






两篇文章相同点:
都使用的SwinTransformer
都是双分支,IR和VIS分开提取特征。
不同点:
1. SwinFuse是一个全Transformer的网络,并且只适用于IVIF,SwinFusion是一个通用融合框架,并且援引《Early convolutions help transformers see better》The convolutional layers are good at early visual processing, resulting in more stable optimization and better results。在早期还是使用CNN提取浅层特征和堆叠CNN提取深层特征。
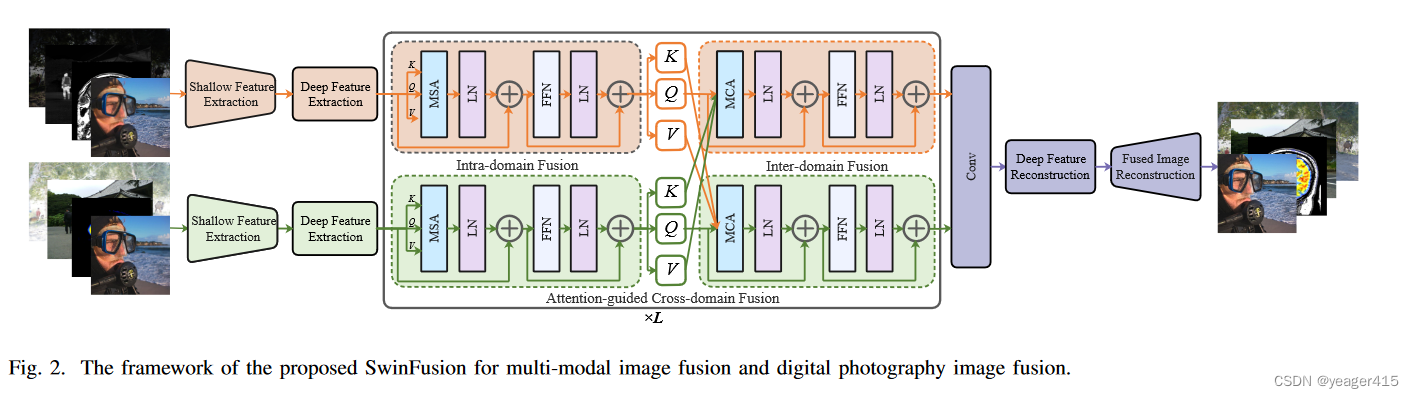
2.SwinFusion提出了使用SA增强intra-domain 和使用CA增强inter-domain特征的概念。
SwinFusion在特征融合阶段使用了两层SA-CA,在重建阶段则是使用了4层SwinTR。没有使用融合策略。
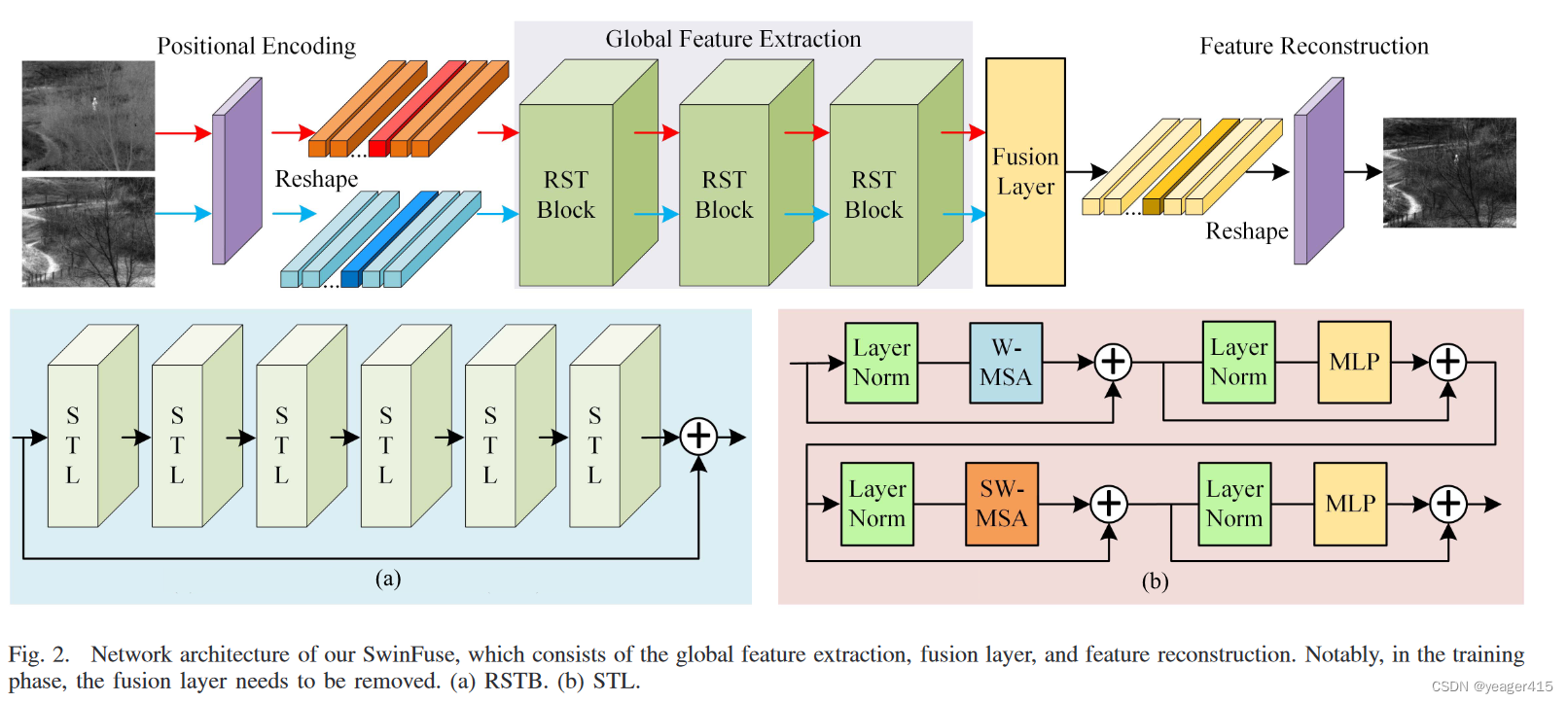
SwinFuse则是在一开始阶段使用了1by1conv实现了位置编码,然后再送入SwinTR块,这里设置了3个块,每个块里有6层。
在融合层,使用了一个基于L1-norm的融合策略,分别从行和列的维度计算活动级别图。
SwinFuse,patch size 设置为1,(这不就相当于没划分嘛)windowsize设置为7
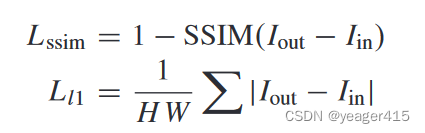
这里的L1就是强度损失啦,只不过没有权重来平衡IR和VIS的参与比重。

















 2658
2658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









