






1 introduction
已有许多工作从视频序列中估计2D关键点,再通过2D关键点估计3D关键点。作者提到,将这两个任务分开在理论上可以降低问题的复杂度,但是事实却是:这两个任务是模棱两可的(2D序列可以映射到3D序列)。为了解决这个问题,有研究者利用时序模型RCNN来解决这个问题。
本文的工作:
① 提出了一个可以适配任何视频序列→2D序列模型的2D序列→3D序列模型,利用的是一个空洞卷积网络。它在同等精度的情况下比现有的RCNN方法更加的高效。

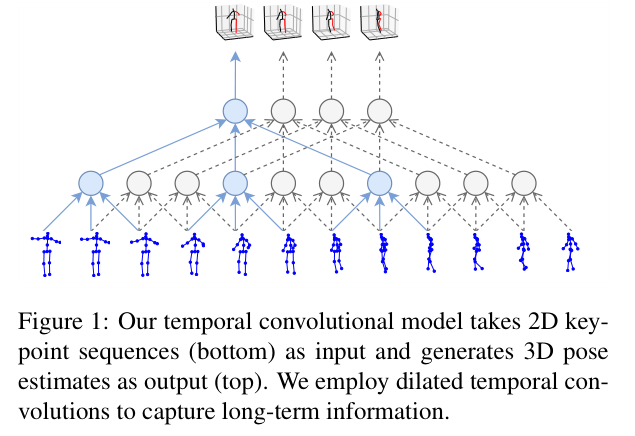
② 为了应对数据量少的问题,文章还提出了一种半监督训练的方案,利用现有的方法从视频序列→2D序列,再2D序列→3D,最后再映射回2D。

2 Related work
① Two-step pose estimation:先从图片→2D,再从2D→3D,受益于中间监督,其效果优于端到端;
② Video pose estimation:从关注单帧到关注视频序列,关注时序信息。也有seq2seq的方式(2D→3D);
③ Semi-supervised training:GAN与基于序数深度的弱监督方法;
④ 3D shape recovery:文章探讨的是3D关键点重建,也有部分工作关注的是3D形状的重建;
⑤ Our work:采用关键点而不是热图,从而可以采用一维卷积。文章发现采用Mask R-CNN和CPN作为2D预测的监测器,相比stacked hourglass更具有鲁棒性。
3 Temporal dilated convolutional model
3.1 优势
① 采用时序卷积可以在时序维度进行并行计算,而RCNN没有办法做到;
② 在输入和输出路径之间有固定长度的梯度,不会出现RCNN中出现的梯度消失或者梯度爆炸的问题;
③ 卷积结构对时间感受野有着精确的控制,这有利于3D姿态预测模型的时间依赖性;
④ 采用空洞卷积来建模长时间依赖性
3.2 网络结构
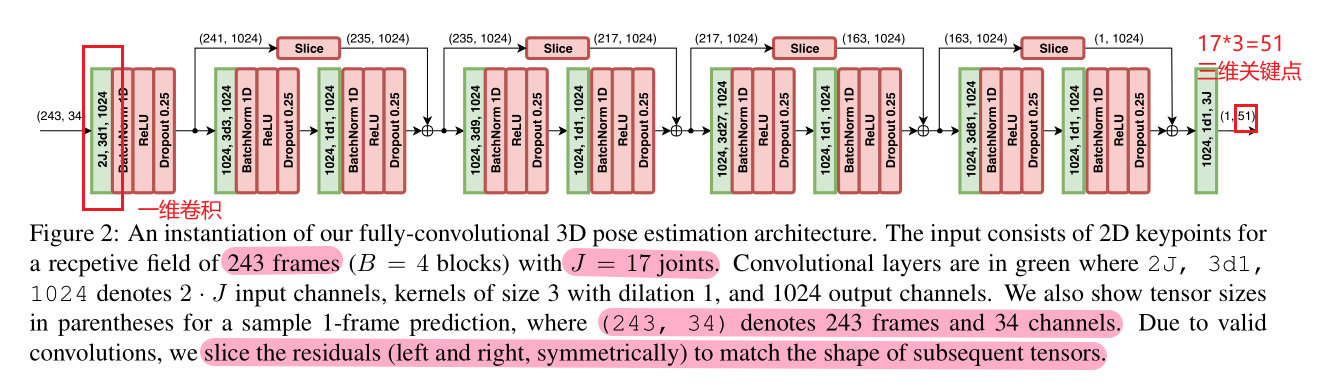
卷积都采用一维卷积,在时序上单独对每一个关节点进行一维卷积。卷积中经常采用0填充来保持输入输出大小不变,而在本文中并不采用(文章采用复制前后关节数据或者不填充的策略)。
4 Semi-supervised approach
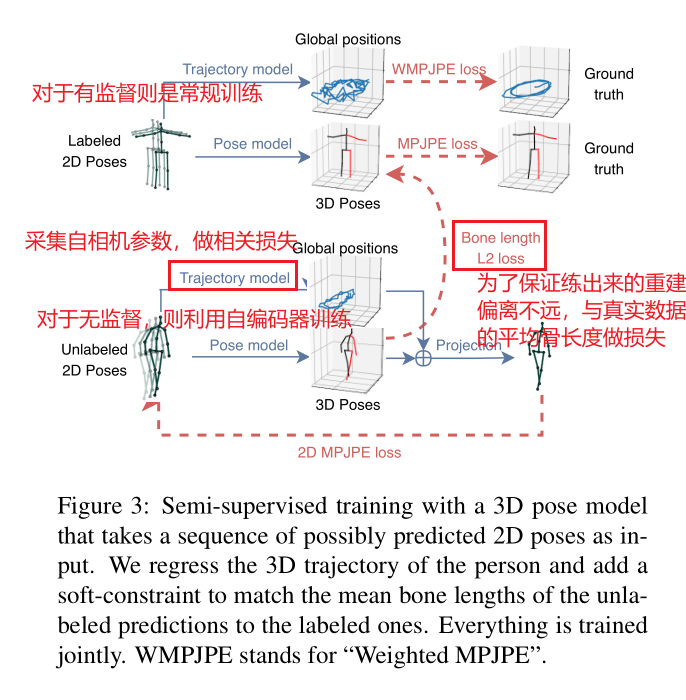
Trajectory model:由于透视投影,屏幕上的2D姿势取决于轨迹(即,在每个时间步长处空间中人体的相对位置)和3D姿势(人体的相对关节位置)。因此我们回归人体的3D轨迹,使得可以正确的反向传播到2D。
有监督训练中,同时训练Trajectory model;无监督训练中,用与增强预测效果。
向下两个网络具有相同的网络结构,但是不共享参数。由于视频序列中行人越走越远,进行改进了损失函数:


















 3488
3488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









