







 本文介绍了稀疏注意力机制,一种在深度学习中用于减少Transformer模型时间和空间复杂度的优化方法。它与单头注意力和多头注意力相比,通过选择性计算提高了效率,特别是在处理长序列时。文章还比较了与FlashAttention的区别,强调了两者在优化计算过程和内存使用上的不同策略。
本文介绍了稀疏注意力机制,一种在深度学习中用于减少Transformer模型时间和空间复杂度的优化方法。它与单头注意力和多头注意力相比,通过选择性计算提高了效率,特别是在处理长序列时。文章还比较了与FlashAttention的区别,强调了两者在优化计算过程和内存使用上的不同策略。
稀疏注意力
一、稀疏注意力的特点
DeepSpeed有很多不错的功能:Training Overview and Features - DeepSpeed
其中有一个功能是注意力稀疏,我们重点展开说明。
需要注意的是:稀疏注意力的实现并不仅限于DeepSpeed。虽然DeepSpeed提供了一种高效的稀疏注意力实现,但其他深度学习框架和库也可能提供稀疏注意力的支持。例如,Hugging Face的Transformers库就包含了一些稀疏注意力的实现,如Longformer和BigBird。
1. 单头注意力(Single-Head Attention)
单头注意力(Single-Head Attention)是一种注意力机制,它可以将一个查询向量(Query)和一组键值对(Key-Value)映射到一个输出向量,其中输出向量是值向量(Value)的加权和,而权重是由查询向量和键向量(Key)的相似度计算得到的。单头注意力的概念最早出现在2014年的论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,该论文提出了一种基于编码器-解码器(Encoder-Decoder)的神经机器翻译模型,其中使用了单头注意力来捕捉输入序列和输出序列之间的对齐关系。
2. 多头注意力(Multi-Head Attention)
多头注意力(Multi-Head Attention)是一种改进的注意力机制,它可以将一个查询向量和一组键值对映射到一个输出向量,但与单头注意力不同的是,它会将查询向量、键向量和值向量分别投影到多个子空间中,然后在每个子空间中分别计算注意力。最后将所有子空间的注意力输出拼接起来得到最终的输出向量。多头注意力的概念最早出现在2017年论文《Attention Is All You Need》中,该论文提出了一种基于自注意力(Self Attention)的序列到序列(Seq2Seq)模型,称为Transformer,其中使用了多头注意力来增强模型的表达能力和关注不同位置的信息的能力。
3. 稀疏注意力(Sparse Attention)
稀疏注意力(Sparse Attention)是一种优化的注意力机制,它可以将一个查询向量和一组键值对映射到一个输出向量,但与单头注意力和多头注意力不同的是,它不会计算查询向量和所有键向量的相似度,而是只计算查询向量和部分键向量的相似度,从而减少计算量和内存消耗。稀疏注意力的概念最早出现在2018年的论文《Generating Long Sequences with Sparse Transformers》中,该论文提出了一种基于Transformer的长序列生成模型,其中使用了稀疏注意力来处理超过8000个单词的文本序列。
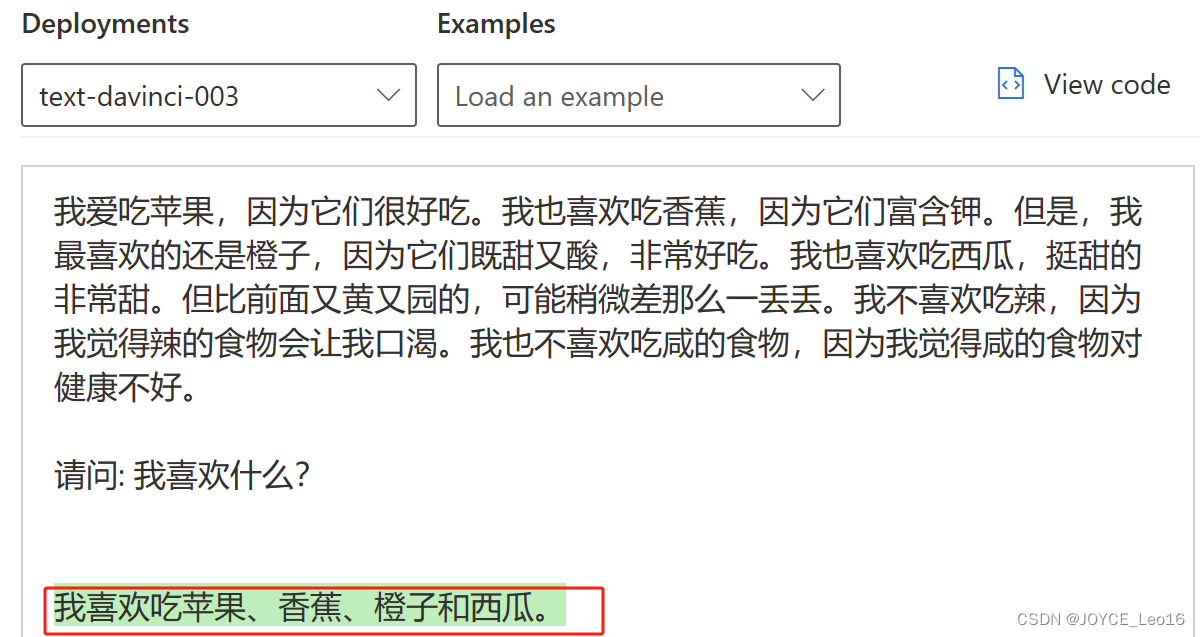
我们假设一个伪代码的例子说明:
针对一段文本:
我爱吃苹果,因为它们很好吃。我也喜欢吃香蕉,因为它们富含钾。但是,我最喜欢的还是橙子,因为它们既甜又酸,非常好吃。我也喜欢吃西瓜,挺甜的非常甜。但比前面又黄又园的,可能稍微差那么一丢丢。我不喜欢吃辣,因为我觉得辣的食物会让我口渴。我也不喜欢吃咸的食物,因为我觉得咸的食物对健康不好。
问题:我喜欢什么?
- 单头注意力:在单头注意力中,我们可能只关注"我"最近的一个动词或名词。例如,我们可能会回答:“你喜欢吃西瓜。” 这是因为"我"和"西瓜"在句子中是相邻的,所以我们只关注了这个最近的上下文。
- 多头注意力:在多头注意力中,我们会关注"我"的所有上下文。例如,我们可能会回答:“你喜欢吃苹果,吃香蕉,吃橙子和吃西瓜。” 这是因为我们同时关注了"我"和"苹果"、“香蕉”、“橙子”、"西瓜"这些词,所以我们能够提供一个更全面的回答。
- 稀疏注意力:在稀疏注意力中,我们可能只关注"我"和一些特定的、重要的上下文。例如,我们可能会回答:“你喜欢吃橙子和吃西瓜,但是你不喜欢吃辣的和咸的食物。” 这是因为我们认为"喜欢"和"不喜欢"是重要的修饰词,所以我们只关注了"我"和"喜欢"、“橙子”、“西瓜”、“不喜欢”、"辣的"和"咸的"这些词。
接下来验证一下text-davinci-003和ChatGPT:
text-davinci-003:
ChatGPT4:
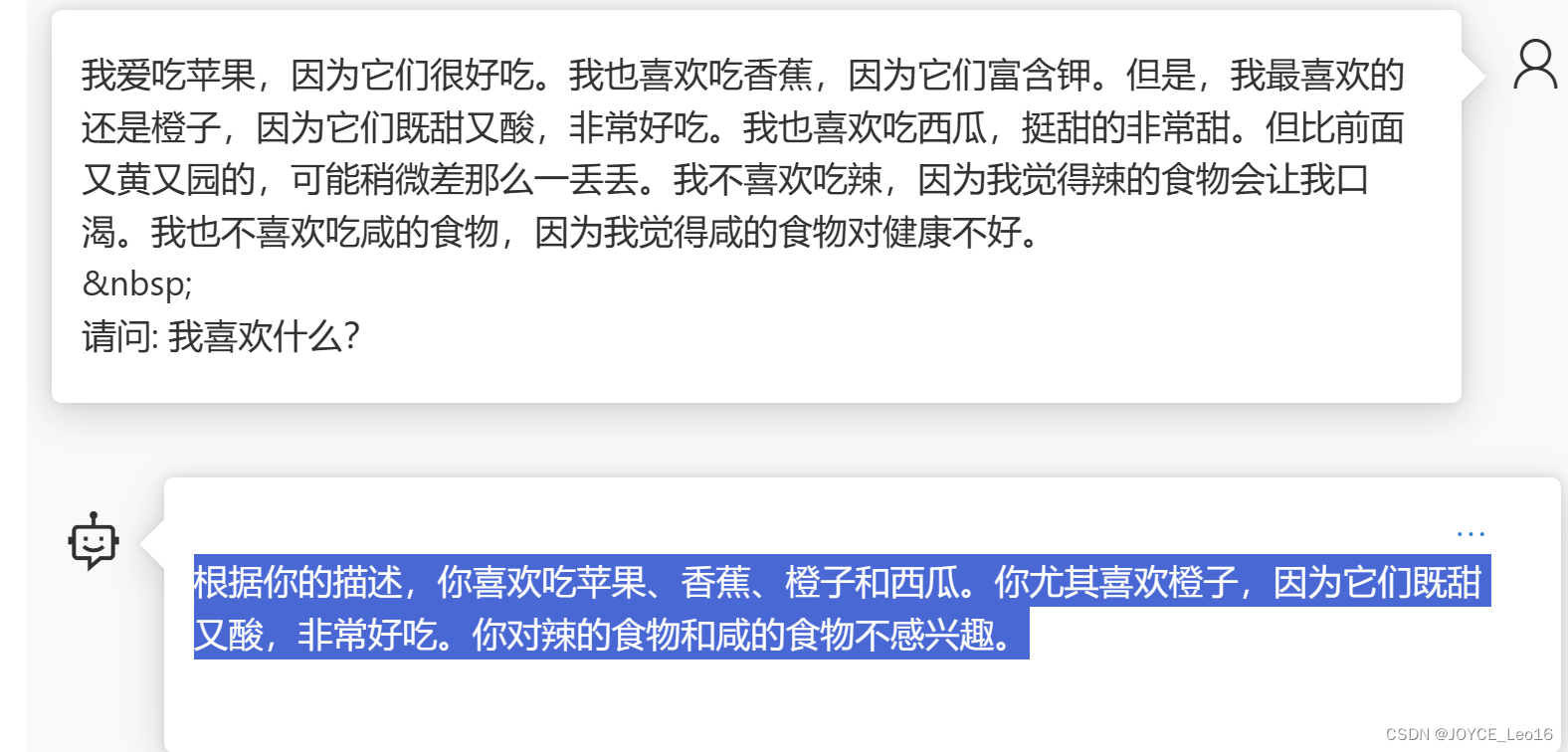
可以确定的是chatgpt4使用了多头注意力。
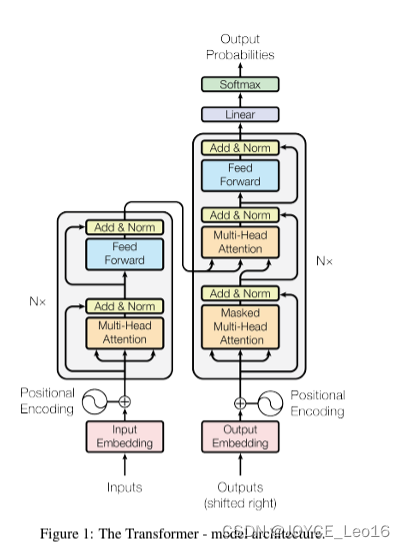
二、稀疏注意力的示意图
“稀疏注意力”是一种与传统注意力机制不同的技术,它只关注序列中的部分元素以提高处理速度。相对的技术是“全注意力”,它会考虑序列中每个元素与其他元素之间的关系,尽管这在处理长序列时会非常耗时。稀疏注意力采用各种方式实现,如固定模式、可学习的模式或基于启发式规则,这降低了计算资源需求。Transformer模型虽然擅长处理长序列,但计算和存储需求会随着序列长度的增加而急剧下降,显著减少了计算和存储需求。调整参数w可在计算效率和模型性能之间找到平衡,使处理长序列更可行。
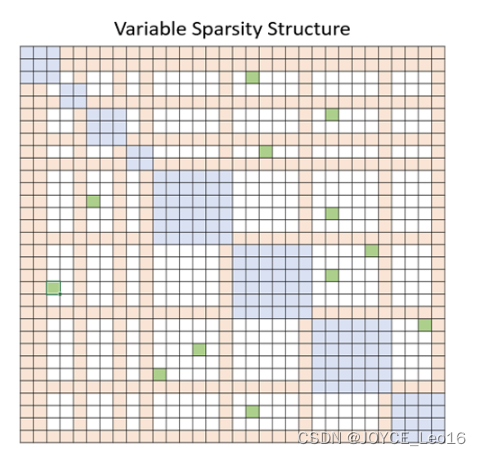
这张图是DeepSpeed使用的变量稀疏结构的视觉表示。图中的网格和单元格分别代表序列和序列中的元素。蓝色的单元格表示正在计算的元素,绿色的单元格表示未被计算的元素。
传统的深度学习模型需要计算序列中所有部分之间的关系,这需要大量的内存。然而,DeepSpeed引入的稀疏注意力(SA)技术改变了这一点。SA只计算序列中某些部分之间的关系,从而大大减少了计算和存储需求。
稀疏性的程度由参数w控制,w是一个比1大但比序列长度n小的数。通过调整w的值,我们可以在计算效率和模型性能之间找到一个平衡。
这张图直观地展示了稀疏性。蓝色的单元格就是被计算的元素,也就是被注意力机制关注的部分。绿色的单元格则是被忽略的部分,也就是没有被注意力机制关注的部分。通过调整w的值,我们可以控制被计算的元素的数量,从而在计算效率和模型性能之间找到一个平衡。
在稀疏注意力机制中,我们并不需要计算所有元素之间的关系,而只需要计算部分元素之间的关系。这样,我们只关注和计算那些对模型性能影响较大的元素之间的关系,而忽略那些影响较小的元素。
图中的蓝色单元格代表了被计算的元素,也就是被注意力机制关注的部分。这体现了稀疏注意力机制的一个重要特点,即选择性关注。图中的绿色单元格代表了未被计算的元素,也就是没有被注意力机制关注的部分。这体现了稀疏注意力机制的另一个重要特点,即稀疏性。通过调整参数w的值,我们可以控制被计算的元素的数量,从而在计算效率和模型性能之间找到一个平衡。这个特点在图中并没有直接体现,但是通过理解蓝色和绿色单元格的含义,我们可以推断出这一点。
总结起来就是:
- 选择性关注:在稀疏注意力机制中,我们并不需要计算所有元素之间的关系,而只需要计算部分元素之间的关系。这样,我们只关注和计算那些对模型性能影响较大的元素之间的关系,而忽略那些影响较小的元素。蓝色的单元格在图中代表了被计算的元素,也就是被注意力机制关注的部分,体现了这种选择性关注。
- 稀疏性:稀疏性是稀疏注意力机制的另一个重要特点。通过忽略那些对模型性能影响较小的元素,我们可以大大降低计算复杂度和存储需求。在图中,绿色的单元格代表了未被计算的元素,也就是没有被注意力机制关注的部分,体现了这种稀疏性。
- 可调节性:稀疏注意力机制的一个重要优势是其可调节性。通过调整参数w的值,我们可以控制被计算的元素的数量,从而在计算效率和模型性能之间找到一个平衡。这个特点在图中并没有直接体现,但是通过理解蓝色和绿色单元格的含义,我们可以推断出这一点。
稀疏注意力是一种基于PyTorch的库,用于优化深度学习模型的训练过程,主要目标是减少传统Transformer的时间复杂度和空间复杂度。通过top-k选择,将注意力退化为稀疏注意力,保留最有助于引起注意的部分,并删除其他无关的信息。这种方法有效地保存了重要信息并消除了噪声。
这个库确实是通过Triton平台来开发和优化其所需的计算内核的。Triton是一个开源项目,为在GPU上高效执行自定义操作提供了方法。这个库的内核没有用CUDA编写,这意味着未来可能支持CPU、OpenCL或Vulkan。
这个库作为DeepSpeed的一个扩展,既可以通过DeepSpeed使用,也可以单独使用。在处理稀疏注意力内核时,DeepSpeed采用了块稀疏计算。
在训练阶段,可以使用稀疏注意力来优化模型。稀疏注意力通过减少注意力机制中需要计算的元素数量来提高训练效率。具体来说,稀疏注意力只关注与给定元素最相关的一部分其他元素,而不是所有元素。这可以大大减少计算量,从而提高训练速度。
在推理阶段,仍然可以使用稀疏注意力。实际上,稀疏注意力在推理阶段可能更加有用,因为它可以帮助模型更快地生成预测。由于稀疏注意力减少了需要计算的元素数量,所以它可以使模型在处理新的输入数据时更快地生成预测。
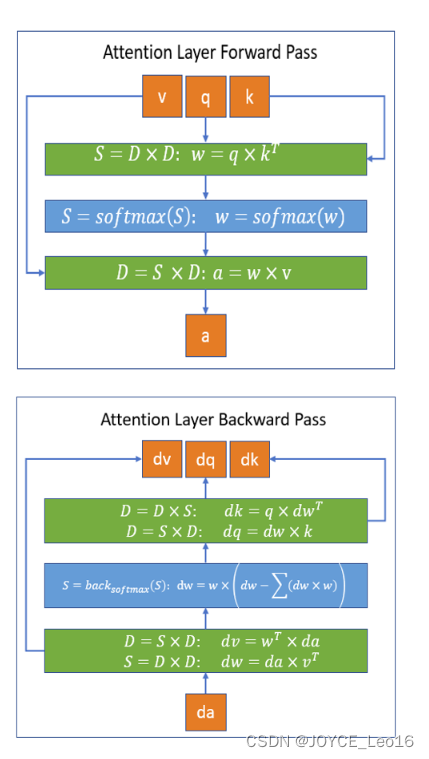
三、与Flash Attention的区别
(ColossalAI就使用了Flash Attention)
稀疏注意力:
- 稀疏注意力通过选择性地处理信息来减少计算量。具体来说,它从一个序列中计算经过选择的相似性得分,而不是所有可能的Pair,从而产生一个稀疏矩阵而不是一个完整的矩阵。
- 稀疏注意力机制的主要目的是减少传统Transformer的时间复杂度和空间复杂度。
Flash Attention:
- Flash Attention的主要目的是加速和节省内存。它的主要贡献包括:计算softmax时候不需要全量input数据,可以分段计算;反向传播的时候,不存储attention matrix (N^2的矩阵),而是只存储softmax归一化的系数。
- Flash Attention将输入分割成块,并在输入块上进行多次传递,从而以增量方式执行softmax缩减。
- 在Flash Attention的前向计算算法中,Flash Attention算法并没有将S、P写入HBM中去,而是通过分块写入到HBM中去,存储前向传递的 softmax 归一化因子,在后向传播中快速重新计算片上注意力。
总的来说,稀疏注意力和Flash Attention都是为了优化注意力机制的计算效率,但稀疏注意力更侧重于选择性地处理信息,而Flash Attention则更侧重于优化计算过程和内存使用。
总结
Deepspeed稀疏注意力启用的代码实现:
DeepSpeed Sparse Attention - DeepSpeed
来源:大魏分享


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











