







摘要
本文回顾了第二届AIM学习型ISP挑战赛,并对提出的解决方案和结果进行了描述。参赛团队正在解决一个真实世界的RAW-RGB映射问题,目标是将华为P20设备拍摄的原始低质量RAW图像映射到用佳能5D单反相机拍摄的相同照片。所考虑的任务包含了许多复杂的计算机视觉子任务,如图像去马赛克、去噪、白平衡、颜色和对比度校正、去噪等。这项挑战中使用的目标指标将保真度分数(PSNR和SSIM)与用户研究中测量的解决方案的感知结果结合起来。所提出的解决方案大大改善了基线结果,定义了实用图像信号处理管道建模的最先进水平。
1 引言
最近,深度学习、端到端学习范式、对抗性学习的出现以及内存和计算硬件的不断改进导致了包括计算机视觉、图形和计算摄影在内的许多研究领域的巨大进步。特别是,图像恢复、增强和处理主题引起了研究人员越来越多的兴趣,这导致定义和提出新解决方案以改善不同图像质量方面的工作激增 [39,4,2,5,11,3, 32,12],包括它的分辨率、模糊、噪声、色彩再现、感知质量等。现实世界中最重要的问题之一是恢复和增强便携式移动设备 [15,18,20,21,7] 中可用的紧凑型相机传感器记录的低质量图像,这些设备是当今媒体记录的主要来源。 2017 年,第一个作品被提出来处理全面的图像增强 [15,16]。紧随其后的是大量后续论文,这些论文显着改善了基线结果 [34,37,40,14,27]。智能手机感知图像增强的 PIRM 挑战 [21]、NTIRE 2019 图像增强挑战 [17] 与不同的 DPED 数据集 [15] 以及其他几个 NTIRE 和 AIM 挑战有助于产生大量高效解决方案和该领域的进一步发展。
AIM 2020 对学习图像信号处理管道的挑战是在基于示例的单图像增强基准测试方面向前迈出的一步。与第一个 RAW 到 RGB 映射挑战 [19] 相同,它的目标是处理和增强使用小型移动相机传感器获得的 RAW 照片。 AIM 2020 挑战赛使用大规模苏黎世 RAW 到 RGB (ZRR) 数据集 [24],包括使用华为 P20 移动相机和佳能 5D 数码单反相机拍摄的 RAW 照片,并考虑了所提出的定量和定性视觉结果解决方案。在接下来的部分中,我们将描述挑战和相应的数据集,展示和讨论结果并描述所提出的方法。
该挑战是 AIM 2020 相关挑战之一:场景重新照明和照明估计 [9]、图像极端修复 [33]、学习的图像信号处理管道 [22]、渲染逼真的散景 [23]、真实图像超分辨率 [ 41]、高效超分辨率[42]、视频时间超分辨率[36]和视频极端超分辨率[10]。
2 AIM 2020 学习图像信号处理管道挑战
RAW 到 RGB 映射任务的最大挑战之一是获得可用于训练深度模型的高质量真实数据。为了解决这个问题,我们使用了一个包含 2 万张照片的大规模 ZRR 数据集 [24] 数据集,这些照片是使用华为 P20 智能手机拍摄 RAW 照片和配备佳能 EF 24mm f/ 的专业高端佳能 5D Mark IV 相机收集的。 1.4L快速镜头。 RAW 数据是从 P20 的 12.3 MP Sony Exmor IMX380 Bayer 摄像头传感器读取的——虽然这款手机有第二个 20 MP 单色摄像头,但它仅用于华为内部 ISP 系统,并且无法使用任何公共摄像头 API 检索相应的图像。这些照片是在自动模式下拍摄的,并且在整个收集过程中都使用了默认设置。这些数据是在数周内在不同地点、不同光照和天气条件下收集的。图 1 显示了一组捕获图像的示例。
由于捕获的RAW-RGB图像对不是完全对齐的,我们首先使用与[15]相同的程序进行匹配。首先使用SIFT关键点和RANSAC算法对图像进行全局对齐。然后,使用非重叠的滑动窗口从初步匹配的图像中提取大小为448×448的小斑块。两个窗口沿着每对RAW-RGB图像平行移动,窗口在单反相机图像上的位置也通过小的移动和旋转进行调整,以最大限度地提高观察到的斑块之间的交叉相关性。交叉相关度小于0.9的斑块不包括在数据集中,以避免大的位移。这个过程产生了48043个RAW-RGB图像对(尺寸分别为448×448×1和448×448×3),后来被用于训练/验证(46.8K)和测试(1.2K)模型。另外,RAW图像补丁被重塑为224×224×4的大小,其中四个通道对应于RGBG Bayer filer的四种颜色。应该提到的是,所有对齐操作只在RGB单反相机图像上进行,因此来自华为P20的RAW照片仍然没有修改,包含与从相机传感器获得的相同值。
2.1 Tracks and Competitions
挑战赛包括以下几个阶段:
i开发:参与者获得数据;
ii验证:参与者有机会在服务器上验证他们的解决方案,并在验证排行榜上比较结果;
iii测试:参与者提交他们的最终结果、模型和事实表。
所有提交的解决方案都根据三种措施进行评估。
- PSNR测量保真度得分,
- SSIM,感知得分的代理,
- MOS得分在用户研究中测量,用于明确的图像质量评估。
AIM 2020 学习 ISP 管道挑战包括两个轨道。在第一个“保真度”轨道中,目标是获得通过 PSNR 和 SSIM 指标测量的对地面实况具有最高像素保真度的输出图像。由于 SSIM 和 PSNR 分数并不能反映真实图像质量的许多方面,因此在第二个“感知”轨道中,我们正在根据其平均意见分数 (MOS) 评估解决方案。为此,我们进行了一项用户研究,评估所有提出的方法的视觉结果。要求用户通过选择五个质量级别之一(5 - 可比较的图像质量,4 - 稍差,3 - 明显更差,2 - 图像质量差)来评估每个提交的解决方案的质量(基于 42 个全分辨率增强测试图像)质量,1 - 完全损坏的图像)与原始佳能图像相比,每种方法的结果。表达的偏好对每个测试图像进行平均,然后按每种方法进行平均以获得最终的 MOS。
3 Challenge Results

表 1. AIM 2020 学习的 ISP 管道挑战结果和最终排名。根据 MOS 分数对结果进行排序
第 1 场挑战赛吸引了 110 多名注册参与者,第 2 场比赛吸引了 80 多名参赛者。然而,只有 11 个团队在最后阶段提供了结果以及情况说明书和可重复性代码。表 1 总结了两个轨道中每个提交的解决方案的 PSNR、SSIM 和 MOS 分数以及自我报告的硬件/软件配置和运行时间方面的最终测试阶段挑战结果。第 4 节提供了建议解决方案的简短描述,附录 A 中列出了团队详细信息(联系电子邮件、成员和附属机构)3.1 Architectures and Main Ideas
所有提出的方法都依赖于端到端的基于深度学习的解决方案。大多数提交的模型都具有多尺度编码器-解码器架构,并且正在处理多个尺度的图像。这允许引入全局图像处理并提高训练速度/减少 GPU RAM 消耗,因为所有繁重的图像处理都是在低分辨率图像上完成的。此外,许多挑战参与者使用通道注意 RCAN [43] 模块和各种残差连接以及离散小波变换层而不是标准池化层来防止信息丢失。大多数团队都在使用 MSE、L1、SSIM、基于 VGG 和基于颜色的损失函数,而只有一个团队考虑了 GAN 损失。几乎所有参与者都在使用 Adam 优化器 [26] 来训练深度学习模型和 PyTorch 框架来实现和训练网络。
3.2 Performance
Quality
Airia CG 团队在 Track 1 中以最佳 PSNR 和 SSIM 分数实现了最佳保真度,而 MW-ISPNet 团队是 Track 2 的获胜者,通过用户研究实现了由平均意见分数 (MOS) 衡量的最佳感知质量。 Airia CG、MW-ISPNet 和 skyb 是唯一向这两个赛道提交不同解决方案的团队。仅次于 MW-ISPNet 的 22.26dB PSNR,在 [21.86-21.93] 范围内有四个团队的结果相似。我们还注意到 PSNR / SSIM 分数与感知排名之间存在良好的相关性:最差的感知质量是由具有最低 PSNR 和 SSIM 分数的解决方案实现的。值得注意的例外是 Eureka 和 Airia CG 为 track 2 提出的具有良好感知质量但 PSNR 较差的解决方案。 MacAI 提供了一个在保真度(21.86dB PSNR)和感知质量(4.5 MOS,仅次于 MW-ISPNet)之间取得良好平衡的解决方案。
运行。在这一挑战中,最佳保真度和最佳感知质量获胜解决方案也是计算要求更高的解决方案之一。 MW-ISPNet 报告每个图像裁剪大约 1S。同时,速度快了一个数量级的解决方案在两条轨道中都排在最后。
3.3 Discussion
AIM 2020关于学习型图像信号处理(ISP)管道的挑战促进了一个新的研究方向,旨在用数据驱动的学习型解决方案取代目前繁琐而昂贵的手工ISP解决方案,并能够在图像质量方面超越它们。为此,参赛者被要求将智能手机摄像头的RAW图像映射到商业手工ISP产生的RGB输出,而是映射到高端单反相机拍摄的高质量图像。这项挑战采用了ZRR数据集[24],其中包含用华为P20智能手机和佳能5D Mark IV单反相机拍摄的配对和对齐的照片。许多提议的方法在感知质量方面比原始RAW图像在单反相机质量目标的方向上有明显的改善。通过提出的解决方案的挑战,定义了实际学习的ISP aka RAW到RGB图像映射任务的最先进水平。
4 挑战方法和团队
本部分描述了所有参与 AIM 2020 学习 ISP 管道挑战最后阶段的团队提交的解决方案。
4.1 MW-ISPNet

图 2. MW-ISPNet 多级小波网络。
MW-ISPNet 团队提出了一种基于 U-Net 的多级小波 ISP 网络(MW-ISPNet),如图 2 所示,它利用了 MWCNN [28] 和 RCAN [43] 架构。在该模型的每个 U-Net 级别中,嵌入了一个由 20 个残差通道注意块 (RCAB) 组成的残差组 (RG)。标准的下采样和上采样操作被基于离散小波变换 (DWT) 的分解所取代,以最大限度地减少这些层中的信息损失。该模型使用 Adam 算法结合基于 L1、SSIM 和 VGG 的损失函数进行训练。在保真度跟踪中,作者使用在 SIDD [1] 数据集上训练的附加 MW-ISPNet 模型来执行原始图像去噪,其输出被传递到主 MW-ISPNet 模型。在感知轨道上,作者在 LSGAN [30] 论文之后添加了对抗性损失,以提高生成图像的感知质量。最后,作者使用了一种自集成方法,对同一模型的八个输出进行平均,该模型将翻转和旋转的图像作为输入。4.2 MacAI
MacAI 团队利用注意力机制和小波变换展示了 AWNet 模型 [8](图 3),该模型由三个块组成:横向块、上采样块和下采样块。横向块由几个残余密集块(RDB)和一个全局上下文块(GCB)组成[6]。与之前的团队一样,作者使用离散小波变换 (DWT) 代替池化层来保留低频信息,尽管他们另外使用与 DWT 层并行的标准缩减卷积和像素混洗层来获得更丰富的学习特征。最后,作者训练了一个额外的模型,该模型将一个简单的去马赛克原始图像作为输入(而不是四个 Bayer 通道),并将两个模型的输出结合起来生成最终图像。
该模型结合了 Charbonnier、SSIM 和基于 VGG 的损失函数进行了训练。使用 Adam 算法优化模型的参数,初始学习率为 1e-4,每 10 个 epoch 减半。使用了对来自同一模型的八个输出进行平均的自集成方法。
4.3 Vermilion Vision
Vermilion Vision 的解决方案基于 Scale-Recurrent Networks [38]。所提出模型的架构如图 4 所示:它由 4 个尺度组成(虽然这里只显示了两个尺度),在最后一层之后使用 tanh 激活函数来实现更好的色调映射效果。作者使用去马赛克(使用传统的 DDFAPD 算法)图像作为模型的输入,并训练网络以最小化标准 MSE 损失函数。为了获得最终结果,作者还对最佳 3 个模型的输出进行了平均。
4.4 Eureka

图 5. Eureka 团队提出的带有 RISE 和 ESPy 模块的网络架构
Eureka提出的解决方案(图5)是使用一个带有挤压和激发(RISE)模块的残余起始模块和一个高效空间金字塔(ESPy)模块。第一个模块有三条平行路径,用于具有不同感受野的卷积层,主要集中在低级别的操作上。 在这个模块中产生的特征被串联起来,并通过控制每个通道的重要性/权重的挤压块和激发块。第二个模块的目标是高层次的增强,它有四个平行的路径,具有扩张的卷积层和不同的扩张率,以覆盖更大的图像区域。
RISE模块序列获得的输出分为两部分:前12个通道通过子像素卷积层以获得RGB通道,其他通道通过ESPy模块序列。最终的输出是作为上述RGB通道的线性回归得到的,其权重是由最后的ESPy模块的输出给出的。该网络被训练成最小化以下五种损失的组合:平均绝对误差(MAE)、颜色损失(以RGB向量之间的余弦距离衡量)、SSIM、基于VGG和曝光融合的损失[31]。该模型的参数使用亚当算法进行了400次历时优化。
4.5 Airia CG
Airia CG 团队在这次挑战中使用了两种不同的方法。在感知跟踪中,它提出了渐进式 U-Net(PU-Net)架构(图 6,底部),该架构本质上是一个增强了对比度感知通道注意模块 [13]、可切换归一化层 [29] 的 U-Net 模型] 和用于对图像进行上采样的像素洗牌层。作者还通过去除所有模糊照片来清理提供的 ZRR 数据集,并使用获得的图像子集来训练模型。在保真度跟踪中,作者使用了六种不同模型的集合:上述 PU-Net 模型、PyNET [24] 和四个 EEDNets [44](图 6,顶部),架构略有不同:与 EEDNetv2 相比,EEDNetv1 使用简单的复制和裁剪而不是 RRDB 模块,EEDNetv4 在 RRDB 模块之后添加了一个对比度感知通道注意模块。与最佳单一模型相比,所考虑的集成能够将验证数据集上的 PSNR 提高 0.61dB。
4.6 Baidu Research Vision
百度团队基于马赛克自适应密集残差网络的解决方案(图7)。在模型的开头有一个马赛克跨度卷积层,用于提取马赛克自适应的浅层特征。该模型与RCAN[43]一样,用额外的通道注意模块来增强。该网络是用L1和SSIM损失函数的组合来训练的,另外还使用了一个自组装策略来生成最终结果。


图 6 Airia CG 提出的渐进式 U-Net 和 EEDNetv2 架构。
4.7 SkybSkyb 提出了一个 PyNet-CA 模型 [25](图 8),它在标准 PyNET [24] 架构的基础上增加了一些增强功能。特别是,作者在多卷积层的输出之上添加了 RCAN 风格的通道注意 [43]。除此之外,删除了一些实例归一化操作,使用额外的多卷积层来放大最终图像,并使用不同的单周期学习率策略 [35] 来训练模型的每个级别。该网络使用 MSE、基于 VGG 和 SSIM 损失函数的组合进行训练,根据轨道和 PyNET 级别采用不同的组合,另外还应用了自集成策略来生成最终输出。

图 7 百度提出的马赛克自适应密集残差网络。

图 8 Skyb 团队提出的 PyNet-CA 模型。
4.8 STAIRSTAIR 使用图 9 所示的 RRGNet 模型来恢复 RGB 图像。该网络利用空间注意力 (SA) 和通道注意力 (CA) 块的组合,通过 CNN 模块之间的残差连接增强。该模型经过训练以最小化 L1 损失,其参数使用 Adam 算法优化了 30 个 epoch,另外还应用了自集成策略来生成最终输出。


图 9. STAIR 团队使用的 RRGNet 模型。

图 10. SenseBrainer 提出的多尺度 U-Net 架构。
4.9 SenseBrainerSenseBrainer 为所考虑的任务提出了一个多尺度 U-Net 模型,如图 10 所示。作者首先使用 Demosaic-Net 处理原始图像,以生成无需颜色校正即可重建的 RGB 图像。然后对多尺度 UNet 进行训练,以结合 MSE、颜色相似性和基于 VGG 的损失来恢复图像颜色,权重取决于训练规模。作者还从数据集中删除了损坏/未对齐的图像,以使训练更加稳健。
4.10 Bupt-mtc206


图 11 Bupt-mtc206 团队使用的 RRGNet 模型。
与 STAIR 团队类似,作者试图将 RRGNet 模型(图 11)应用于所考虑的问题。由于硬件问题,作者无法在全分辨率图像上运行他们的解决方案,因此他们不得不在最终提交时使用拼接方法。4.11 BingSoda
BingSoda 团队展示了一个像素级颜色距离 (PWCD) 模型,如图 12 所示。该模型使用 LAB 颜色空间而不是 RGB 空间,并经过训练以最小化预测图像和目标图像之间的 CIELAB 色差。
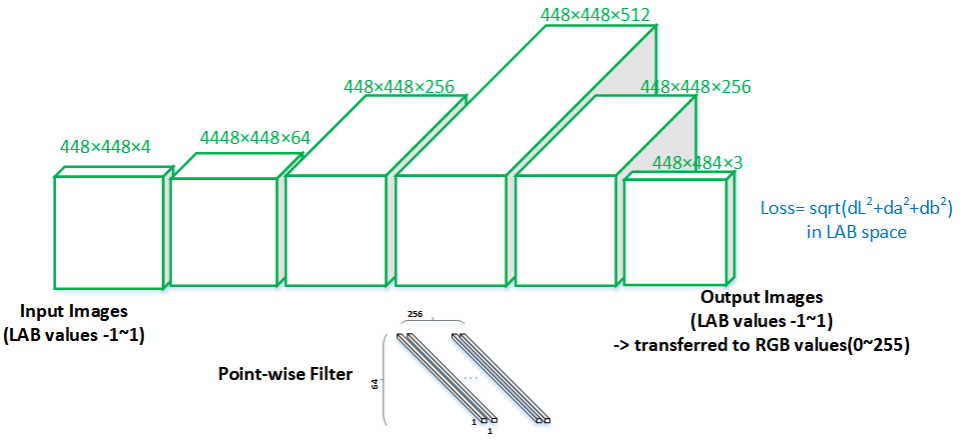
图 12. BingSoda 团队提出的 PWCD 模型。
项目和论文名称汇总MW-ISPNet
Title: Multi-level Wavelet ISP Network
MacAI
Title: Attentive Wavelet Network for Image ISP [8]
Vermilion Vision
Title: Scale Recurrent Deep Tone Mapping
Eureka
Title: Local and Global Enhancement Network as Learned ISP
Airia CG
Title 1: EEDNet: Enhanced Encoder-Decoder Network
Title 2: PUNet: Progressive U-Net via Contrast-aware Channel Attention
Baidu Research Vision
Title: Learned Smartphone ISP using Mosaic-Adaptive Dense Residual Network
Skyb
Title: PyNet-CA: Enhanced PyNet with Channel Attention for Mobile ISP
STAIR
Title: Recursive Residual Group Network for Image Mapping
SenseBrainer
Title: Multiscaled UNet
Bupt-mtc206
Title: RRGNet for Smartphone ISP
BingSoda
Title: Pixel-Wise Color Distance (PWCD model)
References
- Abdelhamed, A., Lin, S., Brown, M.S.: A high-quality denoising dataset for smartphone cameras. In: Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition. pp. 1692–1700 (2018) - Abdelhamed, A., Timofte, R., Brown, M.S., et al.: Ntire 2019 challenge on real
image denoising: Methods and results. In: The IEEE Conference on Computer
Vision and Pattern Recognition (CVPR) Workshops (2019) - Ancuti, C.O., Ancuti, C., Timofte, R., et al.: Ntire 2019 challenge on image dehazing: Methods and results. In: The IEEE/CVF Conference on Computer Vision
and Pattern Recognition (CVPR) Workshops (2019) - Blau, Y., Mechrez, R., Timofte, R., Michaeli, T., Zelnik-Manor, L.: The 2018 pirm
challenge on perceptual image super-resolution. In: The European Conference on
Computer Vision (ECCV) Workshops (September 2018) - Cai, J., Gu, S., Timofte, R., Zhang, L., et al.: Ntire 2019 challenge on real image
super-resolution: Methods and results. In: The IEEE Conference on Computer
Vision and Pattern Recognition (CVPR) Workshops (June 2019) - Cao, Y., Xu, J., Lin, S., Wei, F., Hu, H.: Gcnet: Non-local networks meet squeezeexcitation networks and beyond. In: Proceedings of the IEEE International Conference on Computer Vision Workshops. pp. 0–0 (2019)














 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









