






大家好,本文将围绕python爬取百度新闻数据展开说明,python爬取新闻网站内容是一个很多人都想弄明白的事情,想搞清楚python爬取文章内容需要先了解以下几个事情。
Python爬取新闻信息,分词统计并画词云
中国新闻网,是知名的中文新闻门户网站,也是全球互联网中文新闻资讯最重要的原创内容供应商之一。依托中新社遍布全球的采编网络,每天24小时面向广大网民和网络媒体,快速、准确地提供文字、图片、视频等多样化的资讯服务仿写文章软件。
分析页面内容:首先,打开中国新闻网的页面可以看到,导航栏里已经有很多的分类标签选项。但是,可以跳转的标签并不全是按照新闻的内容进行分类的。
例如,标签中的“金融”、“汽车”和“体育”是按照内容划分,但是“国际”、“港澳”和“台湾”是按照新闻的来源地划分的。这样的划分内容并不统一。
为了将新闻按照内容分类,需要将实时发布的新闻内容提取出来,按照文本语义信息进行统一的划分。
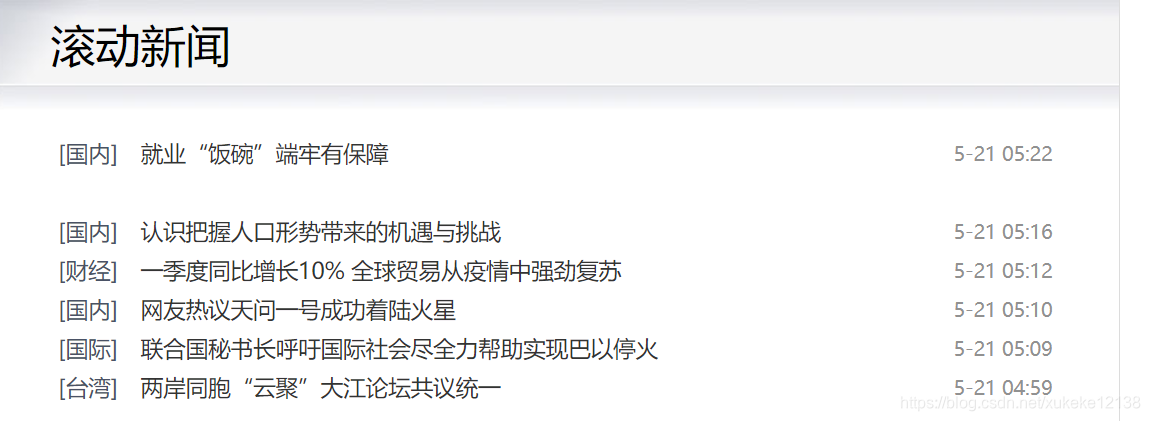
这里,发现在中国新闻网的滚动新闻栏目中,可以看到实时发布的最新新闻汇总。并且可以在网页中获取到实时发布的新闻分类标签和新闻标题。点击链接之后,可以跳转到相应的详情页面,从而获取到更详细的内容文本。
例如:
分析网页源码:在滚动新闻页面源码中可以看到headers的内容。将它作为请求的请求头添加进爬虫中,可以模拟浏览器访问网站。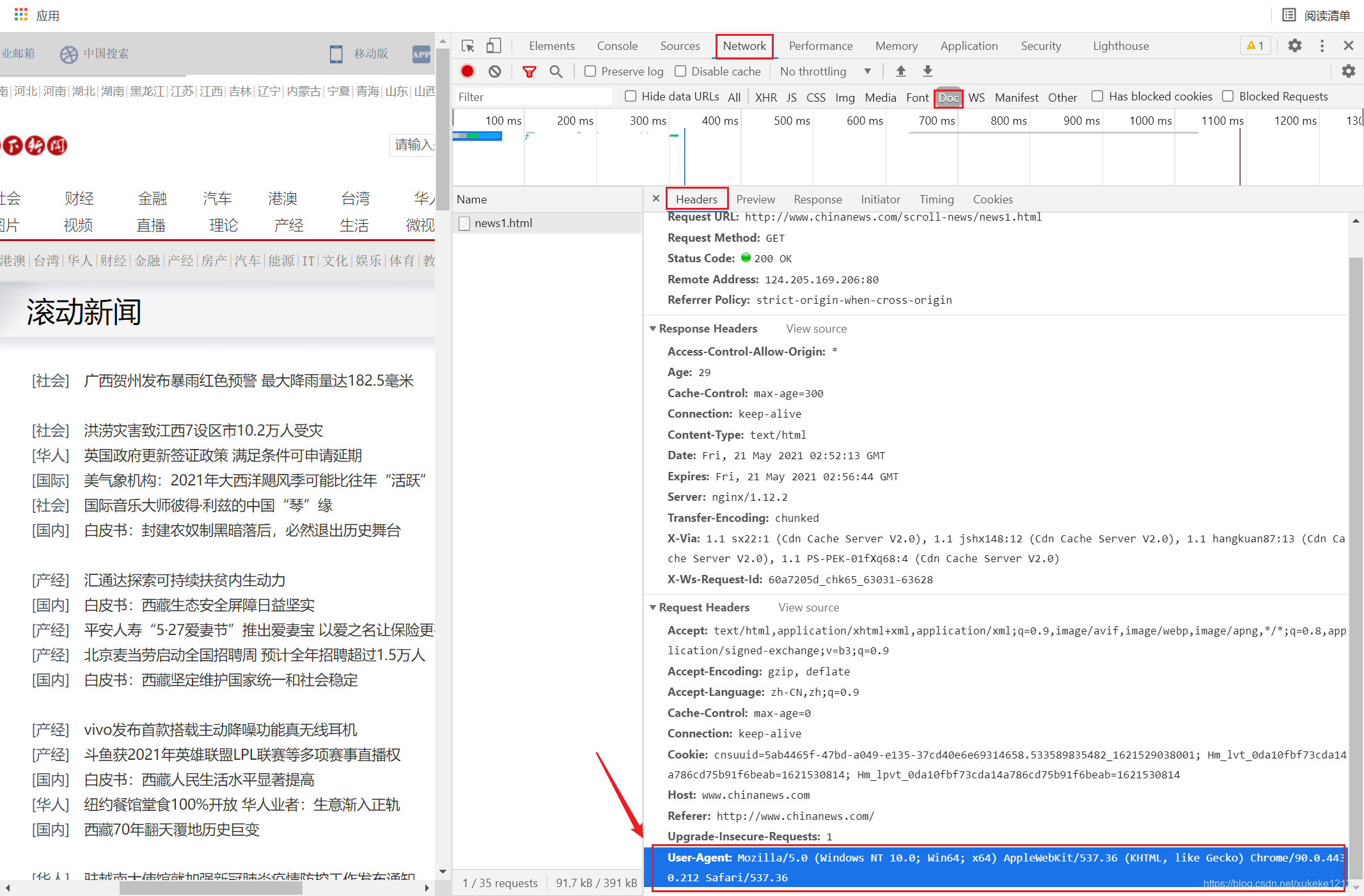
在终端打印出获取到的网页源码。可以看到,新闻的题目和标签可以从源码中得到。
但是这一步得到的resp还是一个字符串,为了方便对网页内容进行解析,需要将字符串转换为网页结构化数据,方便地查找HTML标签以及其中的属性和内容。
观察到网页的HTML结构,并将上一步得到的HTML格式字符串转换为一个BeautifulSoup对象。这样就可以通过标签找到对应的内容。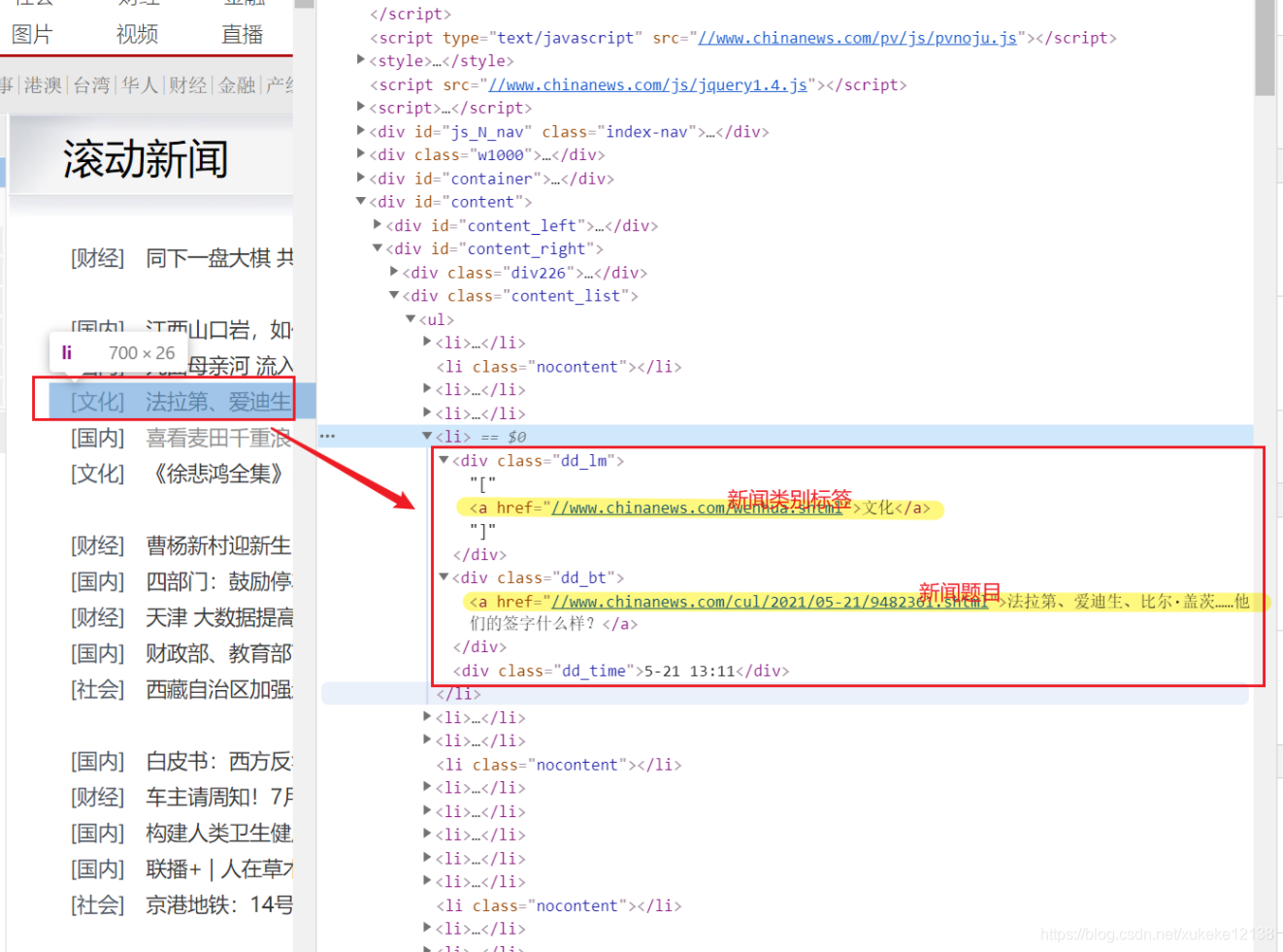
信息筛选和存储:接下来要将网页中我们需要的内容筛选出来。
注意到信息在网页中是按照类名、标题和时间,三个板块去展示的,存取的内容也分为这三部分。
使用 正则表达式 对获取到的字符串进行匹配。我们可以得到一个
将得到的信息放入到文本中。
滚动页面可以翻页,爬取一共10页的信息将会得到1250条新闻信息。将这些新闻信息放在字典里,存入excel表格。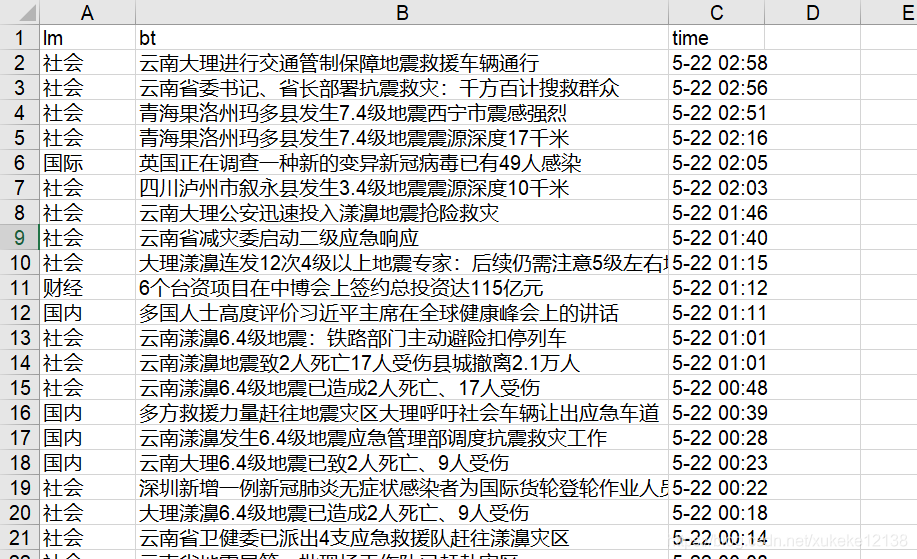
注意到不同的新闻类别会有不同的数量,我们将爬取到的不同内容的新闻的标签统计如下: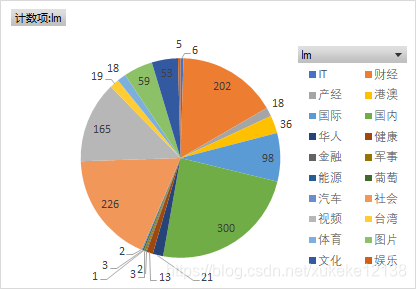
可以看到,其中“国内”、“财经”和“社会”为主体的新闻发表的次数最多。还有很多内容发表的次数非常少,如“IT”、“军事”。
同时,将所有新闻标题的内容进行整合。用jieba库进行分词,用wordcloud库绘制出词云展示图:
可以看到,“中国”一词在新闻标题中出现的次数最多,其次还有“国际”、“发展”等等。
import requests
from bs4 import BeautifulSoup
import re
import xlwt
import jieba
import wordcloud
def req():
url_head = "http://www.chinanews.com/scroll-news/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"
}
all_news = []
news_list = [[] for i in range(20)]
id2tp = { }
id = {}
cnt = 0
txt = " "
for i in range(10):
url = url_head + "news" + str(i+1) + ".html"
resp = requests.get(url=url, headers=headers)
resp = resp.content.decode('utf-8', 'ignore') # 不加第二个参数ignore会报错 忽略掉一些utf编码范围外的不知名字符
#print(resp)
soup = BeautifulSoup(resp, 'html.parser')
news = soup.select('body #content #content_right .content_list ul li')
#print(news)
for new in news:
new = new.text
if new == '':
continue
ti = re.compile("[0-9][0-9]:[0-9][0-9]")
date = re.compile("[0-9]{1,2}\-[0-9]{1,2}")
#print(new)
time = new[-10:]
new = ti.sub('', new)
new = date.sub('', new)
lm = new[1:3]
if len(lm.strip()) == 1:
lm = "IT"
bt = new.split(']')[1].replace(' ', '')
txt = txt + " " + bt
if lm not in id.keys():
id[lm] = cnt
id2tp[cnt] = lm
cnt += 1
all_news.append({
"lm": lm,
"bt": bt,
"time": time
})
print(len(all_news))
print(id)
#print(id2tp)
workbook = xlwt.Workbook() #注意Workbook的开头W要大写
sheet1 = workbook.add_sheet('sheet1',cell_overwrite_ok=True)
sheet1.write(0, 0, "lm")
sheet1.write(0, 2, "bt")
sheet1.write(0, 4, "time")
for idx, dictionary in enumerate(all_news):
news_list[id[dictionary["lm"]]].append(dictionary["bt"])
sheet1.write(idx + 1, 0, dictionary["lm"])
sheet1.write(idx + 1, 2, dictionary["bt"])
sheet1.write(idx + 1, 4, dictionary["time"])
workbook.save('news.xls')
for i in range(13):
print(id2tp[i], len(news_list[i]))
w=wordcloud.WordCloud(width=1000, font_path='chinese.ttf', height=700, background_color='white')
lis = jieba.lcut(txt)
# 人为设置一些停用词
string = " ".join(lis).replace('的', '').replace('在', '').replace('为', '').replace('是', '').replace('有', '').replace('和', '')
print(string)
w.generate(string)
w.to_file("news.png")
if __name__ == "__main__":
req()
# test()















 812
812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









