







一、python请求要抓取的url页面
要抓取的url http://news.baidu.com/ ,先python模拟请求该url
#!/usr/bin/python
# -*- coding:utf-8 -*-
import httplib
class NewsBaidu(object):
def __init__(self):
super(NewsBaidu,self).__init__()
def request(self):
conn = httplib.HTTPConnection('news.baidu.com') #请求的host
request_url = '/' #请求的网页路径
body = '' #请求的参数
headers = {} #请求所带的头信息,该参数是一个字典
conn.request('GET',request_url,body,headers)
result = conn.getresponse()
print u'获取百度新闻'
print result.status
print result.reason
if __name__ == '__main__':
nb = NewsBaidu()
nb.request()运行效果

status =200 ,表示请求成功 ,result.read()
二、分析页面HTML
1、我们要抓取的内容,百度新闻左侧的列表的标题、href
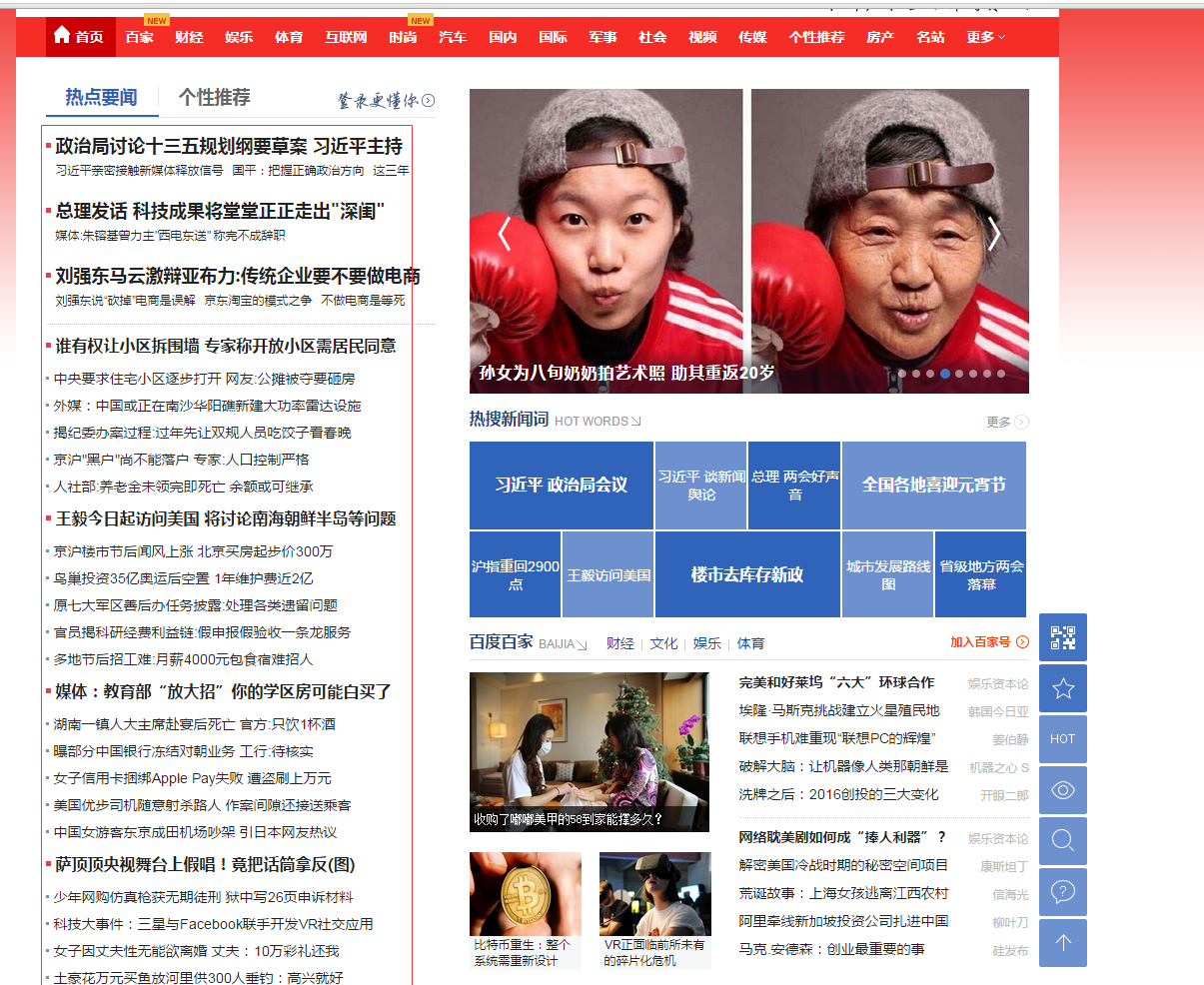
2、加载re模块,正则匹配出我们要的内容, 我们先看看HTML样式

这是我们要抓取的上面一部分页面HTML,我们可以看到 <a href="http://www.gov.cn/zhengce/2016-02/22/content_5044753.htm" target="_blank" class="a3" mon="ct=1&a=1&c=top&pn=1">总理发话 科技成果将堂堂正正走出"深闺"</a> ,包含我们想要的内容, 【总理发话 科技成果将堂堂正正走出"深闺"】 和href这部分的内容 【http://www.gov.cn/zhengce/2016-02/22/content_5044753.htm】 用正则提取出来
pattern = re.compile(r'<strong>.*?href="(.*?)" target="_blank" class="a3" mon="ct=1&a=1&c=top&pn=[0-9]+">(.*?)</a>.*?strong>',re.S)
下面一部分要抓取的HTML内容,我就不再分析,原理都一样。
三、源码
#!/usr/bin/python
# -*- coding:utf-8 -*-
import httplib
import urllib
import re
class NewsBaidu(object):
def __init__(self):
super(NewsBaidu,self).__init__()
self.f = open(u'百度新闻.txt','a')
def request(self):
try:
conn = httplib.HTTPConnection('news.baidu.com') #请求的host
request_url = '/' #请求的网页路径
body = '' #请求的参数
headers = {} #请求所带的头信息,该参数是一个字典
conn.request('GET',request_url,body,headers)
result = conn.getresponse()
print u'获取百度新闻'
print result.status
print result.reason
#print result.read()
if result.status == 200:
data = result.read()
self.main(data)
except Exception,e:
print e
finally:
conn.close()
self.f.close()
def main(self,data):
print u'获取中...'
pattern = re.compile(r'<strong>.*?href="(.*?)" target="_blank" class="a3" mon="ct=1&a=1&c=top&pn=[0-9]+">(.*?)</a>.*?strong>',re.S)
items = re.findall(pattern,data)
content = ''
for item in items:
content +=item[1].strip()+'\t'+item[0].strip()+'\t\n'
pattern = re.compile(r'<a href="(.*?)" target="_blank" mon="r=1">(.*?)</a>',re.S)
items = re.findall(pattern,data)
for item in items:
pattern = re.compile(r'^http://.*<a href="(.*)$',re.S) #url 对某些url再次正则获取
url = re.findall(pattern,item[0])
if url:
u = url[0]
else :
u = item[0]
content +=item[1].strip()+'\t'+u.strip()+'\t\n'
pattern = re.compile(r'<a href="(.*?)" mon="ct=1&a=2&c=top&pn=[0-9]+" target="_blank">(.*?)</a>',re.S)
items = re.findall(pattern,data)
del items[0]
for item in items:
content +=item[1].strip()+'\t'+item[0].strip()+'\t\n'
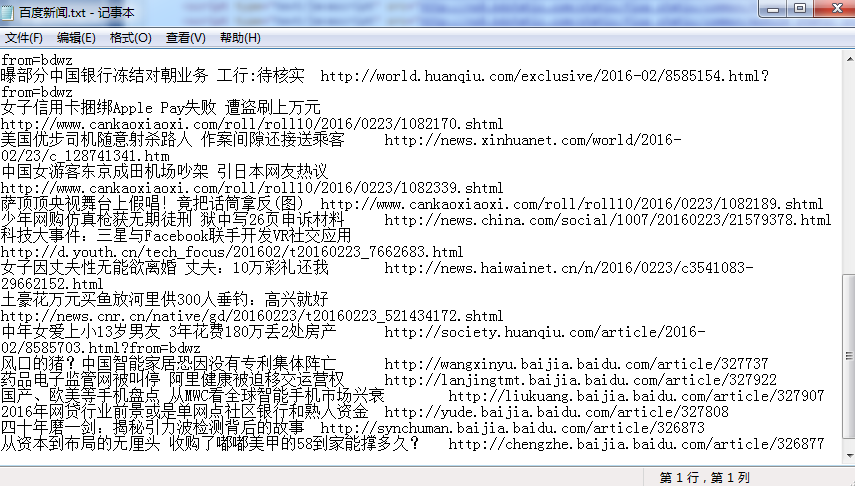
self.f.write(content)
print u'完成'
if __name__ == '__main__':
nb = NewsBaidu()
nb.request()















 3618
3618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









