





英文链接如下:
https://towardsdatascience.com/pca-using-python-scikit-learn-e653f8989e60
PCA最重要的应用之一是加速机器学习train。MNIST数据库更合适,因为它具有784个特征列(784个维度),60,000个示例的train集和10,000个示例的test集。
下载并加载数据
注:在国内会出现500错误,解决这个问题的链接如下
https://blog.csdn.net/lssc4205/article/details/81085511
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original')
你下载的图像包含在mnist.data中,其shape为(70000,784),这意味着有70,000个图像具有784个维度(784个特征)。
标签(整数0-9)包含在mnist.target中。这些特征是784维(28 x 28图像),标签只是0-9的数字。
将数据拆分为train和test集
通常,train / test分成80%的train和20%的test。在这种情况下,我选择6/7的数据进行train,1/7的数据进入test集。
from sklearn.model_selection import train_test_split
# test_size: what proportion of original data is used for test set
train_img, test_img, train_lbl, test_lbl = train_test_split( mnist.data, mnist.target, test_size=1/7.0, random_state=0)
标准化数据
本段中的文字几乎是前面所写内容的精确副本。PCA受比例影响,因此你需要在应用PCA之前缩放数据中的特征。你可以将数据转换为单位比例(均值= 0和方差= 1),这是许多机器学习算法的最佳性能要求。StandardScaler有助于标准化数据集的功能。请注意,你fit train集并转换train和test集。如果你希望看到不会缩放数据的负面影响,scikit-learn会有一节介绍不标准化数据的效果。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# Fit on training set only.
scaler.fit(train_img)
# Apply transform to both the training set and the test set.
train_img = scaler.transform(train_img)
test_img = scaler.transform(test_img)
导入并应用PCA
请注意,下面的代码的组件数参数为.95。这意味着scikit-learn选择最小数量的主成分,以保留95%的方差。
from sklearn.decomposition import PCA
# Make an instance of the Model
pca = PCA(.95)
在train集上fit PCA。注意:你仅需要在train集上fit PCA。
pca.fit(train_img)
注意:你可以使用pca.n_components_找出PCA在拟合模型后选择的组件数量 。在这种情况下,95%的方差相当于330个主成分。
将映射(变换)应用于train集和test集。
train_img = pca.transform(train_img)
test_img = pca.transform(test_img)
将Logistic回归应用于转换后的数据
**第1步:**导入要使用的模型
在sklearn中,所有机器学习模型都是作为Python类实现的
from sklearn.linear_model import LogisticRegression
第2步:创建模型的实例。
# all parameters not specified are set to their defaults
# default solver is incredibly slow which is why it was changed to 'lbfgs'
logisticRegr = LogisticRegression(solver = 'lbfgs')
**步骤3:**在数据上train模型,存储从数据中学习的信息
模型正在学习数字和标签之间的关系
logisticRegr.fit(train_img, train_lbl)
**第4步:**预测新数据的标签(新图像)
使用模型在模型train过程中学到的参数
下面的代码预测了一个测试结果
# Predict for One Observation (image)
logisticRegr.predict(test_img[0].reshape(1,-1))
下面的代码一次预测多个测试集合
# Predict for One Observation (image)
logisticRegr.predict(test_img[0:10])
测量模型性能
虽然准确性并不总是机器学习算法的最佳度量标准(精度,召回率,F1分数,ROC曲线等会更好),但为简单起见,此处使用它。
logisticRegr.score(test_img, test_lbl)
PCA后拟合Logistic回归的所花费的时间对比
本教程这一部分的重点是表明你可以使用PCA来加速机器学习算法的拟合。下表显示了在使用PCA后在我的MacBook上进行逻辑回归所需的时间(每次保留不同的方差)。
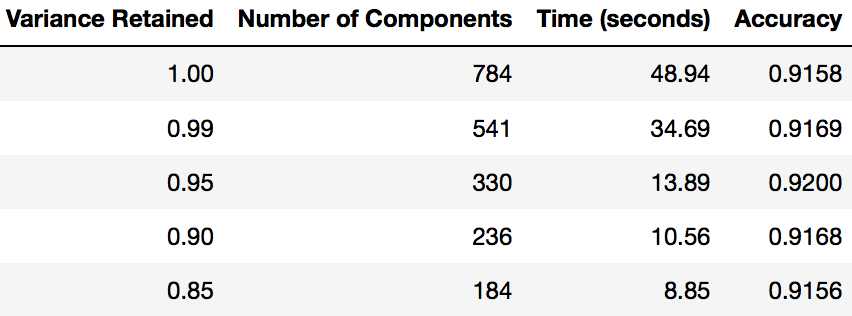
在具有不同保留方差分数的PCA之后进行逻辑回归的时间
压缩表示的图像重建
本教程的前面部分已经演示了如何使用PCA将高维数据压缩为较低维度的数据。我想简要提一下PCA还可以将数据的压缩表示(低维数据)恢复到原始高维数据的近似值。如果你对产生下图的代码感兴趣,请查看我的github。
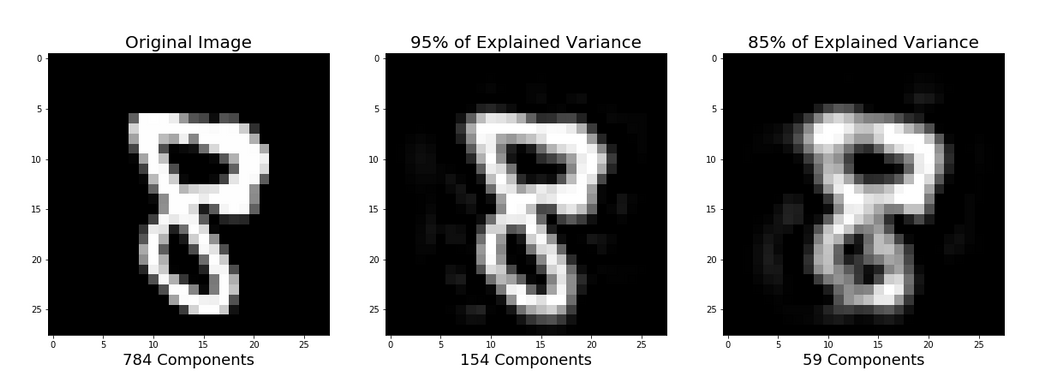
PCA后原始数据的原始图像(左)和近似值(右)














 3055
3055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









