











近年来,人工智能技术在全球范围内取得了显著的成果,特别是在计算机视觉、自然语言处理、语音识别等领域。这些成果的取得离不开大规模预训练模型的支撑。大模型通过在海量数据上进行预训练,能够捕捉到数据的深层次特征,从而在各类任务中取得优异的表现。如今,大模型已成为人工智能发展的重要方向,为各行各业带来了前所未有的变革。
大模型的概念与分类
大模型,顾名思义,是指参数规模较大的预训练模型。这些模型通常具有数十亿甚至数千亿个参数,需要在大量硬件资源上进行训练。大模型通过对数据进行分布式表示,能够捕捉到数据中的复杂关系,提高模型在各类任务中的泛化能力。
根据应用场景和任务类型,大模型可分为以下几类:
(1)通用大模型:如GPT、BERT等,能够处理多种类型的任务,如文本生成、文本分类、机器翻译等。
(2)领域特定大模型:针对特定领域,如计算机视觉领域的Transformer、自然语言处理领域的XLNet等。
(3)多模态大模型:能够处理多种模态的数据,如图像、文本、语音等,如CLIP、DALL-E等。
大模型的发展历程
-
早期探索:20世纪90年代,深度学习技术逐渐兴起,研究者们开始探索大规模神经网络模型。
-
2012年,AlexNet模型的提出,标志着深度学习在计算机视觉领域的突破。
-
2018年,BERT模型的提出,开启了自然语言处理领域的大模型时代。
-
2020年,GPT-3模型的发布,将大模型参数规模推向千亿级别,引发了广泛关注。
大模型的技术特点
-
参数规模大:大模型具有数十亿甚至千亿级别的参数,能够捕捉到数据中的深层次特征。
-
训练数据量大:大模型通常在数百GB甚至TB级别的数据上进行预训练,提高了模型的泛化能力。
-
计算资源需求高:大模型训练过程中需要大量计算资源,如GPU、TPU等。
-
模型泛化能力强:大模型在各类任务中表现出色,具有较强的泛化能力。
大模型的应用场景
-
自然语言处理:大模型在文本生成、文本分类、机器翻译等任务中取得了显著成果。
-
计算机视觉:大模型在图像分类、目标检测、图像生成等任务中表现出色。
-
语音识别:大模型在语音识别、语音合成等任务中取得了突破性进展。
-
多模态任务:大模型能够处理多种模态的数据,如图像描述生成、视频分类等。
大模型带来的机遇与挑战
-
机遇:大模型为人工智能技术发展提供了新方向,有望在更多领域实现突破。大模型具有强大的泛化能力,有助于降低人工智能应用的开发成本。
-
挑战:大模型可能导致数据隐私泄露,需要加强对数据安全的保护。大模型训练过程中计算资源需求高,能耗大,需要解决算力不足、能耗过高的问题。
大模型作为人工智能领域的重要研究方向,正引领着我国人工智能产业迈向新的发展阶段。面对大模型带来的机遇与挑战,我们需要加强技术创新,优化模型结构,提高计算效率,确保数据安全,为我国人工智能产业的发展贡献力量。
大模型相关技术项目发展很快,层出不穷,学习大模型,需要抓住其基础。本系列给了一个大模型的基础教程,包括词向量、分析模型、序列模型、注意力模型、Transformer结构等,能够快速入门。

\`**黑客&网络安全如何学习**
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
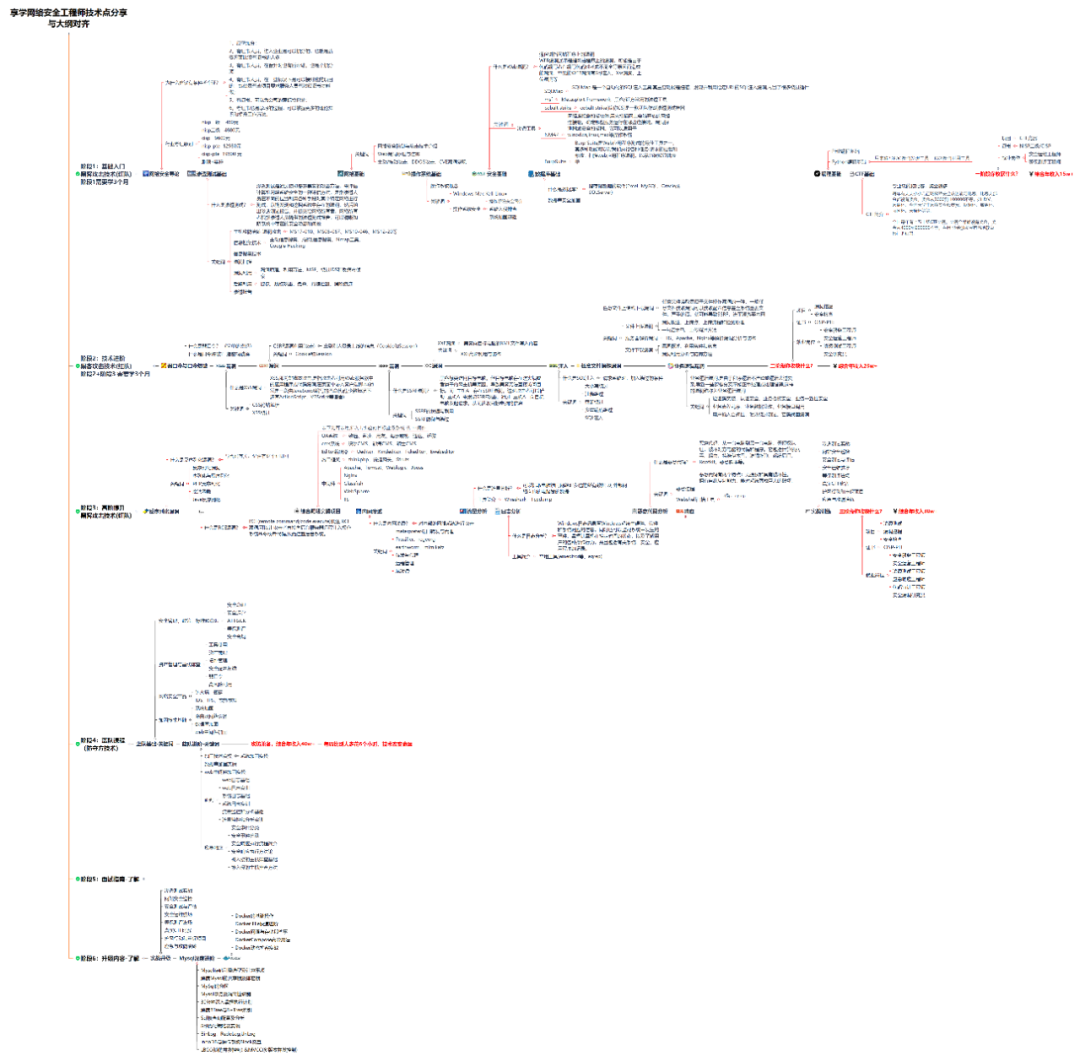
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。

(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取















 1429
1429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









