







 本文介绍了分类问题中的线性模型,包括两类和多类情况。讨论了判别函数的概念,如Least Squares、Fisher's Linear Discriminant和Perceptron Algorithm,并解释了它们在解决线性可分问题时的作用和局限性。
本文介绍了分类问题中的线性模型,包括两类和多类情况。讨论了判别函数的概念,如Least Squares、Fisher's Linear Discriminant和Perceptron Algorithm,并解释了它们在解决线性可分问题时的作用和局限性。
4 Linear Models for classification
这一章开始介绍分类问题的线性模型。在具体介绍之前,先介绍几个概念。
为什么说是线性模型,因为在这一类模型中,决策面是输入向量x的线性函数,这个线性不同于回归模型中的线性,线性回归模型指的是模型是参数的线性函数。什么是“线性可分”?数据集可以被我们前面说的x的线性决策面分开,则称数据集是“线性可分的”。
在第一章中,曾经介绍过有三种方法可以解决分类问题:1.判别函数 2.直接对p(ck|x)建模(判别模型) 3.对p(x|ck),p(x)分别建模,再利用贝叶斯理论,计算后验概率p(ck|x)。
这一章前三节分别讲了这三种方法,下面首先进入判别函数的介绍。
4.1 Discriminant Functions
4.1.1 Two classes
先来考虑比较简单的x的分类目标K=2,即只有两类的情况。
最简单的判别函数当然是取x的线性函数:
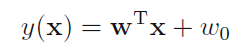
当y(x)>=0的时候,把x归为C1类,当y(x)<0的时候,把x归为C2类,所以这里的决策面就是wx+w0=0。作者之后又对此进行了一些几何角度的解释,w0控制的是决策面的位置,w控制的是决策面的方向(注意后面的Fisher Linear Discriminant要用到这个结论)。
4.1.2 Multiple classes
当K>=2,即x的分类目标大于两类的时候,无论我们用K-1个(not in that class)或者是K(K-1)/2(every possible pair of classes)个4.1.1节讲到的"two classes classifier",都会引出一个ambiguous region。所以面对K类问题时,采用如下方法:
考虑一个包含K个线性判别函数的K分类器:
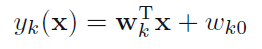
只有当对于任何j!=k,都有yk(x)>yj(x)时,把x归于第K类。之前的“两类”问题,我们既可以用4.1.1中的一个y(x)解决,也可以用类似于这里的y1(x),y2(x)来解决。
讨论过判别函数的具体形式之后,该讨论一下如何来拟合判别函数中的参数w了。书上大致讲了三种方法,least squares,FLD,perceptron algorithm。
4.1.3 Least squares for classification
在第三章中,Least squares是常用的Loss函数,所以很自然的,就会想到在这里最小平方适不适用。但在这最小平方没有任何概率解释,唯一的解释是当Loss函数是最小平方的时候,对E[L]求最小值,会得到y(x)取E[t|x]时E[L]最小的结论,而在“两类”问题中,E[t|x]是后验概率的向量?(这个点上不太懂,就是E[t|x]是怎么由后验概率给出的)。
当面对K类问题时,我们有K组w向量,x,t也相同(这里的t是1-of-K coding scheme),所以把这三组量都表示为矩阵形式的时候,我们得到了error function:
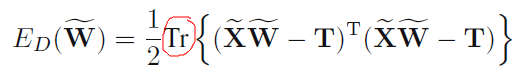
这里为什么求的是矩阵的迹?
这样我们就可以通过最小化error function来解出W:
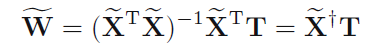
作者接下来讲了一些least squares的弊端,首先,无法保证y(x)的取值在0到1之间。其次对于噪声点的鲁棒性也比较差,书上两幅图4.4和4.5对此做了解释。最后,作者大致讲了一下最小平方法效果不太好的原因,因为在回归问题中,我们是在对目标值做了高斯分布的假设之后得出least square的,而在分类问题中,目标值只有两种取值,显然和高斯分布相去甚远。
4.1.4 Fisher's Linear Discriminant
关于FLD : 将高维的样本投影到较少的维度,以达到抽取分类信息和压缩特征空间维数的效果。投影后保证样本在新的子空间有最大类间距离和最小类内距离,即样本点在该空间有最近可分离性。
利用下式将输入向量投影到一维空间:
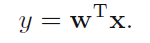
y>=w0时x归为C1类,y<w0时x归为C2类,这样就得到了如前所述的标准线性分类器。但注意到将多维输入变量投影到一维的过程中可能会损失很多信息,而之前说到过,w是决定决策面的方向,所以这就回到主题上来了,如何拟合w。
作者定义的几个量都不难理解,类内距,类间距,最后我们使用这几个建立起一个最大化目标:
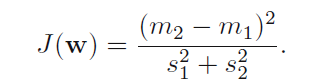
因为只在乎输入变量投影的方向,所以在舍弃掉一些标量后,得到了关于w方向的式子:
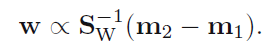
我们可以利用投影后的数据做一些分类工作,将会简单很多。
4.1.5 Relation to least squares
作者通过指定t1与t2的值,对least squares进行了一些推导得出了与fisher 判别相同的w方向,即说明了fisher是least square的一个特例。
4.1.6 Fisher‘s discriminat for multiple classes
这一节把Fisher判别扩展到了K类问题上,原理与4.1.4基本相同,不赘述了。
4.1.7 The perceptron algorithm
定义perceptron algorithm:
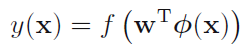
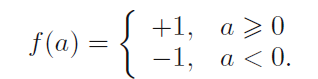
当y(x)=-1的时候,将x归为C2类,当y(x)=1的时候,将x归为C1类。
有了预测函数,下面该找error function了,注意到当tn=1的时候,我们希望a>0,而当tn=-1时,我们希望a<0,这样便发现,我们始终希望a*tn>0,对于那些分类错误的点,我们希望-a*tn越小越好,所以便得到了error function:
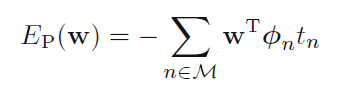
对error function使用随机梯度下降,得到:

作者用图4.7很好的对此处的梯度下降进行了几何解释。对于perceptron algorithm,如果数据线性可分,那么根据上面的方法w一定可以在有限步骤内收敛,假设数据线性可分,最后的解有多个,那么取到哪一个要根据参数的初始化和样本点的出现顺序而定了。perceptron的限制在于,它不能输出预测的概率值,也无法扩展到K>2类的问题中,最重要的是,它是基于固定的basis function的。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









