig(){
return new Docket(DocumentationType.SWAGGER_2)
.groupName("webApi")
.apiInfo(webApiInfo())
.select()
//只显示api路径下的页面
.paths(Predicates.and(PathSelectors.regex("/api/.*")))
.build();
}
@Bean
public Docket adminApiConfig(){
return new Docket(DocumentationType.SWAGGER_2)
.groupName("adminApi")
.apiInfo(adminApiInfo())
.select()
//只显示admin路径下的页面
.paths(Predicates.and(PathSelectors.regex("/admin/.*")))
.build();
}
private ApiInfo webApiInfo(){
return new ApiInfoBuilder()
.title("网站-API文档")
.description("本文档描述了网站微服务接口定义")
.version("1.0")
.contact(new Contact("atguigu", "http://atguigu.com", "493211102@qq.com"))
.build();
}
private ApiInfo adminApiInfo(){
return new ApiInfoBuilder()
.title("后台管理系统-API文档")
.description("本文档描述了后台管理系统微服务接口定义")
.version("1.0")
.contact(new Contact("atguigu", "http://atguigu.com", "49321112@qq.com"))
.build();
}
}
8.4、swagger测试页面
九、 全局异常处理
spring boot 默认情况下会映射到 /error 进行异常处理,但是提示并不十分友好,下面自定义异常处理,提供友好展示。
9.1、 自定义异常类
我们在搭建模块时在common-util模块已经添加了YyghException类,这里不做解释
9.2、 添加全局异常处理类
在service-util模块添加全局异常处理类
package com.atguigu.yygh.common.handler;
/**
* 全局异常处理类
*
*/
@ControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(Exception.class)
@ResponseBody
public Result error(Exception e){
e.printStackTrace();
return Result.fail();
}
/**
* 自定义异常处理方法
* @param e
* @return
*/
@ExceptionHandler(YyghException.class)
@ResponseBody
public Result error(YyghException e){
return Result.build(e.getCode(), e.getMessage());
}
}
9.3、 集成测试
手动在controller任意方法制造异常(int i = 1/0),添加GlobalExceptionHandler类与不添加这个类区别
十、 日志
10.1、配置日志级别
日志记录器(Logger)的行为是分等级的。如下表所示:
分为:OFF、FATAL、ERROR、WARN、INFO、DEBUG、ALL
默认情况下,spring boot从控制台打印出来的日志级别只有INFO及以上级别,可以配置日志级别
设置日志级别
logging.level.root=WARN
这种方式只能将日志打印在控制台上
10.2、 Logback日志
spring boot内部使用Logback作为日志实现的框架。
10.3、 配置日志
resources/logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="10 seconds">
<!-- 日志级别从低到高分为TRACE < DEBUG < INFO < WARN < ERROR < FATAL,如果设置为WARN,则低于WARN的信息都不会输出 -->
<!-- scan:当此属性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true -->
<!-- scanPeriod:设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。当scan为true时,此属性生效。默认的时间间隔为1分钟。 -->
<!-- debug:当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。 -->
<contextName>logback</contextName>
<!-- name的值是变量的名称,value的值时变量定义的值。通过定义的值会被插入到logger上下文中。定义变量后,可以使“${}”来使用变量。 -->
<property name="log.path" value="D:/yygh_log/edu" />
<!-- 彩色日志 -->
<!-- 配置格式变量:CONSOLE_LOG_PATTERN 彩色日志格式 -->
<!-- magenta:洋红 -->
<!-- boldMagenta:粗红-->
<!-- cyan:青色 -->
<!-- white:白色 -->
<!-- magenta:洋红 -->
<property name="CONSOLE_LOG_PATTERN"
value="%yellow(%date{yyyy-MM-dd HH:mm:ss}) |%highlight(%-5level) |%blue(%thread) |%blue(%file:%line) |%green(%logger) |%cyan(%msg%n)"/>
<!--输出到控制台-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!--此日志appender是为开发使用,只配置最底级别,控制台输出的日志级别是大于或等于此级别的日志信息-->
<!-- 例如:如果此处配置了INFO级别,则后面其他位置即使配置了DEBUG级别的日志,也不会被输出 -->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<encoder>
<Pattern>${CONSOLE_LOG_PATTERN}</Pattern>
<!-- 设置字符集 -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!--输出到文件-->
<!-- 时间滚动输出 level为 INFO 日志 -->
<appender name="INFO_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${log.path}/log_info.log</file>
<!--日志文件输出格式-->
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
<charset>UTF-8</charset>
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 每天日志归档路径以及格式 -->
<fileNamePattern>${log.path}/info/log-info-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!--日志文件保留天数-->
<maxHistory>15</maxHistory>
</rollingPolicy>
<!-- 此日志文件只记录info级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>INFO</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 时间滚动输出 level为 WARN 日志 -->
<appender name="WARN_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${log.path}/log_warn.log</file>
<!--日志文件输出格式-->
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
<charset>UTF-8</charset> <!-- 此处设置字符集 -->
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${log.path}/warn/log-warn-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!--日志文件保留天数-->
<maxHistory>15</maxHistory>
</rollingPolicy>
<!-- 此日志文件只记录warn级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>warn</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 时间滚动输出 level为 ERROR 日志 -->
<appender name="ERROR_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${log.path}/log_error.log</file>
<!--日志文件输出格式-->
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
<charset>UTF-8</charset> <!-- 此处设置字符集 -->
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${log.path}/error/log-error-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!--日志文件保留天数-->
<maxHistory>15</maxHistory>
</rollingPolicy>
<!-- 此日志文件只记录ERROR级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!--
<logger>用来设置某一个包或者具体的某一个类的日志打印级别、以及指定<appender>。
<logger>仅有一个name属性,
一个可选的level和一个可选的addtivity属性。
name:用来指定受此logger约束的某一个包或者具体的某一个类。
level:用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF,
如果未设置此属性,那么当前logger将会继承上级的级别。
-->
<!--
使用mybatis的时候,sql语句是debug下才会打印,而这里我们只配置了info,所以想要查看sql语句的话,有以下两种操作:
第一种把<root level="INFO">改成<root level="DEBUG">这样就会打印sql,不过这样日志那边会出现很多其他消息
第二种就是单独给mapper下目录配置DEBUG模式,代码如下,这样配置sql语句会打印,其他还是正常DEBUG级别:
-->
<!--开发环境:打印控制台-->
<springProfile name="dev">
<!--可以输出项目中的debug日志,包括mybatis的sql日志-->
<logger name="com.guli" level="INFO" />
<!--
root节点是必选节点,用来指定最基础的日志输出级别,只有一个level属性
level:用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF,默认是DEBUG
可以包含零个或多个appender元素。
-->
<root level="INFO">
<appender-ref ref="CONSOLE" />
<appender-ref ref="INFO_FILE" />
<appender-ref ref="WARN_FILE" />
<appender-ref ref="ERROR_FILE" />
</root>
</springProfile>
<!--生产环境:输出到文件-->
<springProfile name="pro">
<root level="INFO">
<appender-ref ref="CONSOLE" />
<appender-ref ref="DEBUG_FILE" />
<appender-ref ref="INFO_FILE" />
<appender-ref ref="ERROR_FILE" />
<appender-ref ref="WARN_FILE" />
</root>
</springProfile>
</configuration>
十一、 网关服务
API 网关是介于客户端和服务器端之间的中间层,所有的外部请求都会先经过 API 网关这一层。也就是说,API 的实现方面更多的考虑业务逻辑,而安全、性能、监控可以交由 API 网关来做,这样既提高业务灵活性又不缺安全性。
Spring cloud gateway是spring官方基于Spring 5.0、Spring Boot2.0和Project Reactor等技术开发的网关,Spring Cloud Gateway旨在为微服务架构提供简单、有效和统一的API路由管理方式,Spring Cloud Gateway作为Spring Cloud生态系统中的网关,目标是替代Netflix Zuul,其不仅提供统一的路由方式,并且还基于Filer链的方式提供了网关基本的功能,例如:安全、监控/埋点、限流等。
Cloud Gateway中几个重要的概念。
(1)路由。路由是网关最基础的部分,路由信息有一个ID、一个目的URL、一组断言和一组Filter组成。如果断言路由为真,则说明请求的URL和配置匹配
(2)断言。Java8中的断言函数。Spring Cloud Gateway中的断言函数输入类型是Spring5.0框架中的ServerWebExchange。Spring Cloud Gateway中的断言函数允许开发者去定义匹配来自于http request中的任何信息,比如请求头和参数等。
(3)过滤器。一个标准的Spring webFilter。Spring cloud gateway中的filter分为两种类型的Filter,分别是Gateway Filter和Global Filter。过滤器Filter将会对请求和响应进行修改处理
如图所示,Spring cloud Gateway发出请求。然后再由Gateway Handler Mapping中找到与请求相匹配的路由,将其发送到Gateway web handler。Handler再通过指定的过滤器链将请求发送到实际的服务执行业务逻辑,然后返回。
11.1、service_gateway模块
11.2、在pom.xml引入依赖
<dependencies>
<dependency>
<groupId>com.atguigu.yygh</groupId>
<artifactId>common-util</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!-- 服务注册 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
</dependencies>
11.3、编写application.properties配置文件
服务端口
server.port=8222
服务名
spring.application.name=service-gateway
nacos服务地址
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
#使用服务发现路由
spring.cloud.gateway.discovery.locator.enabled=true
#设置路由id
spring.cloud.gateway.routes[0].id=service-hosp
#设置路由的uri
spring.cloud.gateway.routes[0].uri=lb://service-hosp
#设置路由断言,代理servicerId为auth-service的/auth/路径
spring.cloud.gateway.routes[0].predicates= Path=/*/hosp/**
#设置路由id
spring.cloud.gateway.routes[1].id=service-cmn
#设置路由的uri
spring.cloud.gateway.routes[1].uri=lb://service-cmn
#设置路由断言,代理servicerId为auth-service的/auth/路径
spring.cloud.gateway.routes[1].predicates= Path=/*/cmn/**
#设置路由id
spring.cloud.gateway.routes[2].id=service-user
#设置路由的uri
spring.cloud.gateway.routes[2].uri=lb://service-user
#设置路由断言,代理servicerId为auth-service的/auth/路径
spring.cloud.gateway.routes[2].predicates= Path=/*/user/**
#设置路由id
spring.cloud.gateway.routes[3].id=service-msm
#设置路由的uri
spring.cloud.gateway.routes[3].uri=lb://service-msm
#设置路由断言,代理servicerId为auth-service的/auth/路径
spring.cloud.gateway.routes[3].predicates= Path=/*/msm/**
#设置路由id
spring.cloud.gateway.routes[4].id=service-user
#设置路由的uri
spring.cloud.gateway.routes[4].uri=lb://service-user
#设置路由断言,代理servicerId为auth-service的/auth/路径
spring.cloud.gateway.routes[4].predicates= Path=/*/ucenter/**
#设置路由id
spring.cloud.gateway.routes[5].id=service-oss
#设置路由的uri
spring.cloud.gateway.routes[5].uri=lb://service-oss
#设置路由断言,代理servicerId为auth-service的/auth/路径
spring.cloud.gateway.routes[5].predicates= Path=/*/oss/**
#设置路由id
spring.cloud.gateway.routes[6].id=service-orders
#设置路由的uri
spring.cloud.gateway.routes[6].uri=lb://service-orders
#设置路由断言,代理servicerId为auth-service的/auth/路径
spring.cloud.gateway.routes[6].predicates= Path=/*/order/**
#设置路由id
spring.cloud.gateway.routes[7].id=service-sta
#设置路由的uri
spring.cloud.gateway.routes[7].uri=lb://service-sta
#设置路由断言,代理servicerId为auth-service的/auth/路径
spring.cloud.gateway.routes[7].predicates= Path=/*/statistics/**
11.4、网关解决跨域问题
@Configuration
public class CorsConfig {
@Bean
public CorsWebFilter corsFilter() {
CorsConfiguration config = new CorsConfiguration();
config.addAllowedMethod("*");
config.addAllowedOrigin("*");
config.addAllowedHeader("*");
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource(new PathPatternParser());
source.registerCorsConfiguration("/**", config);
return new CorsWebFilter(source);
}
}
目前我们已经在网关做了跨域处理,那么service服务就不需要再做跨域处理了,将之前在controller类上添加过@CrossOrigin标签的去掉,防止程序异常。

















 8238
8238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









