







Spark支持很多输入和输出源,同时还支持内建RDD。Spark本身是基于Hadoop的生态圈,它可以通过
Hadoop MapReduce所使用的InpoutFormat和OutputFormat接口访问数据。而且大部分的文件格式和存储系统
(HDFS,Hbase,S3等)都支持这种接口。Spark常见的数据源如下:
(1) 文件格式和文件系统,也就是我们经常用的TXT,JSON,CSV等這些文件格式
(2)SparkSQL中的结构化数据源
(3)数据库与键值存储(Hbase和JDBC源)
当然最简单的就是自己内部创建的RDD了,所以先从内部创建开始
RDD内部创建
对于spark内部创建,我们可以看看SparkContext这个类下面有什么函数用于创建RDD。发现有三个函数
parallelize、range和makeRDD。
(1)parallelize函数
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()/*判断是否是个有效的SparkContext*/
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}seq是一个序列,numSlices有一个默认值defaultParallelism,它的大小是有task决定,task在默认情况下又是core决定
实现:由一个ParallelCollectionRDD实现,现在来看看ParallelCollectionRDD这个类
private[spark] class ParallelCollectionRDD[T: ClassTag](
sc: SparkContext,
@transient private val data: Seq[T],
numSlices: Int,
locationPrefs: Map[Int, Seq[String]])
extends RDD[T](sc, Nil) {
// TODO: Right now, each split sends along its full data, even if later down the RDD chain it gets
// cached. It might be worthwhile to write the data to a file in the DFS and read it in the split
// instead.
// UPDATE: A parallel collection can be checkpointed to HDFS, which achieves this goal.
override def getPartitions: Array[Partition] = {
val slices = ParallelCollectionRDD.slice(data, numSlices).toArray
slices.indices.map(i => new ParallelCollectionPartition(id, i, slices(i))).toArray
}
override def compute(s: Partition, context: TaskContext): Iterator[T] = {
new InterruptibleIterator(context, s.asInstanceOf[ParallelCollectionPartition[T]].iterator)
}
override def getPreferredLocations(s: Partition): Seq[String] = {
locationPrefs.getOrElse(s.index, Nil)
}
}再来查看ParallelCollectionRDD.slice,源码如下:
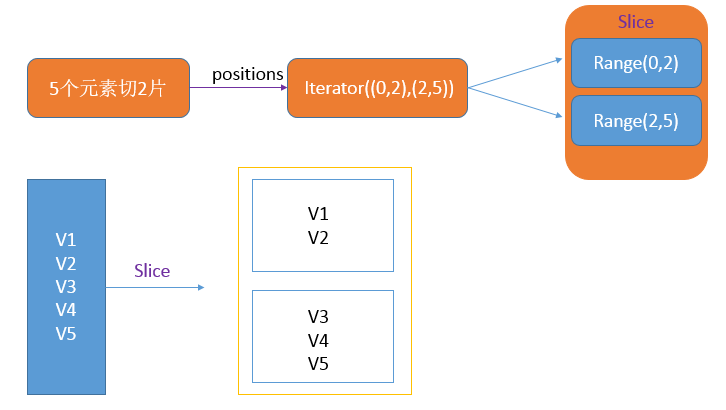
def slice[T: ClassTag](seq: Seq[T], numSlices: Int): Seq[Seq[T]] = { if (numSlices < 1) { throw new IllegalArgumentException("Positive number of slices required") } // Sequences need to be sliced at the same set of index positions for operations // like RDD.zip() to behave as expected def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = { (0 until numSlices).iterator.map(i => { val start = ((i * length) / numSlices).toInt val end = (((i + 1) * length) / numSlices).toInt (start, end) }) } seq match { case r: Range => { positions(r.length, numSlices).zipWithIndex.map({ case ((start, end), index) => // If the range is inclusive, use inclusive range for the last slice if (r.isInclusive && index == numSlices - 1) { new Range.Inclusive(r.start + start * r.step, r.end, r.step) } else { new Range(r.start + start * r.step, r.start + end * r.step, r.step) } }).toSeq.asInstanceOf[Seq[Seq[T]]] } case nr: NumericRange[_] => { // For ranges of Long, Double, BigInteger, etc val slices = new ArrayBuffer[Seq[T]](numSlices) var r = nr for ((start, end) <- positions(nr.length, numSlices)) { val sliceSize = end - start slices += r.take(sliceSize).asInstanceOf[Seq[T]] r = r.drop(sliceSize) } slices } case _ => { val array = seq.toArray // To prevent O(n^2) operations for List etc positions(array.length, numSlices).map({ case (start, end) => array.slice(start, end).toSeq }).toSeq } }下图是:五个元素,分两片流程:
(2)range函数
def range(
start: Long,
end: Long,
step: Long = 1,
numSlices: Int = defaultParallelism): RDD[Long] = withScope {
assertNotStopped()
// when step is 0, range will run infinitely
require(step != 0, "step cannot be 0")
val numElements: BigInt = {
val safeStart = BigInt(start)
val safeEnd = BigInt(end)
if ((safeEnd - safeStart) % step == 0 || (safeEnd > safeStart) != (step > 0)) {
(safeEnd - safeStart) / step
} else {
// the remainder has the same sign with range, could add 1 more
(safeEnd - safeStart) / step + 1
}
}
parallelize(0 until numSlices, numSlices).mapPartitionsWithIndex((i, _) => {
val partitionStart = (i * numElements) / numSlices * step + start
val partitionEnd = (((i + 1) * numElements) / numSlices) * step + start
def getSafeMargin(bi: BigInt): Long =
if (bi.isValidLong) {
bi.toLong
} else if (bi > 0) {
Long.MaxValue
} else {
Long.MinValue
}
val safePartitionStart = getSafeMargin(partitionStart)
val safePartitionEnd = getSafeMargin(partitionEnd)
new Iterator[Long] {
private[this] var number: Long = safePartitionStart
private[this] var overflow: Boolean = false
override def hasNext =
if (!overflow) {
if (step > 0) {
number < safePartitionEnd
} else {
number > safePartitionEnd
}
} else false
override def next() = {
val ret = number
number += step
if (number < ret ^ step < 0) {
// we have Long.MaxValue + Long.MaxValue < Long.MaxValue
// and Long.MinValue + Long.MinValue > Long.MinValue, so iff the step causes a step
// back, we are pretty sure that we have an overflow.
overflow = true
}
ret
}
}
})
}对于Range函数创建RDD,需要注意的是它的类型是Long
(3) makeRDD函数
/** Distribute a local Scala collection to form an RDD.
*
* This method is identical to `parallelize`.
*/
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
/** Distribute a local Scala collection to form an RDD, with one or more
* location preferences (hostnames of Spark nodes) for each object.
* Create a new partition for each collection item. */
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] = withScope {
assertNotStopped()
val indexToPrefs = seq.zipWithIndex.map(t => (t._2, t._1._2)).toMap
new ParallelCollectionRDD[T](this, seq.map(_._1), seq.size, indexToPrefs)
}输入不同: seq: Seq[(T, Seq[String])
输出不同:ParallelCollectionRDD[T](this, seq.map(_._1), seq.size, indexToPrefs)
上面的注释说明了:这个函数还可以提供在那个节点的信息
现在通过实验来比较各自的使用
package RDD import org.apache.spark.{SparkConf, SparkContext} /** * Created by legotime on 2016/5/6. */ object CreateRDD { def myfunc(index: Int, iter: Iterator[(Long)]) : Iterator[String] = { iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator } def myfunc1(index: Int, iter: Iterator[(String)]) : Iterator[String] = { iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator } def main(args: Array[String]) { val conf = new SparkConf().setAppName("CreateRDD").setMaster("local") val sc = new SparkContext(conf) //========================= 内部创建RDD=============================== //parallelize函数 val rdd1 = sc.parallelize(List("V1","V2","V3","V4","V5"),2) rdd1.mapPartitionsWithIndex(myfunc1).collect.foreach(println) //[partID:0, val: V1] //[partID:0, val: V2] //[partID:1, val: V3] //[partID:1, val: V4] //[partID:1, val: V5] //range函数 val rdd2 = sc.range(1L,9L,2L,3) rdd2.mapPartitionsWithIndex(myfunc).collect.foreach(println) //[partID:0, val: 1] //[partID:1, val: 3] //[partID:2, val: 5] //[partID:2, val: 7] //第一种makeRDD函数 val rdd3 = sc.makeRDD(List("V1","V2","V3","V4","V5"),2) rdd3.mapPartitionsWithIndex(myfunc1).collect.foreach(println) //[partID:0, val: V1] //[partID:0, val: V2] //[partID:1, val: V3] //[partID:1, val: V4] //[partID:1, val: V5] //第二种makeRDD函数 val info = List(("nameInfo", List("lego", "time")), ("contactInfo", List("467804502@qq.com", "467804502"))) val rdd4 = sc.makeRDD(info) for(i <- 0 to 1){ println(rdd4.preferredLocations(rdd4.partitions(i))) } //List(lego, time) //List(467804502@qq.com, 467804502) sc.stop() } }
RDD读取和保存















 254
254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









